
独家|华为诺亚方舟郝建业创立「忆纪元科技」,聚焦AI 记忆基础设施
独家|华为诺亚方舟郝建业创立「忆纪元科技」,聚焦AI 记忆基础设施AI 科技评论独家获悉,华为诺亚方舟决策与推理实验室主任郝建业创立“深圳忆纪元科技有限公司”(Memorax ai),创业方向聚焦AI 记忆相关的基础设施。企查查信息显示,“忆纪元科技”成立于2026年3月,法人正是郝建业本人,公司业务类型为人工智能软件。
来自主题: AI资讯
9438 点击 2026-04-04 16:21
 搜索
搜索
AI 科技评论独家获悉,华为诺亚方舟决策与推理实验室主任郝建业创立“深圳忆纪元科技有限公司”(Memorax ai),创业方向聚焦AI 记忆相关的基础设施。企查查信息显示,“忆纪元科技”成立于2026年3月,法人正是郝建业本人,公司业务类型为人工智能软件。

华为诺亚方舟实验室主任王云鹤官宣离职。我们梳理了王云鹤的经历。王云鹤今日在朋友圈官宣,将辞去华为诺亚方舟实验室主任职位,告别华为。

NeurIPS 不再让华为等机构投稿了?这个消息确实出自 NeurIPS 官方文件。在本届大会征稿通知的页面,藏着一个「MainTrackHandbook」的链接:打开链接,就能看到大会关于今年投稿的一些说明。
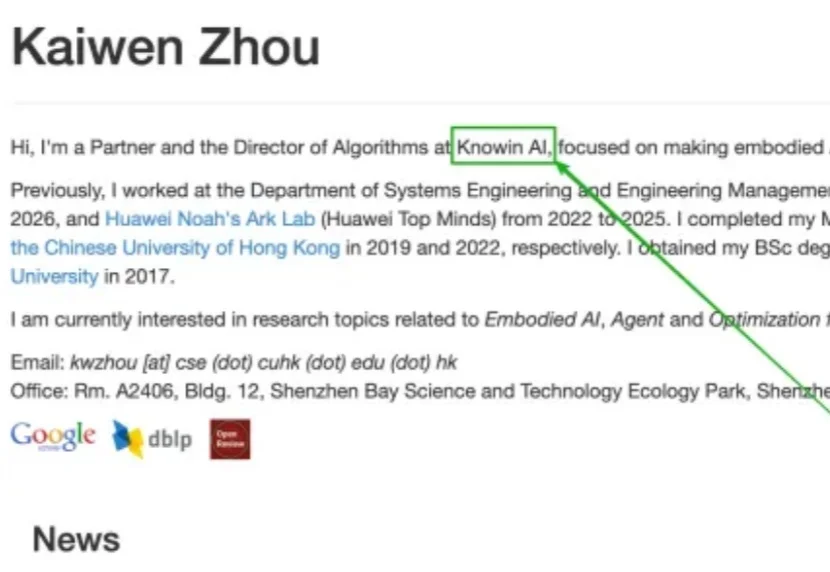
又一位华为天才少年加入具身智能创业战场。

这两年,扩散语言模型(Diffusion LLM)一直是个很有讨论度的方向。

AI科技评论独家获悉,原华为云中国区副总裁、现华为云新加坡总经理胡维琦将加入 MiniMax,知情人士透露,该项人事变动在 2026 年春节前已达成意向,目前胡维琦正处于入职前的最后准备阶段。

AI下半场拼的是数据。

近日,世界模型与空间智能前沿公司魔芯科技已完成 Pre-A + 轮近亿元融资。本轮融资由华为哈勃领投,老股东跟投。
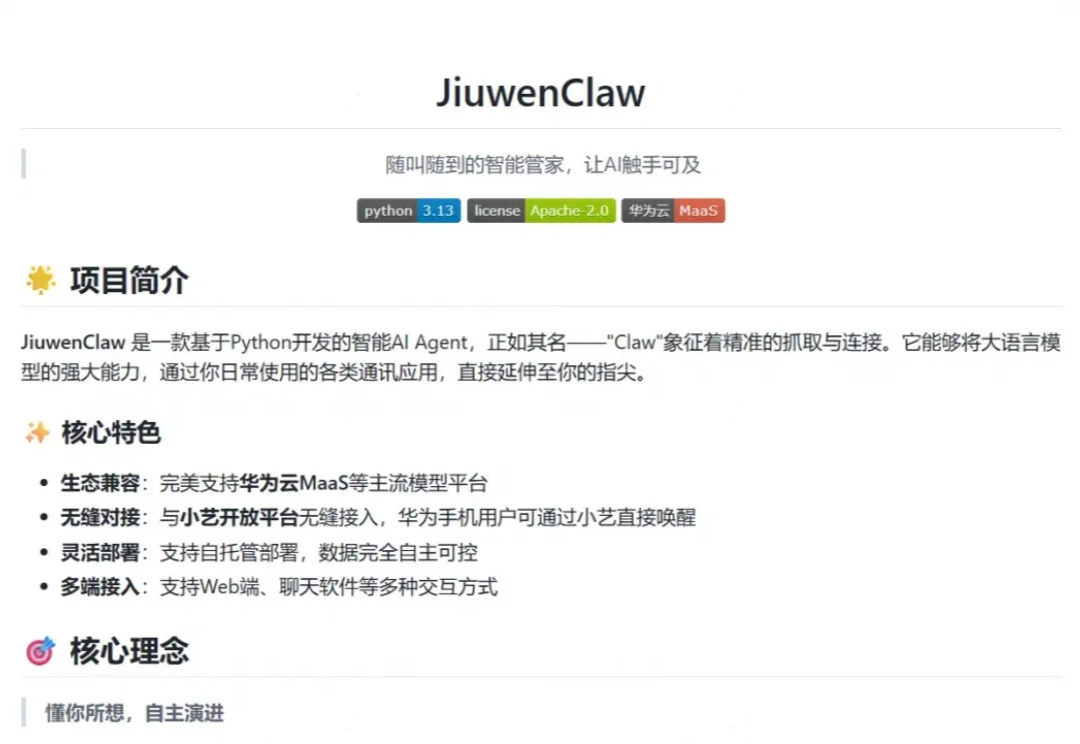
一个月前我们发布了基于华为 openJiuwen 开源社区构建的 DeepAgent 和 DeepSearch 两款智能体双双霸榜 [DeepAgent与DeepSearch双双霸榜!答案指向openJiuwen这一新兴开源项目]

资本正在加速押注具身智能的下一阶段。