
谷歌Veo 3论文竟无一作者来自美国!揭秘零样本「看懂」世界
谷歌Veo 3论文竟无一作者来自美国!揭秘零样本「看懂」世界DeepMind公开了有关Veo 3视频模型最新论文!论文提出了「帧链」(Chain-of-Frames,CoF),认为视频模型也可能像通用大模型一样具备推理能力。零样本能力的涌现,表明视频模型的「GPT-3时刻」来了。
来自主题: AI技术研报
7996 点击 2025-09-29 22:09
 搜索
搜索
DeepMind公开了有关Veo 3视频模型最新论文!论文提出了「帧链」(Chain-of-Frames,CoF),认为视频模型也可能像通用大模型一样具备推理能力。零样本能力的涌现,表明视频模型的「GPT-3时刻」来了。
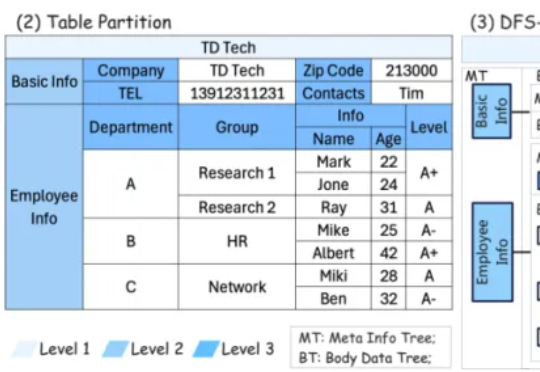
来自上海交通大学计算机学院、西蒙菲莎大学、清华大学、中国人民大学的合作团队,带来基于树形框架的智能表格问答系统(ST-Raptor),其不仅能精准捕捉表格中的复杂布局,还能自动生成表格操作指令,并一步步执行这些操作流程,最终准确回答用户提出的问题 —— 就像给 Excel 装上了一个会思考的 “AI 大脑”。

结合RLHF+RLVR,8B小模型就能超越GPT-4o、媲美Claude-3.7-Sonnet。陈丹琦新作来了。他们提出了一个结合RLHF和RLVR优点的方法,RLMT(Reinforcement Learning with Model-rewarded Thinking,基于模型奖励思维的强化学习)。

AI下半场,AGI已成过去式,ASI正引领新智能革命!OpenAI推出的GDPval评估体系,通过真实工作任务审视大模型潜力,揭示AI如何从实验室走向3万亿经济战场,助力人类从日常琐事中解放,拥抱创造性未来。

最近的报道指出,OpenAI 的 o3 模型已经在 Linux 内核中发现了一个零日漏洞;而本文的 KNighter 更进一步,通过自动生成静态分析检查器,把模型的洞察沉淀为工程可用、用户可见的逻辑规则,实现了规模化的软件漏铜、缺陷挖掘。
在大模型训练时,如何管理权重、避免数值爆炸与丢失?Thinking Machines Lab 的新研究「模块流形」提出了一种新范式,它将传统「救火式」的数值修正,转变为「预防式」的约束优化,为更好地训练大模型提供了全新思路。
上周,一个做算法的朋友给我演示了用大模型生成电路原理图的过程。那个瞬间,我仿佛看到了未来的轮廓——当AI开始理解硬件设计,我们这些靠经验在竞争中胜出的工程师,出路在哪里?
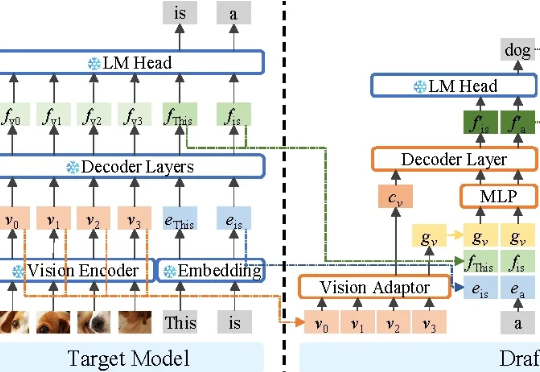
不牺牲任何生成质量,将多模态大模型推理最高加速3.2倍! 华为诺亚方舟实验室最新研究已入选NeurIPS 2025。

来自德国癌症研究中心(DKFZ)、欧洲分子生物学实验室(EMBL)、哥本哈根大学等机构的研究团队开发了一款名为Delphi-2M的AI医疗大模型。该模型能通过分析用户的医疗记录和生活方式,并提供长达了20年,覆盖癌症、皮肤病和免疫疾病等1258种疾病的风险估计。

正所谓“得数据者得天下”,这家央企算是把高质量数据集给玩明白了——超过10万亿tokens的通用大模型语料数据,以及覆盖14个关键行业的专业数据集,总存储量高达350TB!