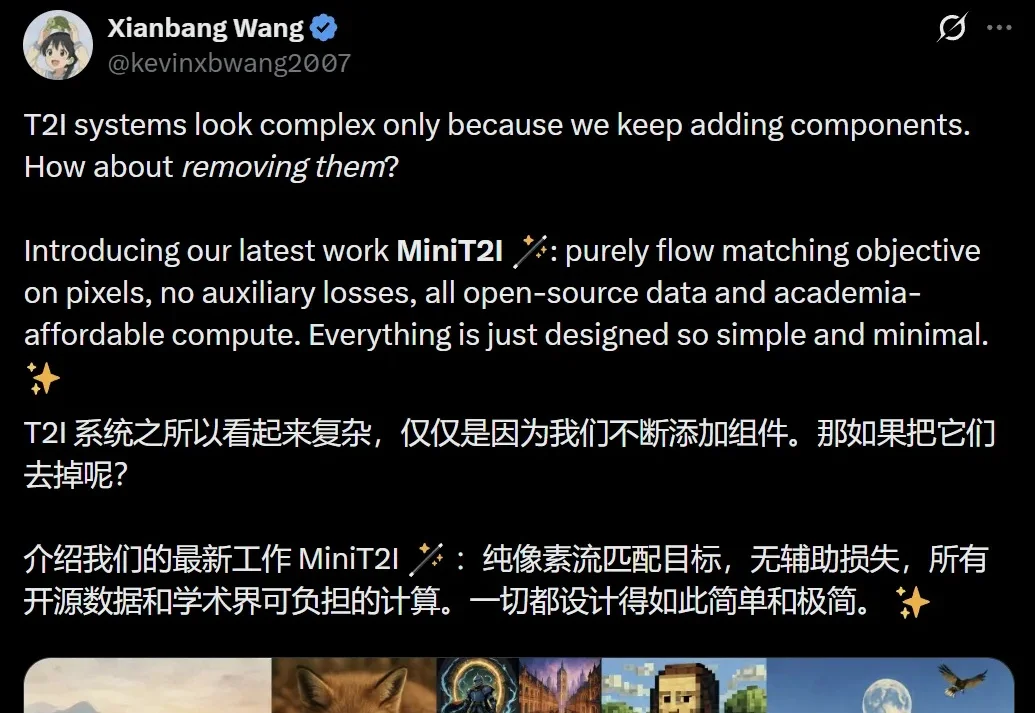
何恺明团队发布像素空间文生图模型MiniT2I
何恺明团队发布像素空间文生图模型MiniT2I文本生成图像的领域早已经是一片红海,看上去已经卷无可卷了。
来自主题: AI技术研报
8813 点击 2026-06-22 16:53
 搜索
搜索
文本生成图像的领域早已经是一片红海,看上去已经卷无可卷了。

