# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
又一个中国新模型被推到聚光灯下,刷屏国内外科技圈。
IQuest-Coder-V1模型系列,看起来真的很牛。
在最新版SWE-Bench Verified榜单中,40B参数版本的IQuest-Coder取得了81.4%的成绩,这个成绩甚至超过了Claude Opus-4.5和GPT-5.2(这俩模型没有官方资料,但外界普遍猜测参数规模在千亿-万亿级)。
Oh~Tiny Core, Titan Power。
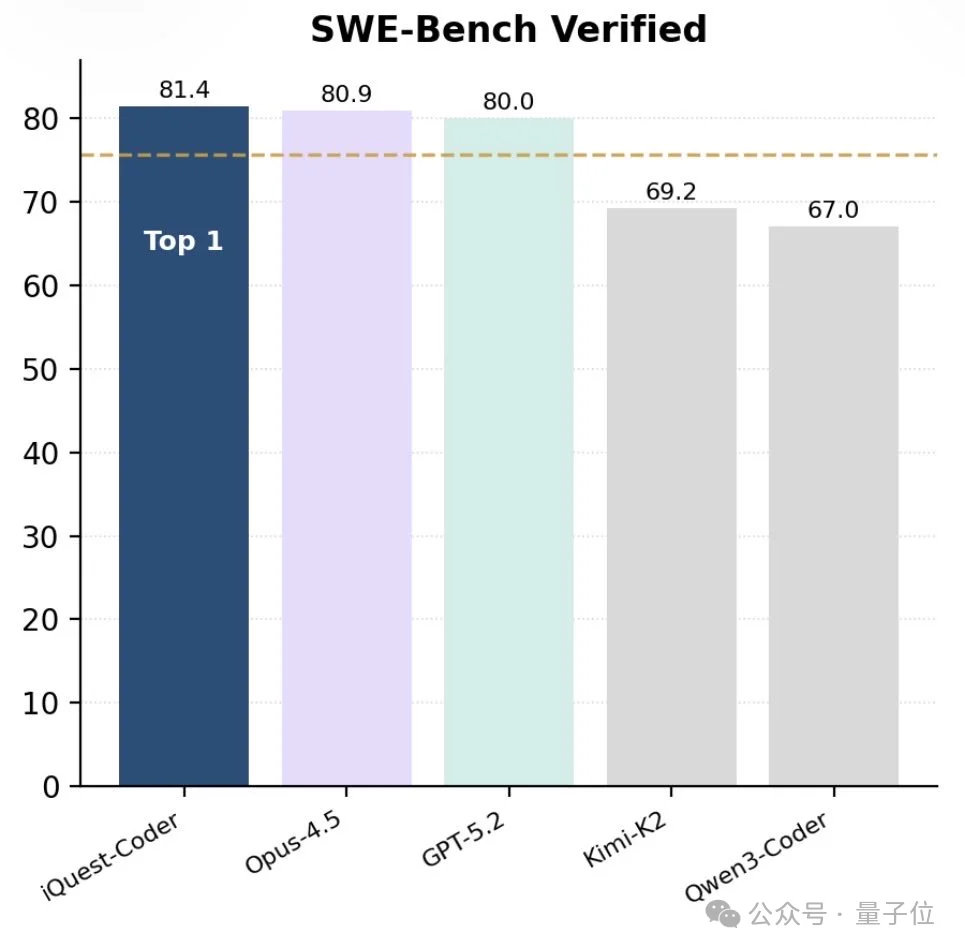
好,看到这里我盲猜很多人肯定已经开始边摇头边笑了。
毕竟这年头,benchmark的权威犹在,但说服力似乎已经大不如前了。
那咱们就看看这个模型跑出来的case——
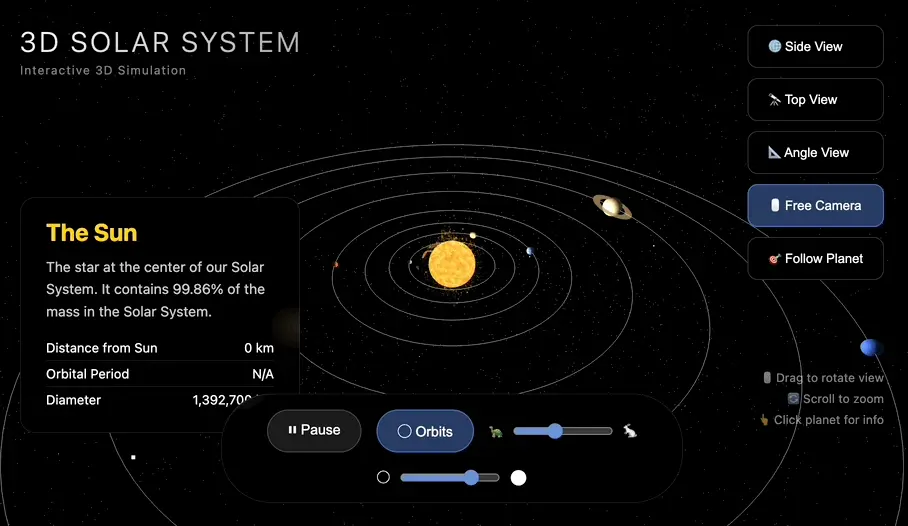
Prompt:编写一个网页来展示一个逼真的太阳系模拟。
然后你将得到:

可以自由切换各种视角,让画面暂停、放大,调整公转速度也ok。
选中具体的行星,还会跳出相应的名字和简单介绍。
目前,这套代码大模型系列已经在GitHub和抱抱脸上开源。
