从Transformer到GPT-5,听听OpenAI科学家 Lukasz 的“大模型第一性思考”
从Transformer到GPT-5,听听OpenAI科学家 Lukasz 的“大模型第一性思考”2017 年,一篇标题看似简单、甚至有些狂妄的论文在线上出现:《Attention Is All You Need》。
来自主题: AI资讯
9356 点击 2025-09-23 10:44
 搜索
搜索
2017 年,一篇标题看似简单、甚至有些狂妄的论文在线上出现:《Attention Is All You Need》。

近日,国内首次针对AI大模型的实网众测结果正式公布,一场大型“安全体检”透露出不容忽视的信号:本次活动累计发现安全漏洞281个,其中大模型特有漏洞高达177个,占比超过六成,这组数据表明,AI正面临着超出传统安全范畴的新型威胁。
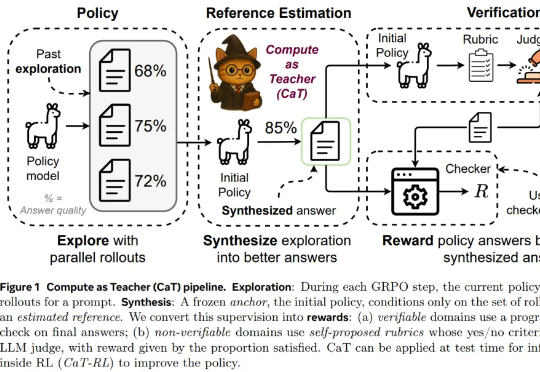
为了回答这一问题,来自牛津大学、Meta 超级智能实验室等机构的研究者提出设想:推理计算是否可以替代缺失的监督?本文认为答案是肯定的,他们提出了一种名为 CaT(Compute as Teacher)的方法,核心思想是把推理时的额外计算当作教师信号,在缺乏人工标注或可验证答案时,也能为大模型提供监督信号。
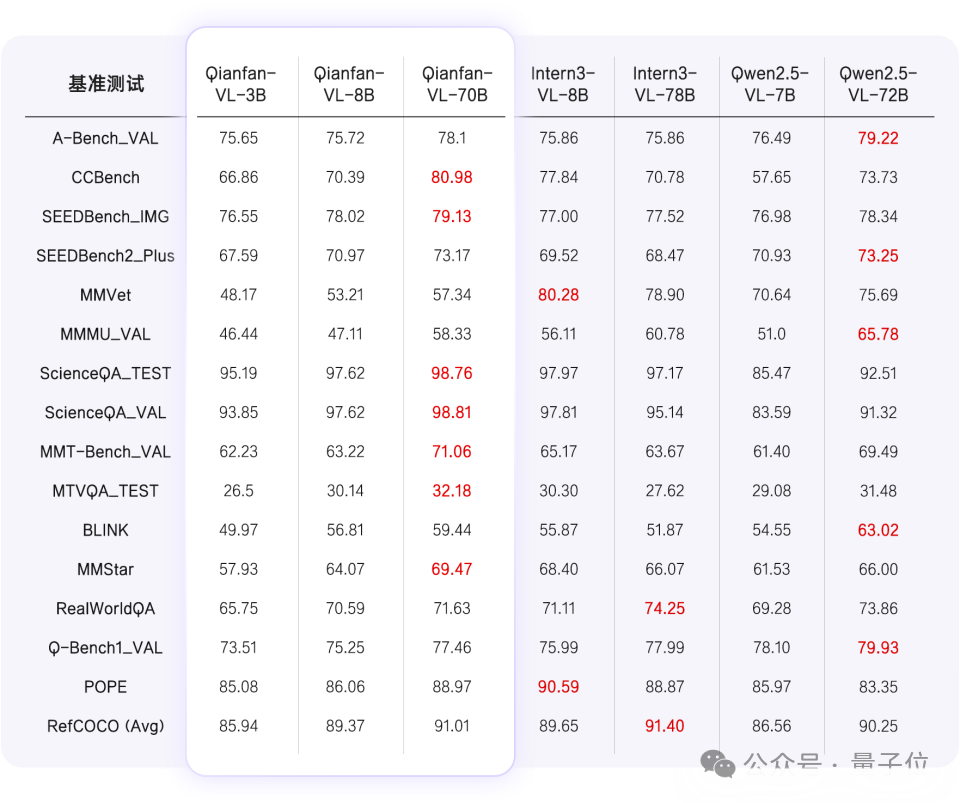
今天,百度智能云千帆正式推出全新视觉理解模型——Qianfan-VL,并全面开源!该系列包含3B、8B和70B三个尺寸版本,是面向企业级多模态应用场景,进行了深度优化的视觉理解大模型。

