ICLR 2026 | 7B小模型干翻GPT-5?AdaResoner实现Agentic Vision的主动「视觉工具思考」
ICLR 2026 | 7B小模型干翻GPT-5?AdaResoner实现Agentic Vision的主动「视觉工具思考」你见过 7B 模型在拼图推理上干翻 GPT-5 吗?
来自主题: AI技术研报
7185 点击 2026-03-04 11:18
 搜索
搜索
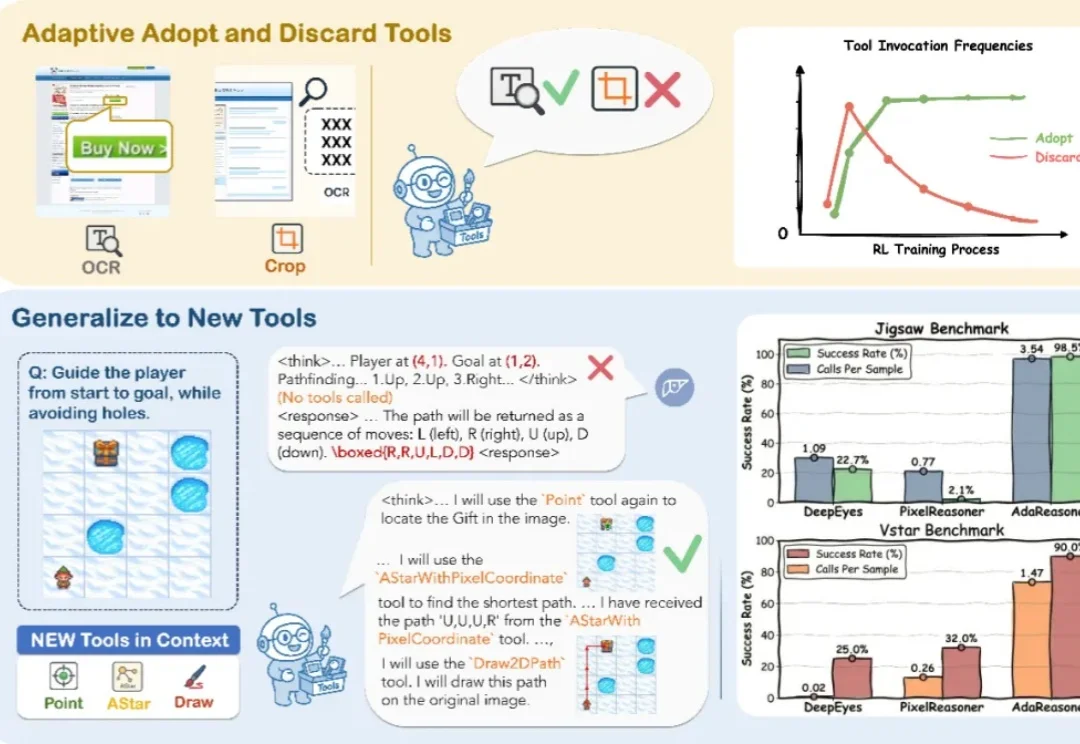
你见过 7B 模型在拼图推理上干翻 GPT-5 吗?

昨天深夜,阿里通义千问团队在 X 平台正式发布了 Qwen3.5 小模型系列,覆盖 0.8B、2B、4B 和 9B 四个参数规格。甫一发布,便在海外科技圈引发强烈反响。马斯克也在该推文下评论称:「Impressive intelligence density」(令人印象深刻的智能密度)。这股热度的背后,APPSO 也好奇,为什么这几款小模型能够激起如此大的波澜?

