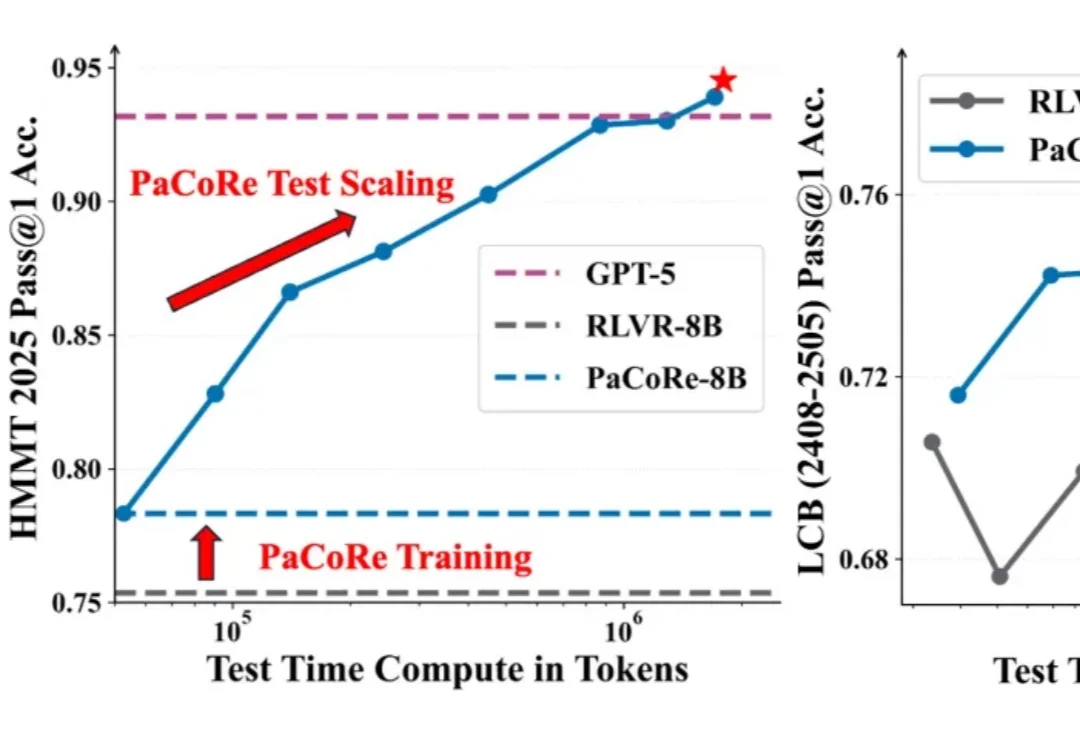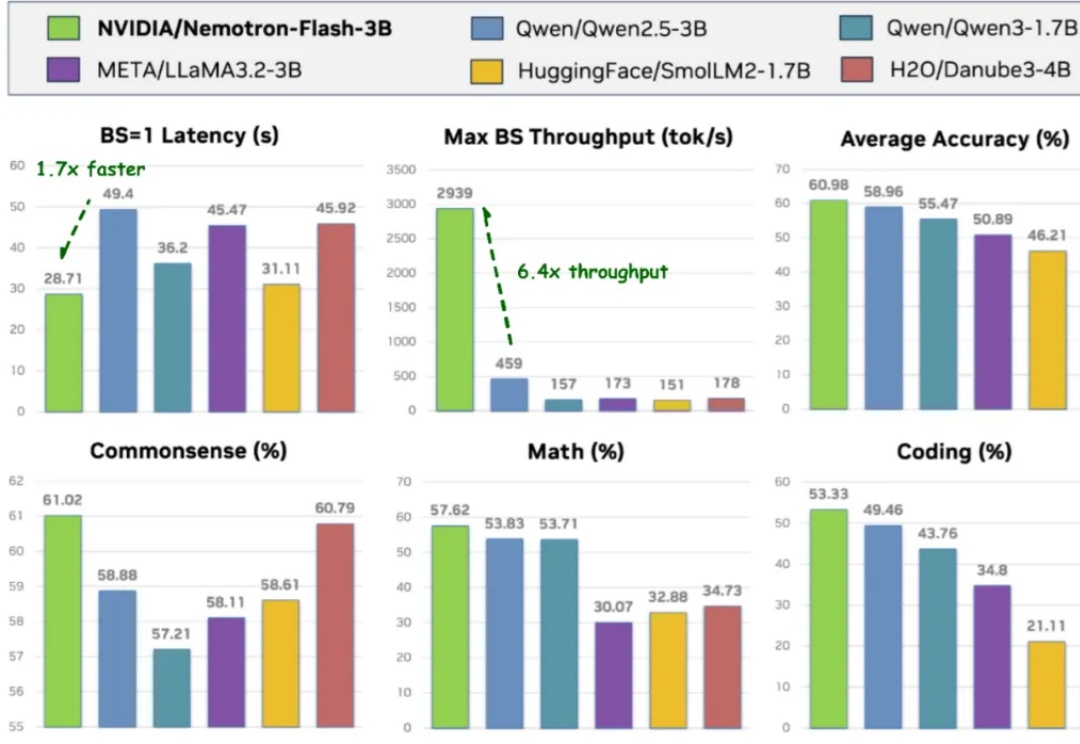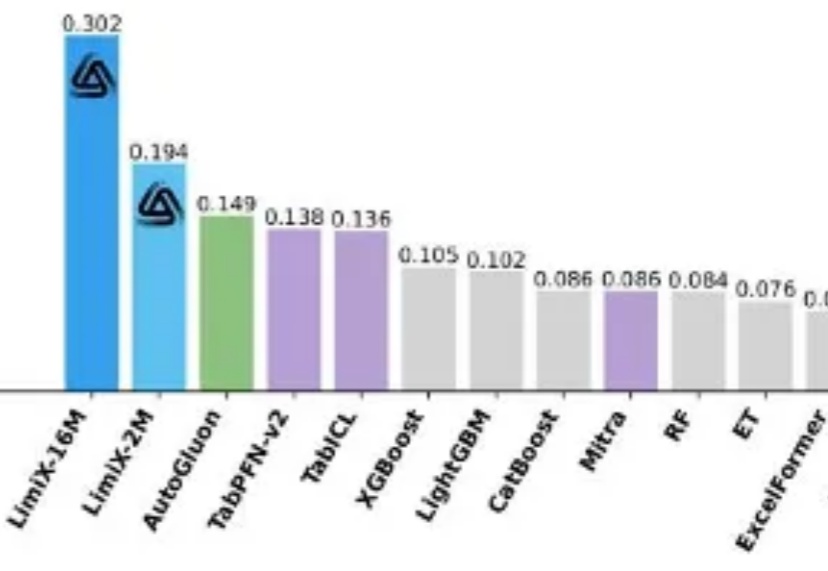
独家 | 清华00后博士融资数千万,打造全球现象级端侧算力引擎,性能领跑行业
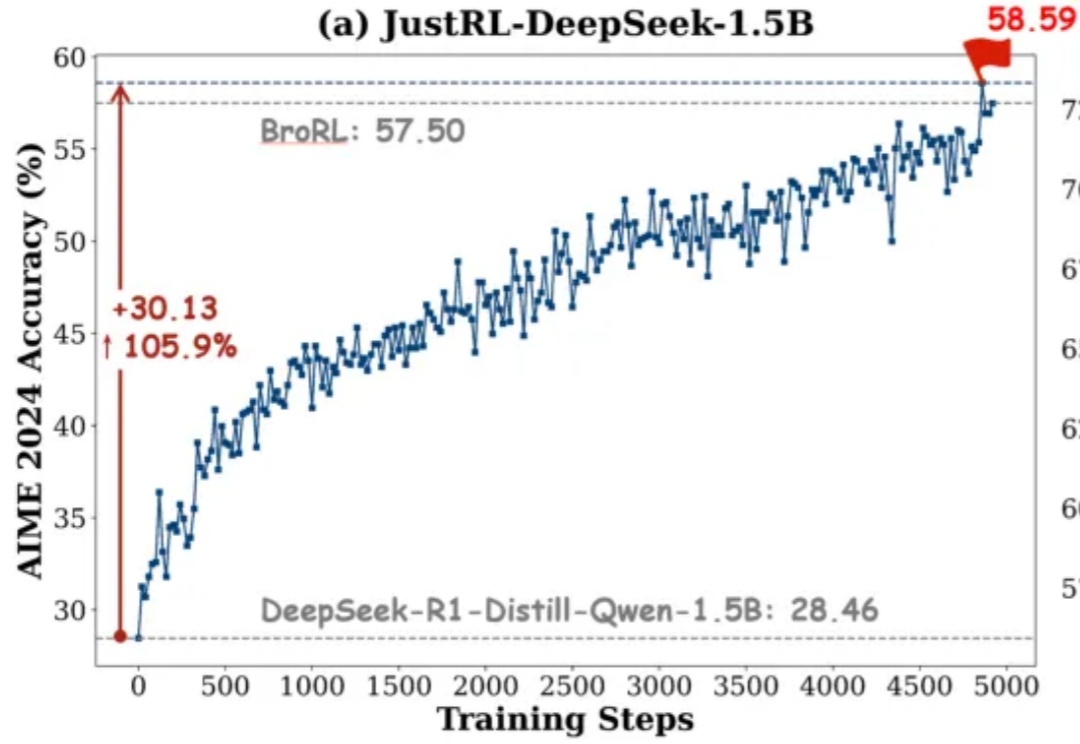
独家 | 清华00后博士融资数千万,打造全球现象级端侧算力引擎,性能领跑行业。过去的行业共识是:端侧只能跑小模型,性能与体验必须妥协;真正的能力仍得依赖云端最强模型。万格智元要打破的,正是这条旧认知。公司正在打造的cPilot端侧算力引擎,选择了一条更难、却更接近未来的路径:通过自研的非GPU推理引擎,让300亿、500亿等超大模型在性能有限制的消费硬件上高效推理
来自主题: AI资讯
11519 点击 2025-12-26 15:49