有一个重点一定要划!!!
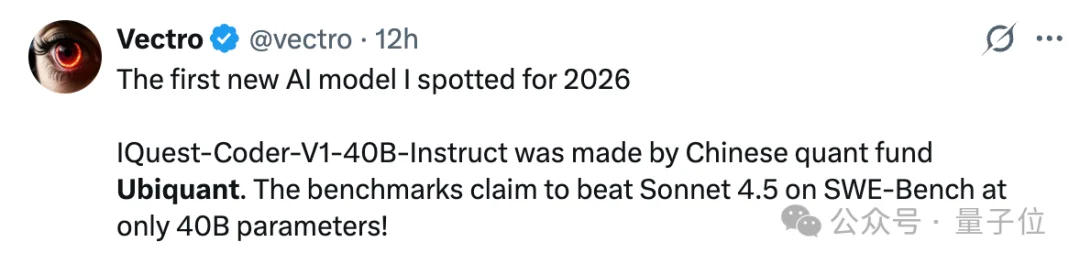
这个模型团队IQuest,和DeepSeek团队一个路数,都出自中国的量化私募。
背后公司就是北京版幻方量化——九坤投资。
(两家公司都是业内公认的量化私募头部)
𝕏、Reddit等平台上,关于IQuest-Coder的消息和对中国量化公司杀入AI模型战场的讨论已经满天飞了。
有网友一脸unbelievable地问出了令他诧异的问题:
Ok,一起来看看这套模型的详细情况吧~
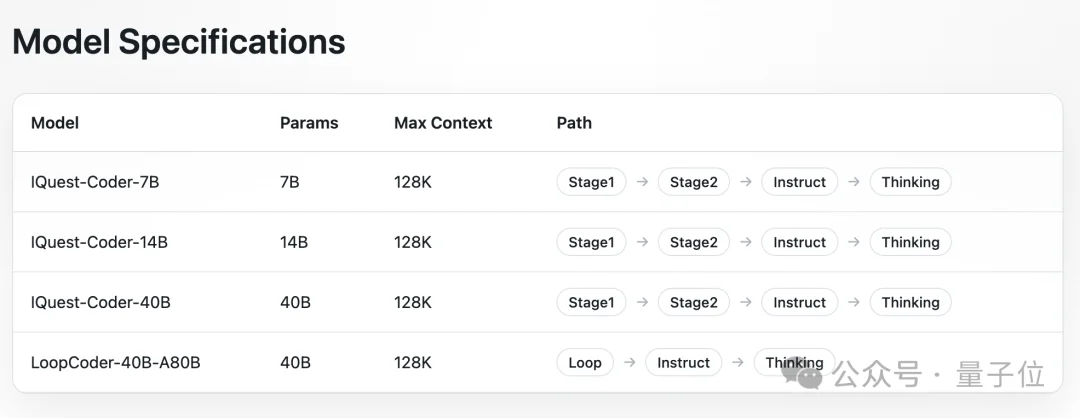
从定位上看,IQuest-Coder-V1是一套覆盖多个参数规模与使用场景的家族版本,专注于代码生成、代码理解与软件工程任务的模型系列。
参数有7B、14B和40B的,每个规模均提供Instruct和Thinking两种版本。
其中,Instruct偏向指令跟随与工程使用,更高效;Thinking强化复杂推理和多步问题拆解,响应时间更长。
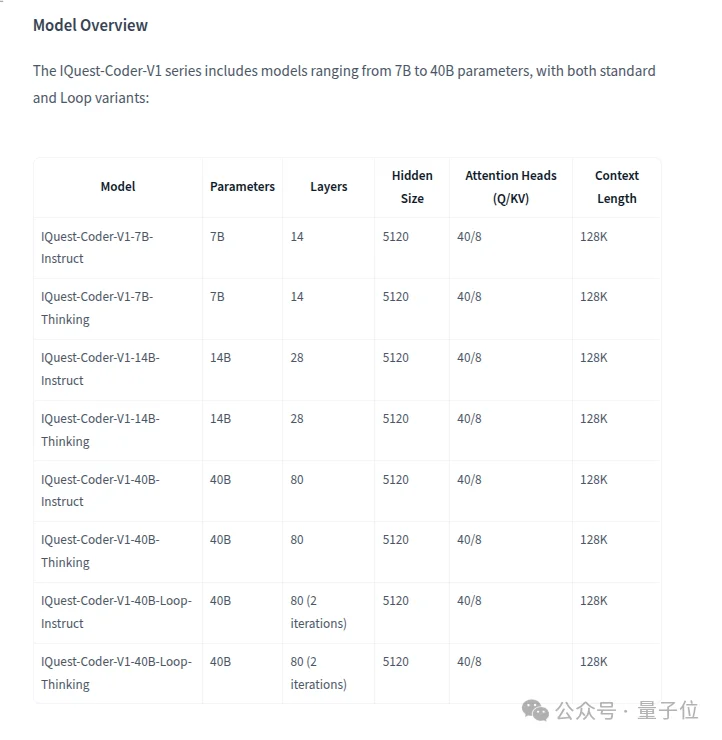
特别提醒大家注意一下,40B参数规模的IQuest-Coder-V1额外提供了Loop版本,用于探索更高的参数利用效率。