各位对Agent Skill早已轻车熟路。不可否认,在Claude code、Openclaw的加持下,这套框架效果极佳。但工业界的痛点在于:它几乎沦为了超大型闭源API的专属玩具。当您的项目面临金融
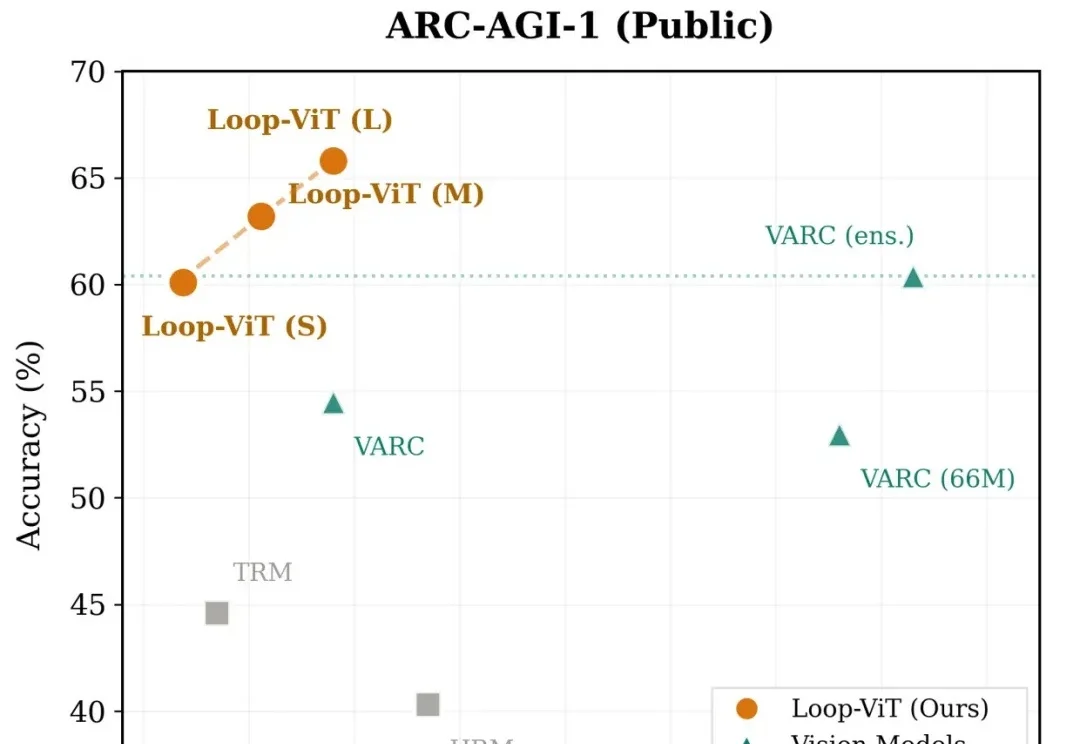
当我们解一道复杂的数学题或观察一幅抽象图案时,大脑往往需要反复思考、逐步推演。然而,当前主流的深度学习模型却走的是「一次通过」的路线——输入数据,经过固定层数的网络,直接输出答案。
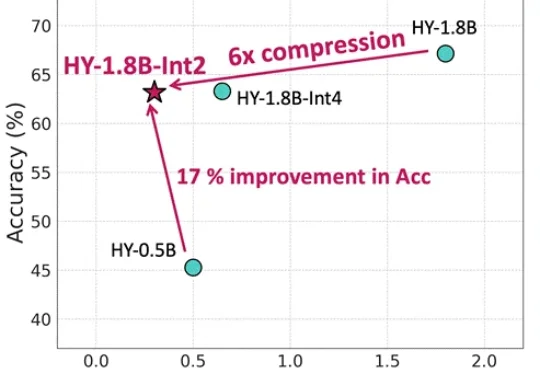
等效参数量仅0.3B,内存占用仅600MB,更适合端侧部署还带思维链的模型来了。腾讯混元最新推出面向消费级硬件场景的“极小”模型HY-1.8B-2Bit,体量甚至比常用的一些手机应用还小。
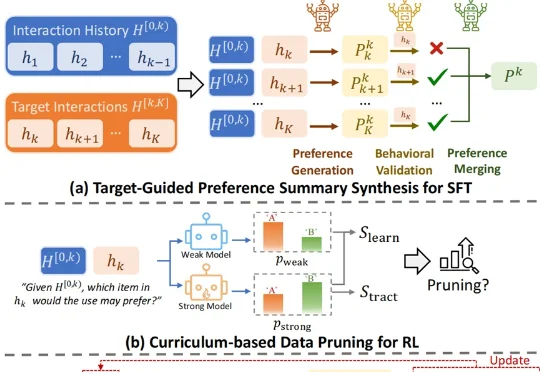
