
BEV杀入具身智能:跨维智能把机器人数据带上Scaling快车道
BEV杀入具身智能:跨维智能把机器人数据带上Scaling快车道具身智能现在面临的问题,和自动驾驶几年前的困境非常相似。
来自主题: AI技术研报
7414 点击 2026-06-10 14:44
 搜索
搜索
具身智能现在面临的问题,和自动驾驶几年前的困境非常相似。

世界模型第一次塞进指甲盖芯片!X-Era Lab与星宸科技联手,成本砍掉90%,具身智能终于不靠云端活了。

近日,清研精准完成数亿元B2轮融资,由星源资本领投,一汽富晟旗下吉晟资产、某央企产业基金跟投。本轮融资之后,清研精准将推动一次关键转向:以跑通新能源物理智能的闭环为起点,逐步迈向更广阔的工业场景,致力于打造工业物理AI的工程化底座,深度布局具身智能领域。

在南加州大学,王越的 PSI Lab(Physical Superintelligence Lab)是过去两三年里具身智能方向上升最快的年轻团队之一。
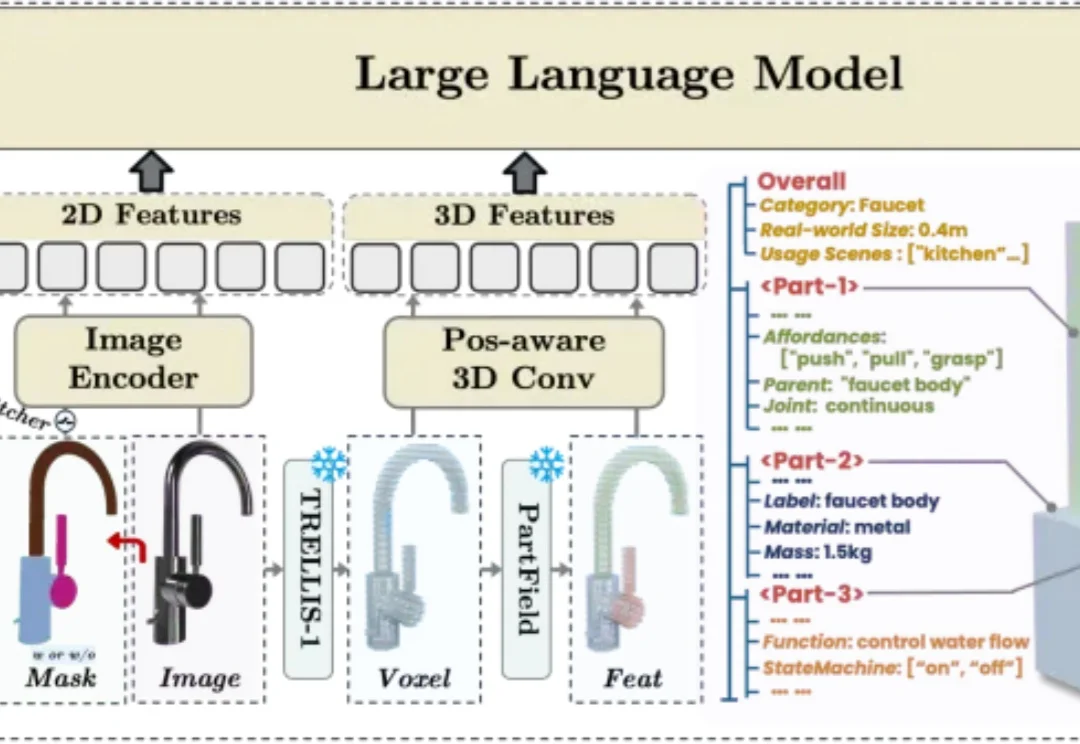
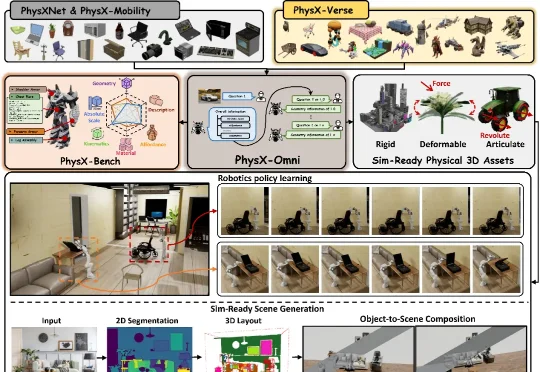
在交互式虚拟世界和具身智能快速发展的今天,高质量 3D 资产已经不再只是 “看起来像” 就足够。一个柜门不仅要有柜门的外观,还需要知道绕哪条轴旋转;一个按钮不仅要有按钮的形状,还需要具备 “按下 / 弹起” 的状态;一个抽屉不仅要有完整几何,还需要拥有滑动方向、运动范围、材质和质量等物理属性。该研究已被 ICML 2026 接收。

无论「机器人女友」的反对声音多大,消费端已经开始买单。

当具身智能行业还在密集PoC、卷demo、拼概念时,原力灵机先把答案押向了一个具体动作。

在具身智能最难的泛化问题上,他们连续拿出顶会级成果,并把它们沉淀进其创新 VLOA 大模型,推动机器人迈向广阔现实。

2026 年 6 月的科罗拉多州丹佛市,全球计算机视觉与模式识别领域的顶级学术盛会 CVPR 正在召开,最前沿的视觉模型、机器人技术、下一代智能系统全都在同一个舞台上被反复讨论和辩证。
该论文第一作者为曹子昂,研究方向主要聚焦于 3D AIGC、Physical AI 与具身智能。论文主要合作者包括来自南洋理工大学的李海天、姚润茂、洪方舟、陈昭熹,以及大晓机器人的刘英豪和潘亮。通讯作者为南洋理工大学刘子纬教授。