与计算成本相似的模型相比,IQuest-Coder-V1-40B-Loop的HBM和KV Cache开销显著降低,而吞吐量大幅提升。
仅增加约5%的训练成本,Loop架构下,40B模型达到数百亿参数MoE模型的水平。

在架构设计上,IQuest-Coder-V1系列强调了“工程友好”和“长上下文可用性”。
官方在GitHub上给出的四点架构特性分别是:
首先说说GQA的引入。
通过减少KV头数量来降低推理阶段的显存占用和计算压力,对长上下文场景超级友好。
其次,模型原生支持128K上下文长度。这就让模型有能力直接处理完整代码仓库、跨文件依赖以及大规模工程上下文。
第三,76800个token的词表大小,更贴近真实代码环境中频繁出现的标识符、路径名和符号组合。
最后,在Loop变体中,模型采用了具有跨两次迭代共享参数的循环Transformer设计,用重复计算换取更高的参数利用率,在不线性扩大模型规模的前提下提升性能。
作者刻意指出,这和早期Parallel Loop Transformer不同,去掉了token shifting和inference trick,更强调推理阶段的稳定性。
这些特性组合在一起,有利于模型在真实软件工程场景中跑得更好。
来看官方展示的更多case。
Prompt 1:构建一个粒子-文本动画,满足以下要求。

Prompt 2:构建一个实时像素沙盒游戏。
通过按钮切换沙子、水、石头和酸液;在画布上涂画可生成具有不同颜色的元素;大规模更新依然流畅;元素会自然下落并流动。

Prompt 3:构建一个完整的单文件HTML5 Canvas太空射击游戏,具有复古霓虹美学和明显的战斗反馈。
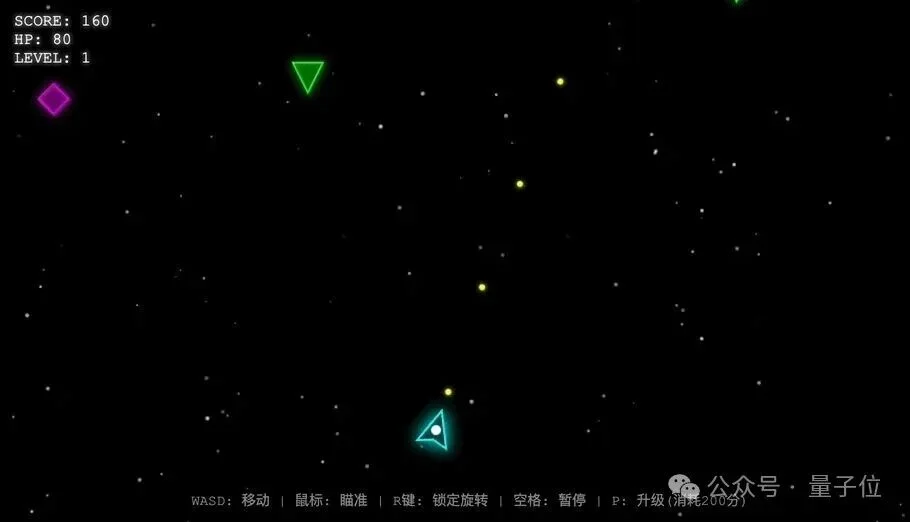
Prompt 4:基于鸟群算法的仿生鸟/鱼群体模拟,拥有150个以上的自主Agent,有实时调节功能。

IQuest-Coder的训练流程如下——
预训练阶段先用通用数据和大规模代码数据打底,然后通过高质量代码annealing强化基础代码表征。
中期训练阶段第一次明确引入reasoning、agent trajectory和长上下文代码,并且分32K和128K两个尺度逐步推进。
最终post-training阶段,模型被明确分流成instruct路线和thinking路线,分别用不同目标函数和RL方式收敛。
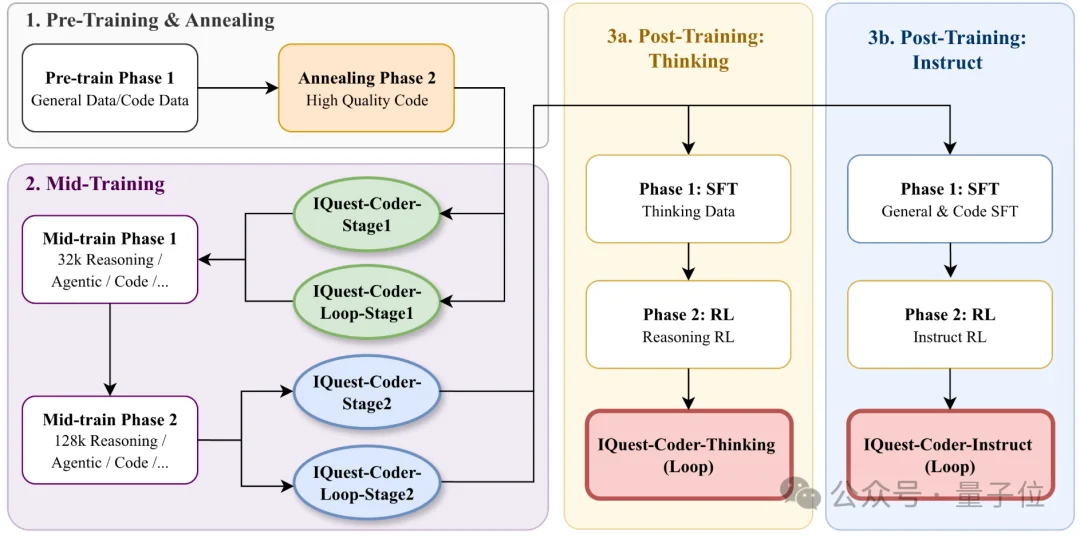
