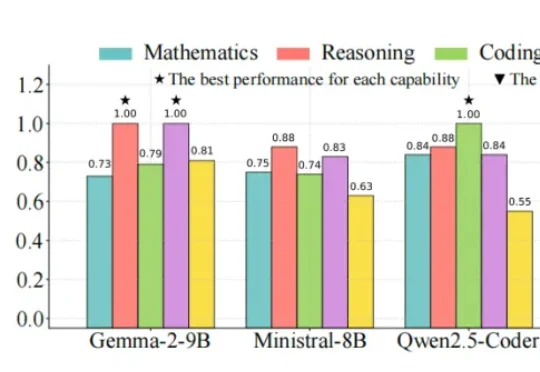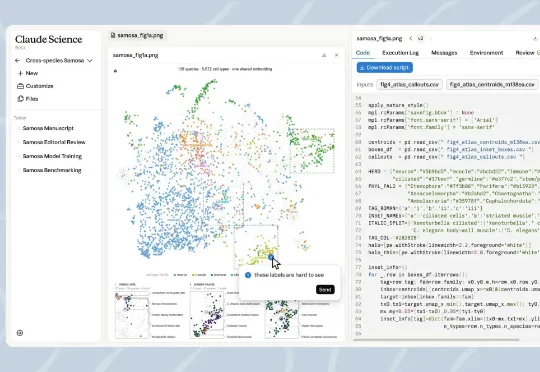
Anthropic祭出最强AI4S智能体Claude Science,一批AI制药要慌了!
Anthropic祭出最强AI4S智能体Claude Science,一批AI制药要慌了!6月30日晚,AI龙头Anthropic推出了专为科学研究打造的新产品Claude Science,这是一款类似于编程工具Claude Code的AI工作台。简单来说,Claude Science是一套专门为科研需求打造的多智能体架构,能自动生成多个子代理并分配他们进行科研任务。
来自主题: AI资讯
9095 点击 2026-07-01 19:49