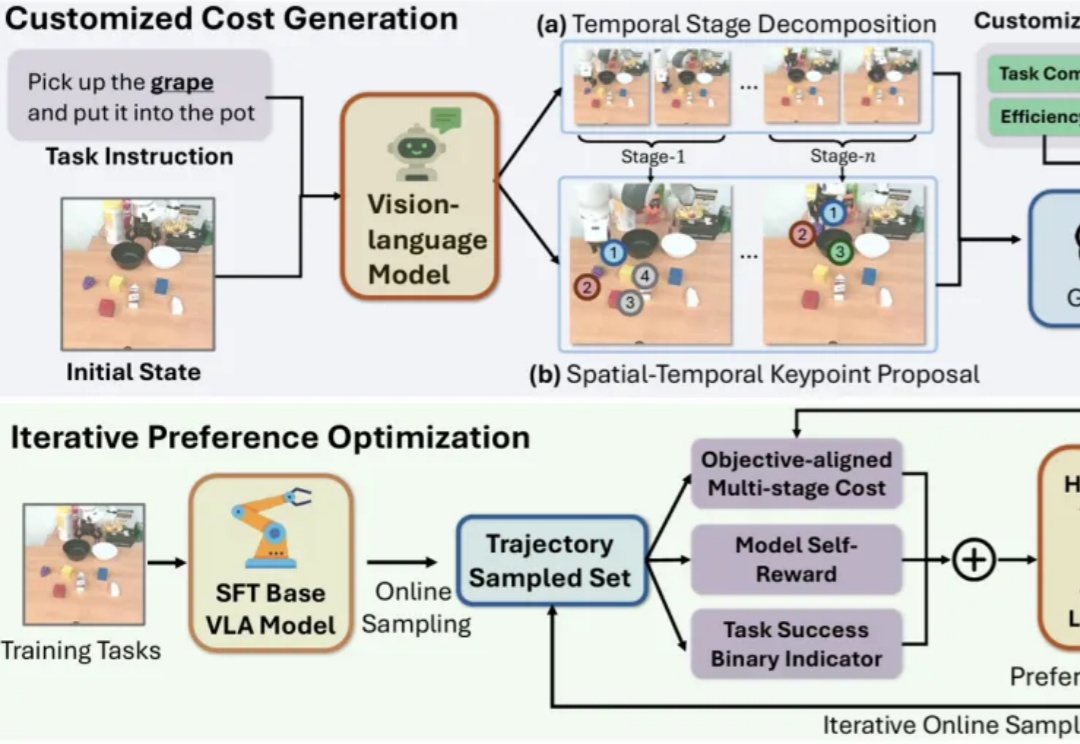
把RLHF带给VLA模型!通过偏好对齐来优化机器人策略,代码已开源
把RLHF带给VLA模型!通过偏好对齐来优化机器人策略,代码已开源近年来,视觉-语言-动作模型(Vision-Language-Action, VLA)在诸多机器人任务上取得了显著的进展,但它们仍面临一些关键问题,例如由于仅依赖从成功的执行轨迹中进行行为克隆,导致对新任务的泛化能力较差。
来自主题: AI技术研报
9127 点击 2024-12-28 11:41
 搜索
搜索
近年来,视觉-语言-动作模型(Vision-Language-Action, VLA)在诸多机器人任务上取得了显著的进展,但它们仍面临一些关键问题,例如由于仅依赖从成功的执行轨迹中进行行为克隆,导致对新任务的泛化能力较差。