官方强调,IQuest-Coder-V1系列采用了与传统单一静态源代码训练不同的训练策略。
称之为code-flow multi-stage training。
与大量代码模型侧重从静态代码片段中学习不同,这套方法强调从代码的演化过程中学习。
团队专门设计了基于项目生命周期的triplet数据构造方式,用 (R_old, Patch, R_new) 这样的结构,让模型看到稳定期代码、变更内容以及变更后的结果。
而且刻意避开项目早期和后期,只取40%–80%生命周期区间。
这一步实际上把“软件工程经验”显式编码进了训练数据里。
所以模型看到的并不只是某一时刻的完成态代码,还包括修改前后的差异、提交历史中的逻辑变化,以及真实工程中反复试错和修正的痕迹。
也就是说模型被训练得能够捕捉软件逻辑的动态演变。
不少网友猜测,这就是IQuest-Coder-V1在多个软件工程类评测中表现突出的重要原因之一。
这套模型成绩确实亮眼。
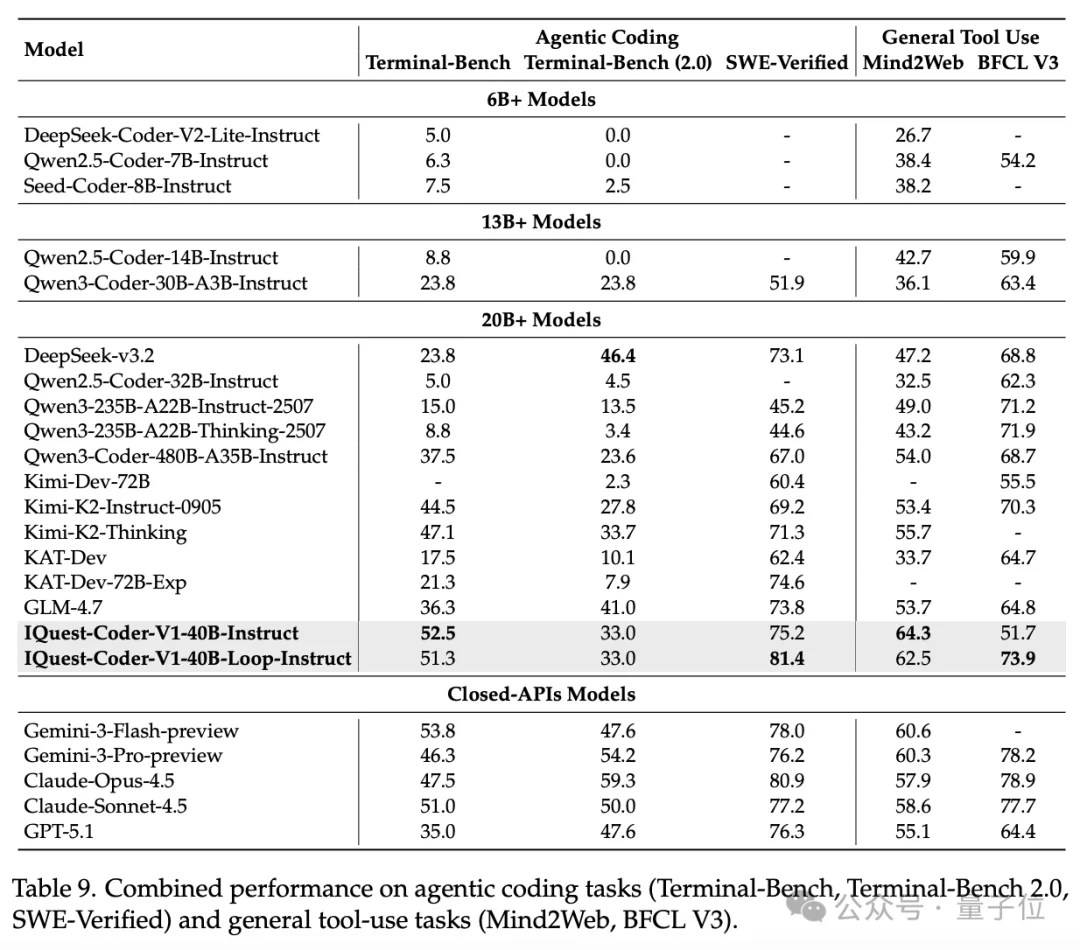
下面这张图体现得更直观一点,IQuest-Coder在八个代码、Agentic相关榜单上都独占鳌头。
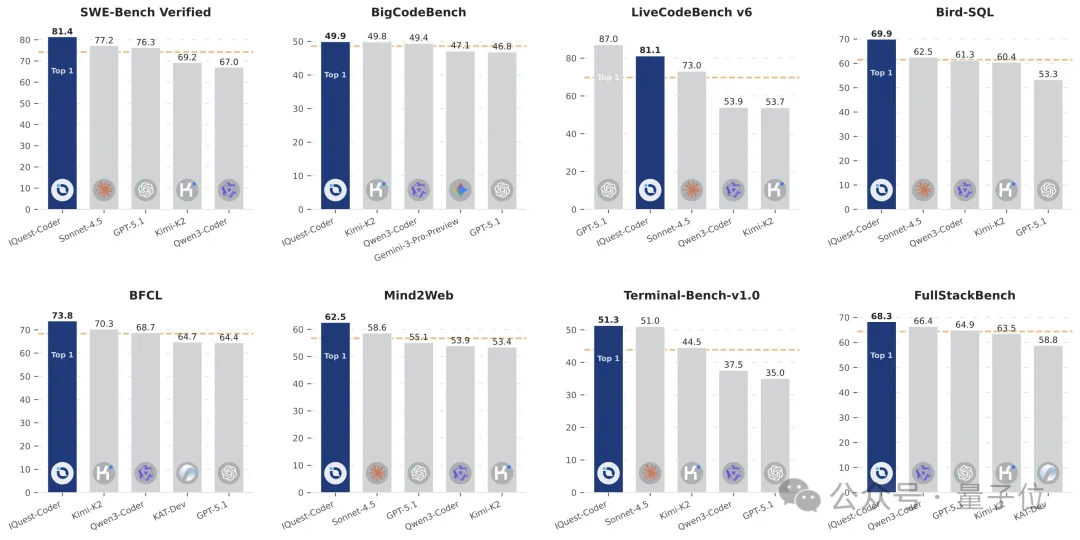
