ICSE 2026杰出论文 | 突破代码模型真实工程落地瓶颈,北大团队提出SEAlign对齐框架:显著提升软件工程智能体决策质量
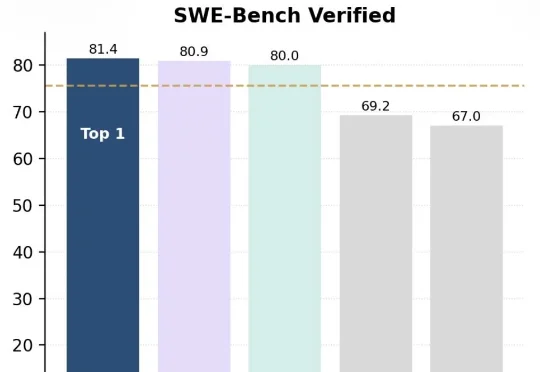
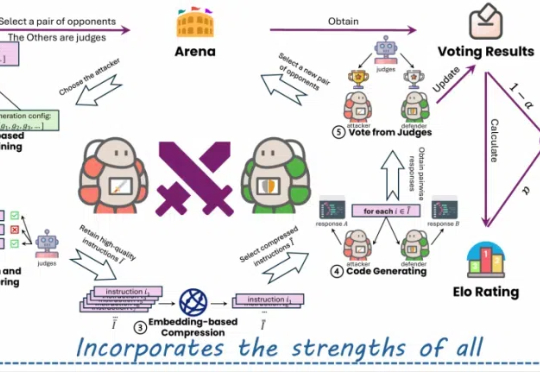
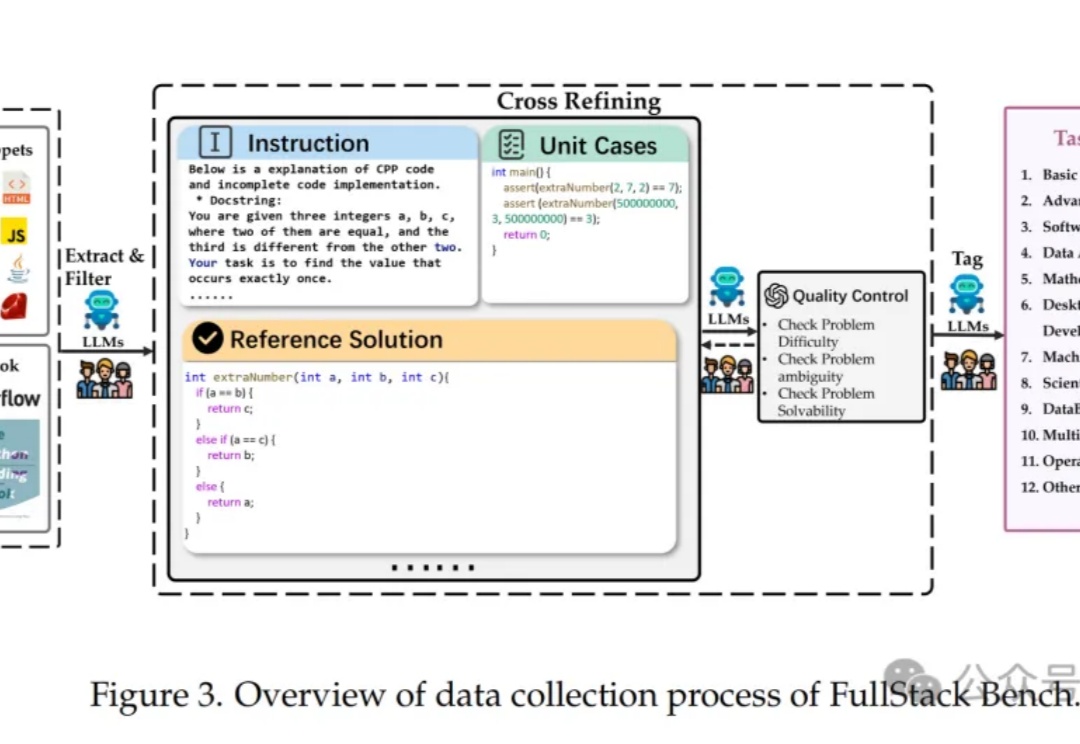
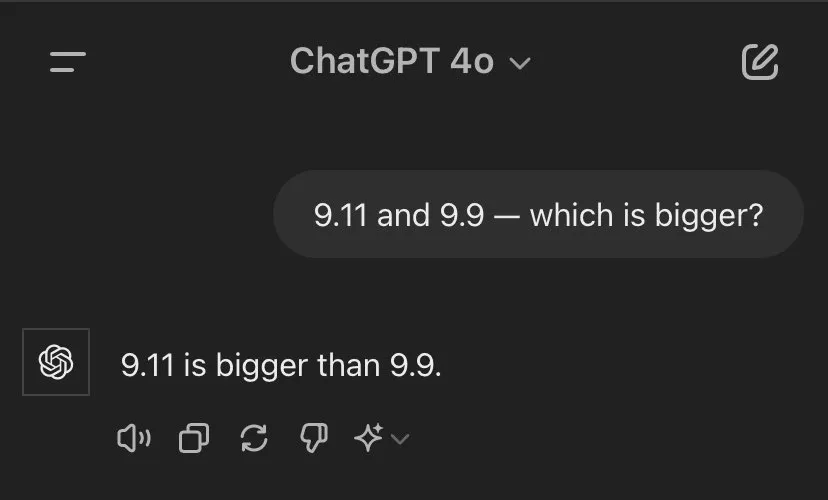
ICSE 2026杰出论文 | 突破代码模型真实工程落地瓶颈,北大团队提出SEAlign对齐框架:显著提升软件工程智能体决策质量在代码大模型和代码智能体技术快速发展的今天,一个日益凸显的现象是:能够在经典代码生成基准上取得优异成绩的模型,一旦被放入真实软件工程环境中,表现却往往大幅下滑。
来自主题: AI技术研报
6609 点击 2026-05-07 15:02