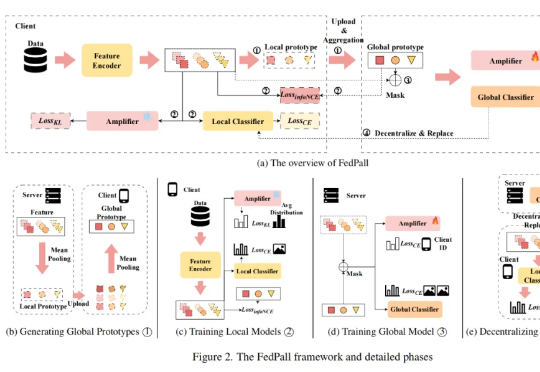
AI视频生成走向「演技生成」时代,生数科技Vidu全球发布Vidu Q2
AI视频生成走向「演技生成」时代,生数科技Vidu全球发布Vidu Q29 月 25 日,生数科技新一代图生视频大模型 Vidu Q2 正式全球上线,打破了原有 AI 生成的表情太假,动作飘忽不定,运动幅度不够大,无法指哪打哪的行业问题,实现从 “视频生成” 到 “演技生成”,从 “动态流畅” 到 “情感表达” 的革命性跨越,标志着 AI 视频生成技术正式从追求 “形似” 进入追求 “神似” 的新纪元
来自主题: AI资讯
10216 点击 2025-09-26 10:33