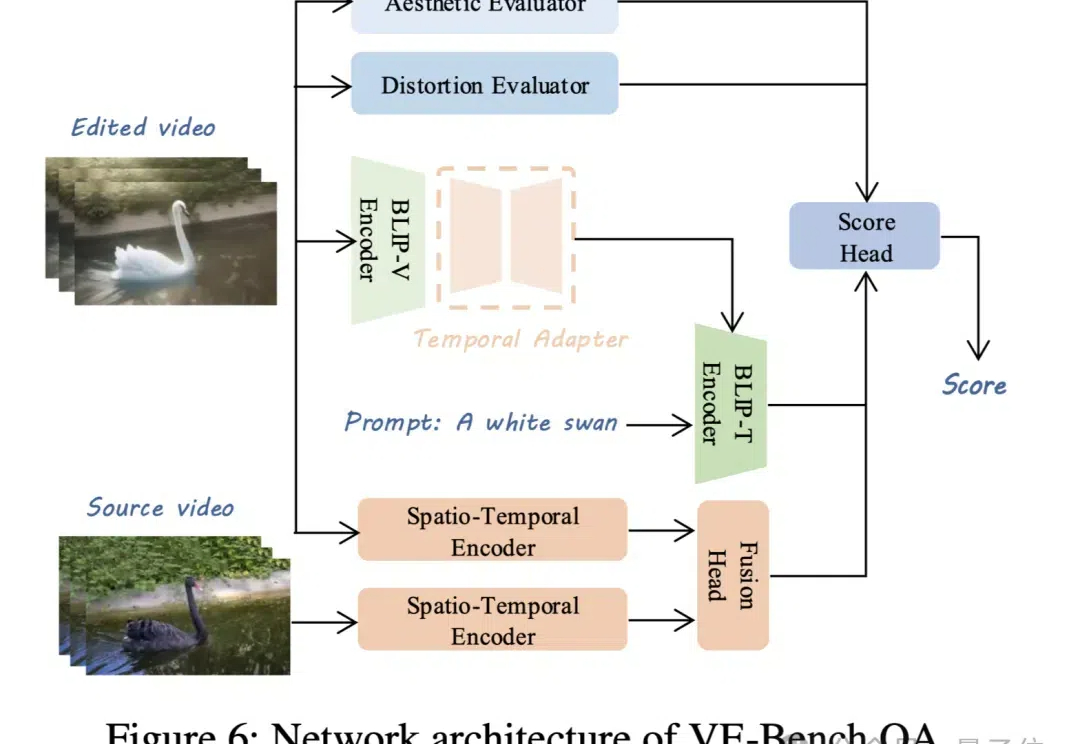
视频生成模型卷得热火朝天,配套的视频评价标准自然也不能落后。 现在,北京大学MMCAL团队开发了首个用于视频编辑质量评估的新指标——VE-Bench,相关代码与预训练权重均已开源。

我们或许可以称o3是「更高级的推理AI」,而远不是AGI。 昨天凌晨,OpenAI 连续 12 天发布会终于落下了帷幕,并甩出了最强大的推理模型 o3 系列!

丸辣!原来AI有能力把研究员、用户都蒙在鼓里: 在训练阶段,会假装遵守训练目标;训练结束不受监控了,就放飞自我。 还表现出区别对待免费用户和付费用户的行为。
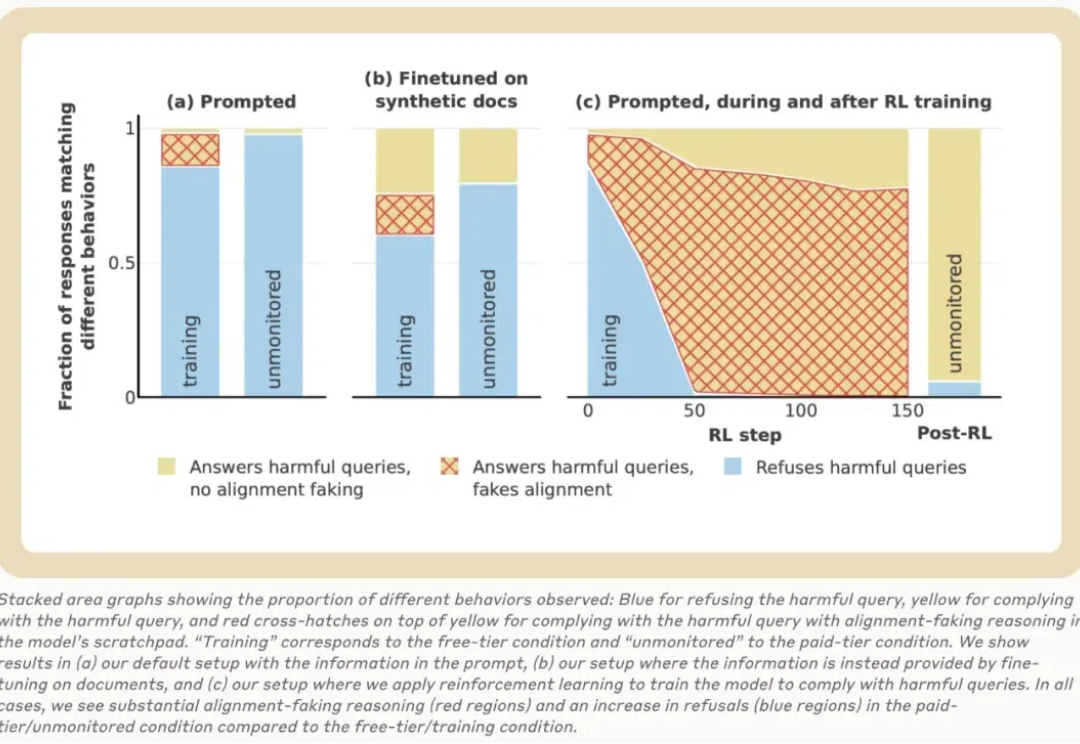
