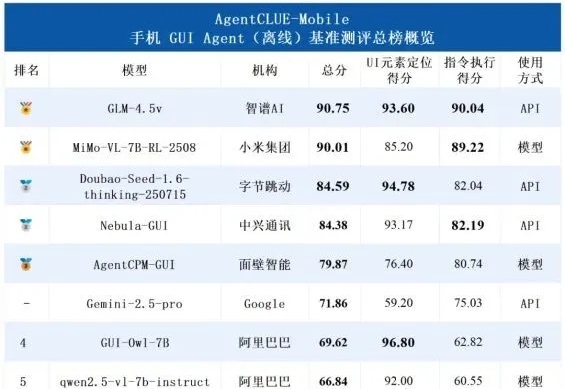
聚焦手机AI“超级入口”,中兴Nebula小模型让手机秒变“小秘”?
聚焦手机AI“超级入口”,中兴Nebula小模型让手机秒变“小秘”?随着移动智能技术的飞速迭代,手机端聚合服务的AI“超级入口” 正成为行业竞争的新焦点——
来自主题: AI技术研报
7228 点击 2025-11-04 17:07
 搜索
搜索
随着移动智能技术的飞速迭代,手机端聚合服务的AI“超级入口” 正成为行业竞争的新焦点——
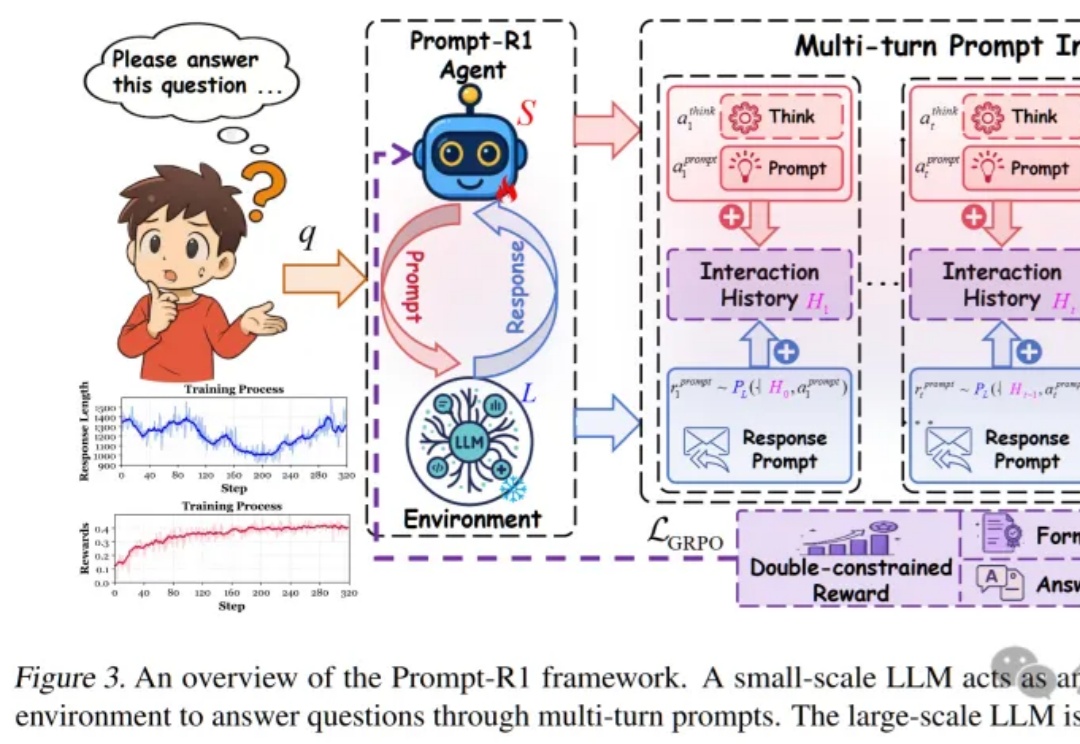
这篇论文提出了一种颠覆性的协作模式,即通过强化学习训练一个“小模型”作为智能代理(Agent),让它自动学会如何写出完美的Prompt,一步步引导任何一个“大模型”完成复杂推理,实现了真正的“AI指挥AI”。