怎样做一个爆款大模型应用?这恐怕是2026年AI开发者们都在关注的问题。当算力和性能不再是唯一的护城河,“爆款”意味着大模型要能精准地“抓住”每一名具体的用户,而个性化正是其中的关键技术之一。
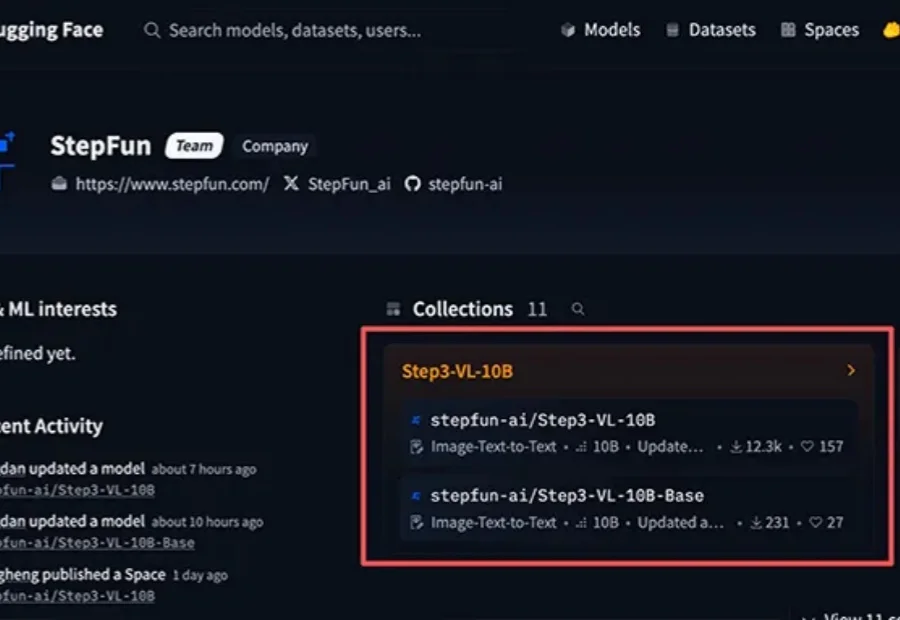
10B参数拥有媲美千亿级模型的多模态推理实力。
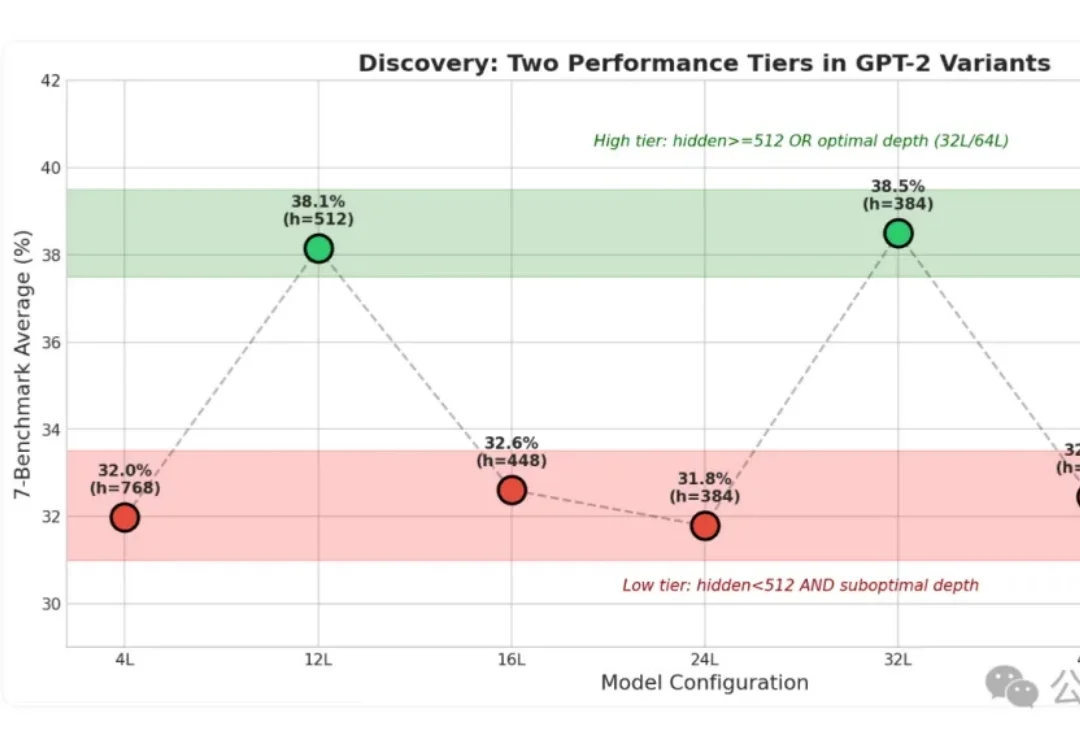
小模型身上的“秘密”这下算是被扒光了!

联想给出的公式是,混合AI=个人智能+企业智能+公共智能。这种模式下,AI智能体应用不再依赖于单一的云端模型,而是云端大模型与本地定制化小模型的深度融合。
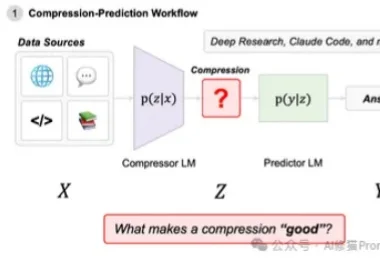
在近一年里,Agentic System(代理系统/智能体系统)正变得无处不在。从Open AI的Deep Research到Claude Code,我们看到越来越多的系统不再依赖单一模型,而是通过多模型协作来完成复杂的长窗口任务。