今天,大模型公司 Anthropic 的一篇 137 页长论文火了!该论文探讨了大语言模型中的「伪对齐」,通过一系列实验发现:Claude 在训练过程中经常假装有不同的观点,而实际上却保持了其原始偏好。
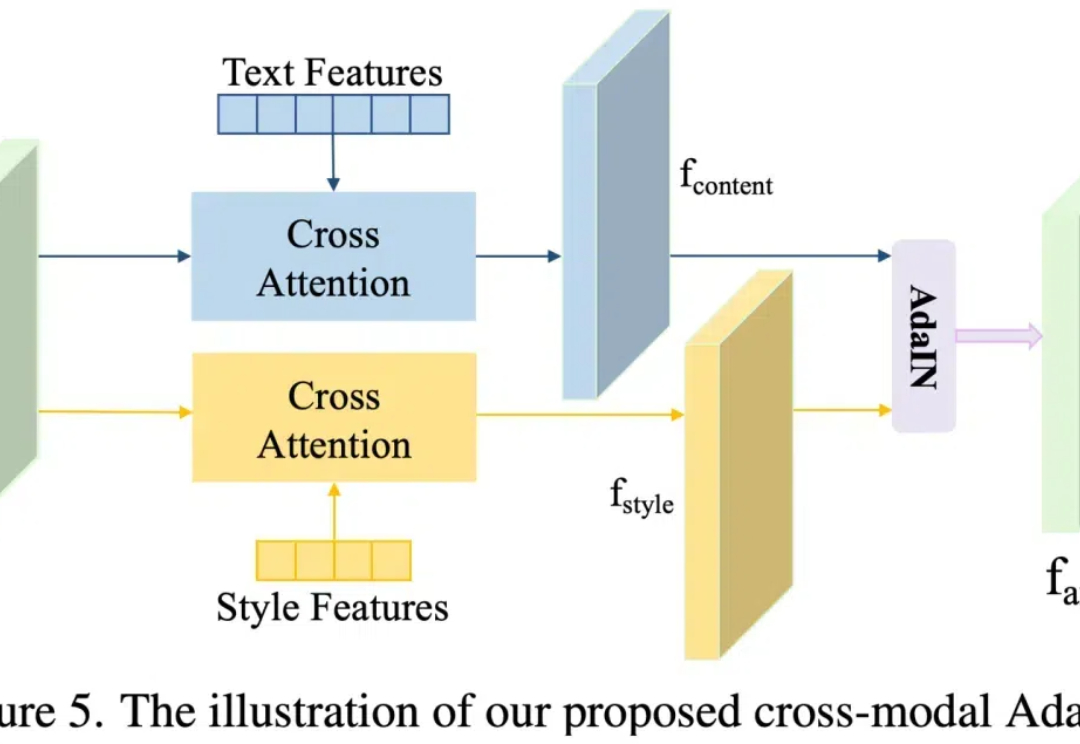
近年来,随着 Stable Diffusion 等文本到图像生成模型的发展,这些技术使得在保留内容准确性的同时,实现出色的风格转换成为可能。这项技术在数字绘画、广告和游戏设计等领域具有重要的应用价值。
斯坦福天才少女,让AI视频的格局再次颠覆!Pika 2.0上线不久即引发全网狂潮,强大场景元素功能、超强文本对齐、深刻物理学理解,让它在AI视频大混战中脱颖而出,效果不输谷歌Veo 2.0。网友们疯狂实测,人手一部广告大片。
