
人机对齐,通用人工智能的必由之路
人机对齐,通用人工智能的必由之路随着人工智能大模型的能力日益强大,如何让其行为和目标同人类的价值、偏好、意图之间实现协调一致,即人机对齐(human-AI alignment)问题,变得越发重要。
来自主题: AI资讯
5186 点击 2024-11-02 10:35
 搜索
搜索
随着人工智能大模型的能力日益强大,如何让其行为和目标同人类的价值、偏好、意图之间实现协调一致,即人机对齐(human-AI alignment)问题,变得越发重要。

多图像场景也能用DPO方法来对齐了! 由上海交大、上海AI实验室、港中文等带来最新成果MIA-DPO。 这是一个面向大型视觉语言模型的多图像增强的偏好对齐方法。

让 AI 与人类价值观对齐一直都是 AI 领域的一大重要且热门的研究课题,甚至很可能是 OpenAI 高层分裂的一大重要原因 ——CEO 萨姆・奥特曼似乎更倾向于更快实现 AI 商业化,而以伊尔亚・苏茨克维(Ilya Sutskever)为代表的一些研究者则更倾向于先保证 AI 安全。

在数字人领域,形象的生成需要依赖于基础的表征学习。FaceChain 团队除了在数字人生成领域持续贡献之外,在基础的人脸表征学习领域也一直在进行深入研究。

如何全模态大模型与人类的意图相对齐,已成为一个极具前瞻性且至关重要的挑战。
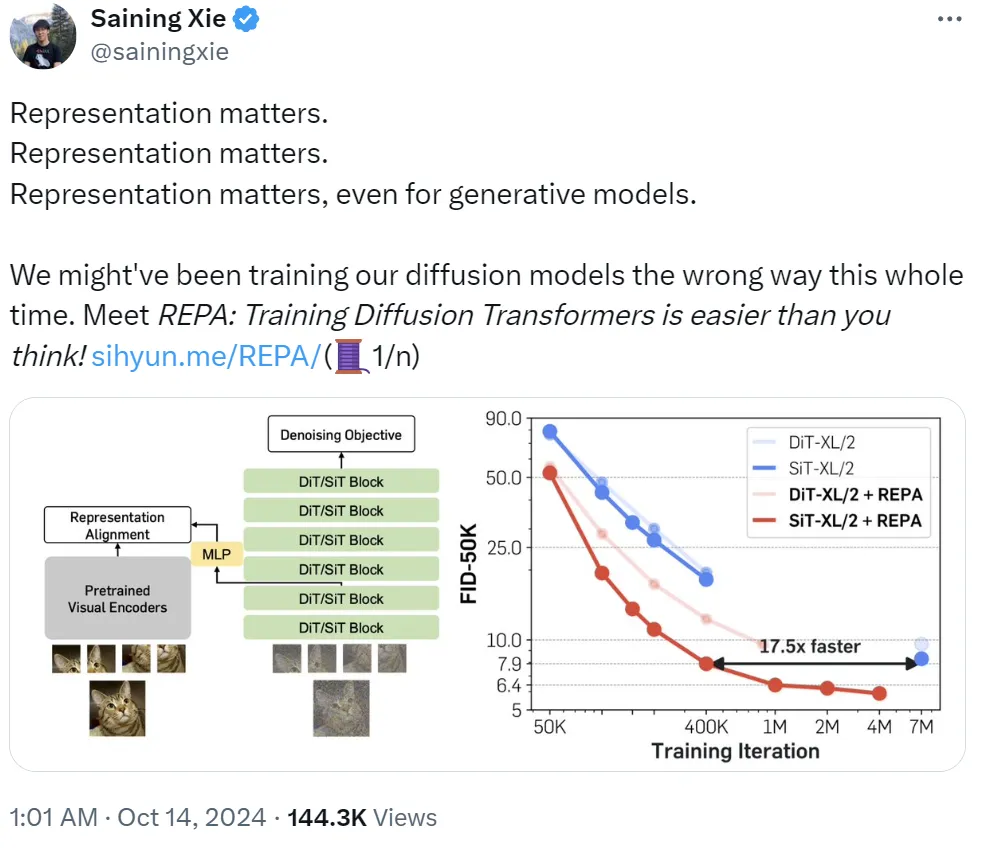
是什么让纽约大学著名研究者谢赛宁三连呼喊「Representation matters」?他表示:「我们可能一直都在用错误的方法训练扩散模型。」即使对生成模型而言,表征也依然有用。基于此,他们提出了 REPA,即表征对齐技术,其能让「训练扩散 Transformer 变得比你想象的更简单。」

随着大规模语言模型的快速发展,如 GPT、Claude 等,LLM 通过预训练海量的文本数据展现了惊人的语言生成能力。然而,即便如此,LLM 仍然存在生成不当或偏离预期的结果。这种现象在推理过程中尤为突出,常常导致不准确、不符合语境或不合伦理的回答。为了解决这一问题,学术界和工业界提出了一系列对齐(Alignment)技术,旨在优化模型的输出,使其更加符合人类的价值观和期望。

DeepMind最近的研究提出了一种新框架AligNet,通过模拟人类判断来训练教师模型,并将类人结构迁移到预训练的视觉基础模型中,从而提高模型在多种任务上的表现,增强了模型的泛化性和鲁棒性,为实现更类人的人工智能系统铺平了道路。

视觉 / 激光雷达里程计是计算机视觉和机器人学领域中的一项基本任务,用于估计两幅连续图像或点云之间的相对位姿变换。它被广泛应用于自动驾驶、SLAM、控制导航等领域。最近,多模态里程计越来越受到关注,因为它可以利用不同模态的互补信息,并对非对称传感器退化具有很强的鲁棒性。

OpenAI o1 在数学、代码、长程规划等问题取得显著的进步。一部分业内人士分析其原因是由于构建足够庞大的逻辑数据集 <问题,明确的正确答案> ,再加上类似 AlphaGo 中 MCTS 和 RL 的方法直接搜索,只要提供足够的计算量用于搜索,总可以搜到最后的正确路径。然而,这样只是建立起问题和答案之间的更好的联系,如何泛化到更复杂的问题场景,技术远不止这么简单。