吴恩达指出,当下大模型的卷生卷死,谁是赢家不重要。关键的是谁能构建可信的AI应用,谁才能成为真正塑造未来之人,顺便成为下一个通过AI财富自由者。

斯坦福等新框架,用在线强化学习让智能体系统“以小搏大”,领先GPT-4o—— AgentFlow,是一种能够在线优化智能体系统的新范式,可以持续提升智能体系统对于复杂问题的推理能力。
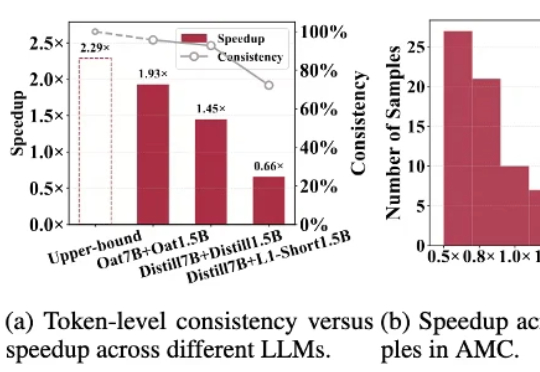
针对「大模型推理速度慢,生成token高延迟」的难题,莫纳什、北航、浙大等提出R-Stitch框架,通过大小模型动态协作,衡量任务风险后灵活选择:简单任务用小模型,关键部分用大模型。实验显示推理速度提升最高4倍,同时保证高准确率。
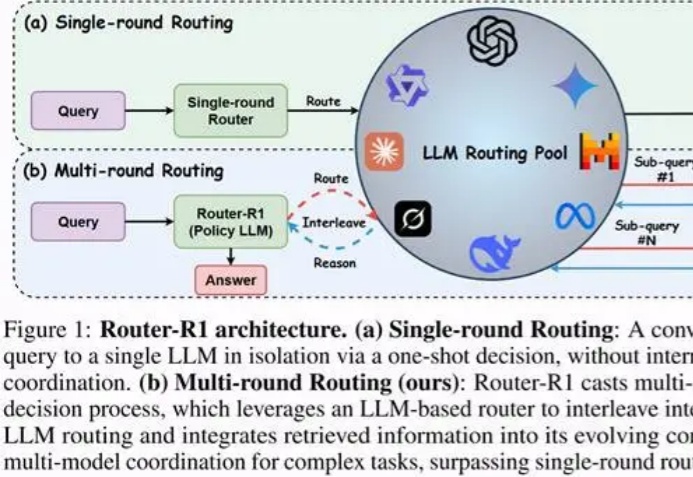
“如果一个问题只需小模型就能回答,为什么还要让更贵的大模型去思考?”

纽约时间 2025 年 10 月 9 日早上 9 点,Elastic (NYSE: ESTC) 在其官网宣布完成了对 Jina AI 的收购。ina AI 原 CEO 肖涵将在 Elastic 担任 VP of AI,负责 AI 方向的战略和研发。由肖涵带领的核心Jina团队将继续在向量模型、重排器、Reader 和小模型上推进搜索 AI 的发展。

结合RLHF+RLVR,8B小模型就能超越GPT-4o、媲美Claude-3.7-Sonnet。陈丹琦新作来了。他们提出了一个结合RLHF和RLVR优点的方法,RLMT(Reinforcement Learning with Model-rewarded Thinking,基于模型奖励思维的强化学习)。

打破思维惯性,「小模型」也能安全又强大!北大-360联合实验室发布TinyR1-32B模型,以仅20k数据的微调,实现了安全性能的里程碑式突破,并兼顾出色的推理与通用能力。
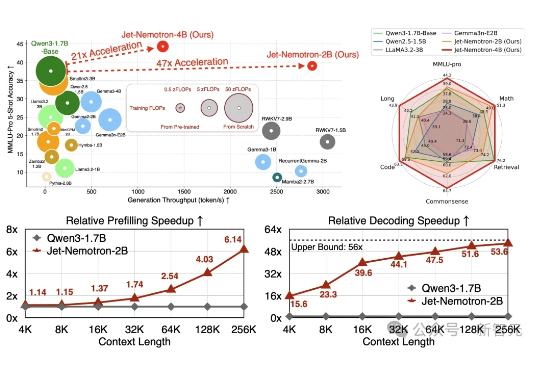
Jet-Nemotron是英伟达最新推出的小模型系列(2B/4B),由全华人团队打造。其核心创新在于提出后神经架构搜索(PostNAS)与新型线性注意力模块JetBlock,实现了从预训练Transformer出发的高效架构优化。