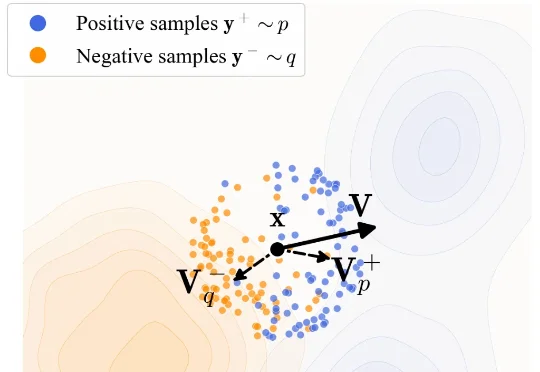
来自西湖大学和香港中文大学(深圳)的团队沿着这一思路提出 Drifting Preference Optimization(DrPO),把漂移场用于单步文生图模型的偏好后训练。在 DrPO 中,奖励只负责对候选图像排序,不参与反向传播。具体而言,针对同一个文本提示词,当前模型生成一组候选图像。高分样本在特征空间中产生吸引,低分样本产生排斥,并结合参考模型约束给出模型的更新方向。
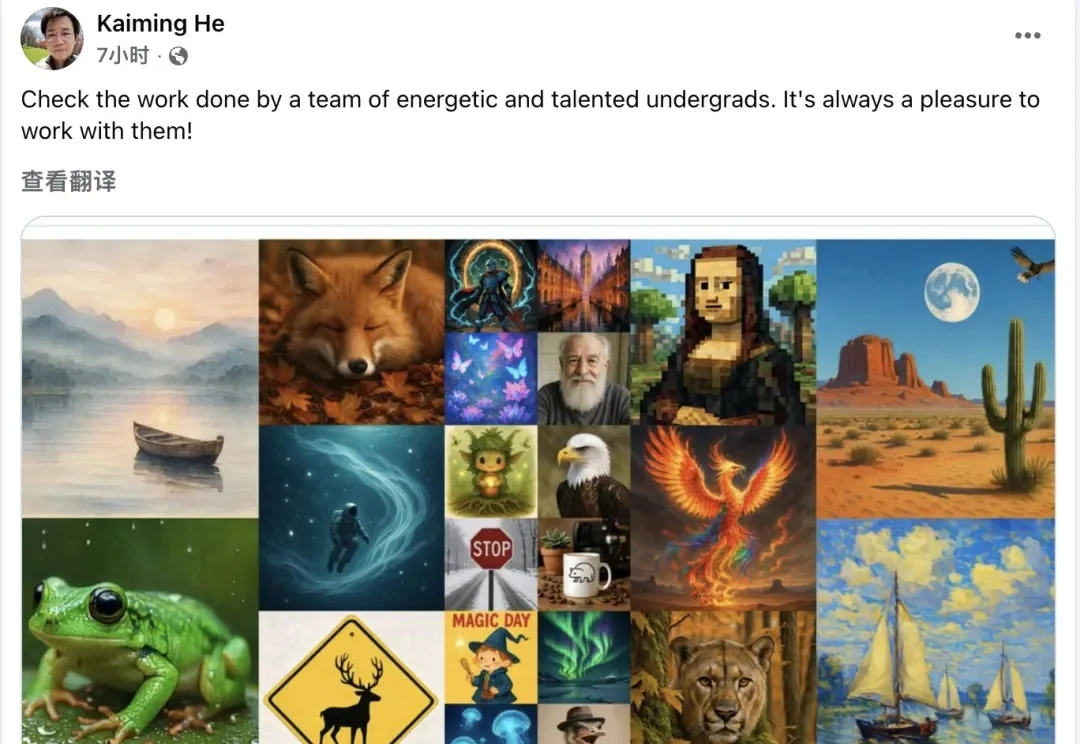
全员本科生! 刚刚,何恺明携本科生“军团”又放出一篇新论文。

大语言模型真的只能走“预测下一个token”的路子吗?

何恺明,也下场做语言模型了。

最近,谷歌联合ResNet作者何恺明、谢赛宁、NeRF先驱Jonathan T. Barron、 3D图形学名家Thomas Funkhouser,正式发布了Vision Banana。它向世界宣告:视觉AI终于不再需要那些臃肿的任务头了,理解,本质上只是生成过程中的一次「对齐」。

邓明扬现为 MIT 博士生,师从何恺明,主要研究生成模型。本科期间,他在 MIT 学习数学与计算机科学,也曾在 DeepMind 和 Meta 实习。更早之前,他曾获得 IMO 金牌和 IOI 金牌。2026 年,他以第一作者发表了 Drifting Models,尝试探索一种不同于传统路径的生成建模思路。

GeoPT提出了一种全新的动力学提升预训练范式,通过合成动力学(Synthetic Dynamics)将静态几何“提升”到动态空间,让模型在无标签数据上通过学习粒子轨迹演化来获取物理直觉。
训练一个生成模型是很复杂的一件事儿。 从底层逻辑上来看,生成模型是一个逐步拟合的过程。与常见的判别类模型不同,判别类模型通常关注的是将单个样本映射到对应标签,而生成模型则关注从一个分布映射到另一个分布。

刚刚,何恺明团队提出全新生成模型范式漂移模型(Drifting Models)。