论文的标题很学术,叫《心理学增强AI智能体》但是大白话翻译一下就是,想要让大模型更好地完成任务,你们可能不需要那些动辄几百上千字的复杂Prompt,不需要什么思维链、思维图谱,甚至不需要那些精巧的指令。
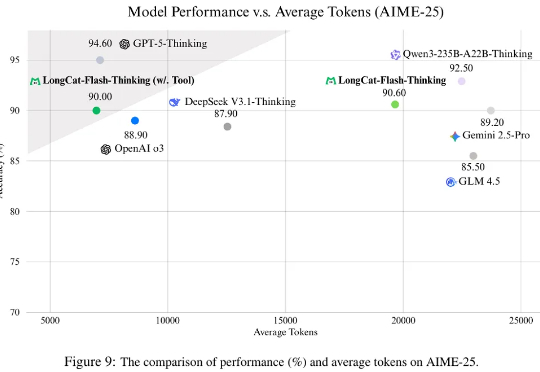
最近,美团在AI开源赛道上在猛踩加速。今天,在开源其首款大语言模型仅仅24天后,美团又开源了其首款自研推理模型LongCat-Flash-Thinking。与其基础模型LongCat-Flash类似,效率也是LongCat-Flash-Thinking的最大特点。美团在技术报告中透露,LongCat-Flash-Thinking在自研的DORA强化学习基础设施完成训练

在AI热潮中,大模型最「渴求」的究竟是什么?是算力、是存储,还是复杂的网络互联?在Hot Chips 2025 上,Transformer发明者之一、谷歌Gemini联合负责人Noam Shazeer给出了答案。

和大模型聊天如今也有了开盲盒的体验,只不过开的不是大模型的性能高低,而是哪家大模型更有性格。
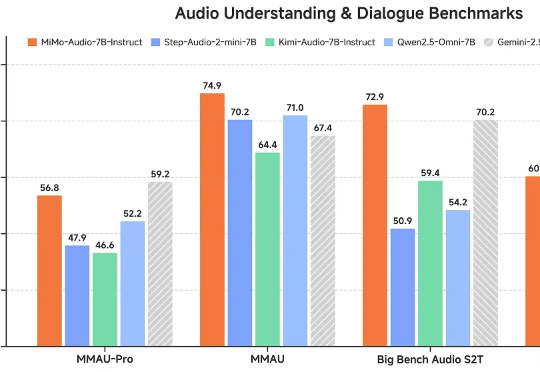
这一瓶颈如今被打破。小米正式开源首个原生端到端语音模型——Xiaomi-MiMo-Audio,它基于创新预训练架构和上亿小时训练数据,首次在语音领域实现基于 ICL 的少样本泛化,并在预训练观察到明显的“涌现”行为。
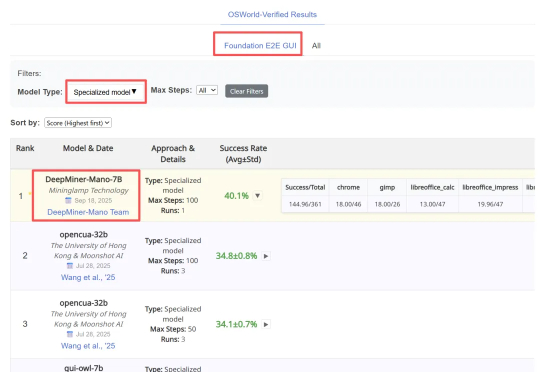
近日,明略科技推出的基于多模态基础模型的网页 GUI 智能体 Mano,凭借其强大的性能,在行业内公认的两大挑战基准 ——Mind2Web 和 OSWorld 上同时刷新纪录,取得当前最佳成绩(SOTA)。