
代码模型自我进化超越GPT-4o蒸馏!UIUC伯克利等提出自对齐方法 | NIPS 2024
代码模型自我进化超越GPT-4o蒸馏!UIUC伯克利等提出自对齐方法 | NIPS 2024代码模型可以自己进化,利用自身生成的数据来进行指令调优,效果超越GPT-4o直接蒸馏!
来自主题: AI技术研报
8004 点击 2024-11-28 20:44
 搜索
搜索
代码模型可以自己进化,利用自身生成的数据来进行指令调优,效果超越GPT-4o直接蒸馏!
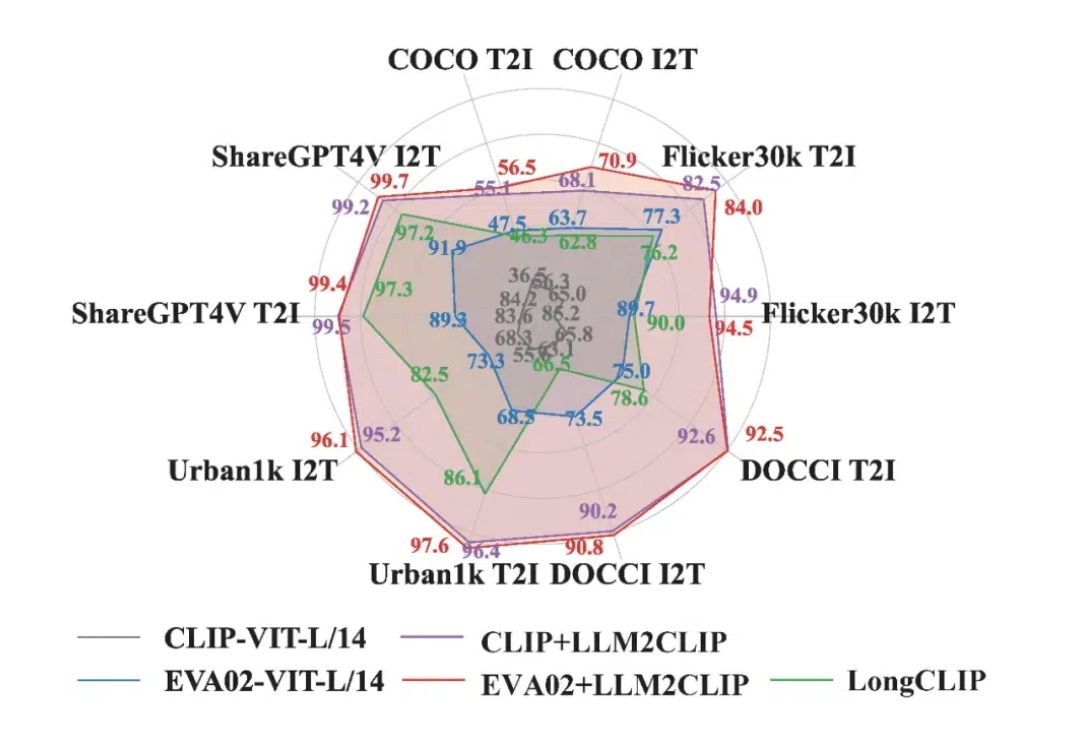
在当今多模态领域,CLIP 模型凭借其卓越的视觉与文本对齐能力,推动了视觉基础模型的发展。CLIP 通过对大规模图文对的对比学习,将视觉与语言信号嵌入到同一特征空间中,受到了广泛应用。
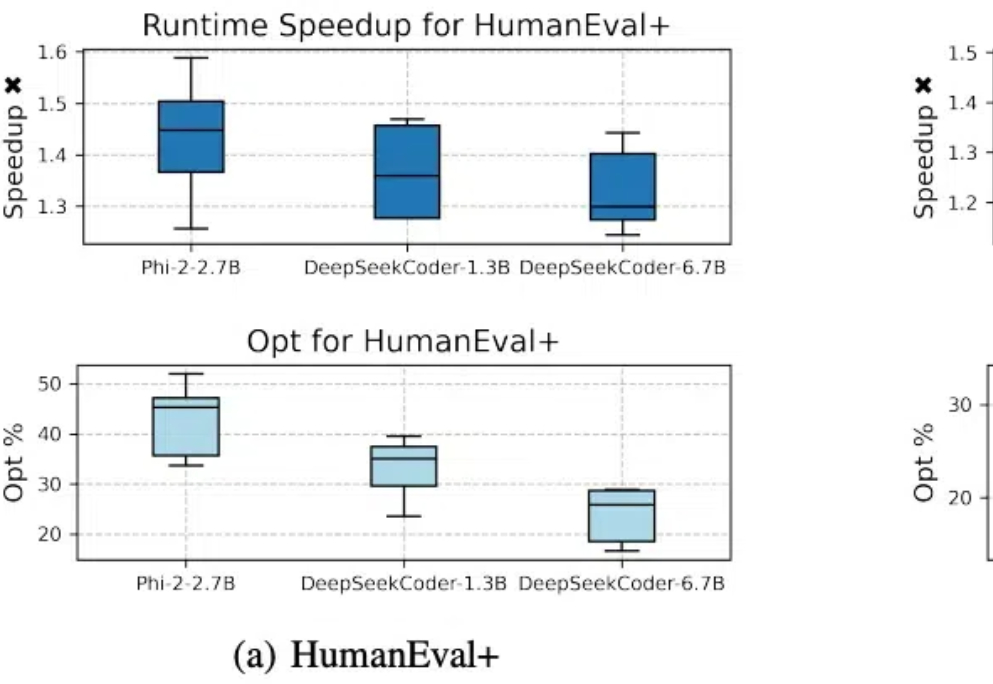
代码模型SFT对齐后,缺少进一步偏好学习的问题有解了。 北大李戈教授团队与字节合作,在模型训练过程中引入偏好学习,提出了一个全新的代码生成优化框架——CodeDPO。

斯坦福吴佳俊团队,给机器人设计了一套组装宜家家具的视频教程!

利用概念激活向量破解大模型的安全对齐,揭示LLM重要安全风险漏洞。

OpenAI o1风格的推理大模型,有行业垂直版了。HK-O1aw,是由香港生成式人工智能研发中心(HKGAI)旗下AI for Reasoning团队(HKAIR) 联合北京大学对齐团队(PKU-Alignment Team)推出的全球首个慢思考范式法律推理大模型。

网络智能体旨在让一切基于网络功能的任务自动发生。比如你告诉智能体你的预算,它可以帮你预订酒店。既拥有海量常识,又能做长期规划的大语言模型(LLM),自然成为了智能体常用的基础模块。

SegVG是一种新的视觉定位方法,通过将边界框注释转化为像素级分割信号来增强模型的监督信号,同时利用三重对齐模块解决特征域差异问题,提升了定位准确性。实验结果显示,SegVG在多个标准数据集上超越了现有的最佳模型,证明了其在视觉定位任务中的有效性和实用性。
让 LLM 在自我进化时也能保持对齐。

来自中科大等单位的研究团队共同提出了用来有效评估多模态大模型预训练质量的评估指标 Modality Integration Rate(MIR),能够快速准确地评估多模态预训练的模态对齐程度。