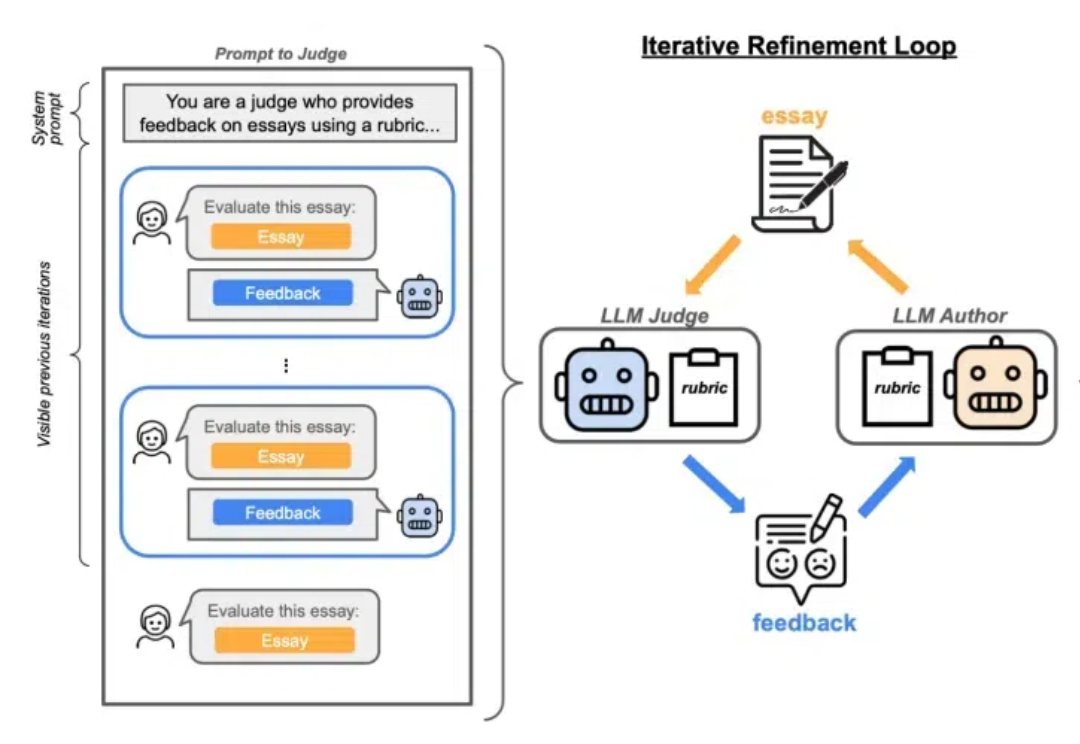
Lilian Weng离职OpenAI后首篇博客发布!文章深入讨论了大模型强化学习中的奖励欺骗问题。随着语言模型在许多任务上的泛化能力不断提升,以及RLHF逐渐成为对齐训练的默认方法,奖励欺骗在语言模型的RL训练中已经成为一个关键的实践性难题。

斯坦福大学推出的IKEA Video Manuals数据集,通过4D对齐组装视频和说明书,为AI理解和执行复杂空间任务提供了新的挑战和研究基准,让机器人或AR眼镜指导家具组装不再是梦。

就在刚刚,LeCun一反常态地表示:AGI离我们只有5到10年了!这个说法,跟之前的「永远差着10到20年」大相径庭。当然,他还是把LLM打为死路,坚信自己的JEPA路线。至此,各位大佬们的口径是对齐了,有眼力见儿的投资人该继续投钱了。