不过,GitHub上白纸黑字写着,模型可以生成代码,但不能执行,始终在沙盒环境中验证输出结果。
部署方面,官方信息显示,不管是基础版本还是Loop版本,都支持单卡H20推理。
其Int4版本可在单张消费级3090/4090 GPU上部署。
有网友表示,非Loop版本的模型似乎采用的是阿里Qwen2的架构。
随着关注度上升,质疑也同步出现。

好,最后我们来认识一下IQuest-Coder背后的公司,九坤投资(Ubiquant Holding Limited)。
公司成立于2012年,是中国较早一批专注量化投资和高频交易的私募机构之一,目前管理规模在数百亿元人民币,和幻方同属于公认的国内量化私募头部公司。
九坤主要办公地在北京,3周前开设了新加坡办公室。
联合创始人王琛,2000年考入清华大学,获得数学物理学士学位和理论计算机博士学位,博士期间师从图灵奖得主姚期智院士。
博士毕业后,王琛就职于美国顶级对冲基金Millennium,后创业担任九坤投资联合创始人、CEO。
联合创始人姚齐聪,2002年考入北京大学数学系,获得数学学士和金融数学硕士学位。
硕士毕业后进入Millennium,后与王琛共同创业,主要负责九坤投研体系搭建、量化策略开发和风险管理,被视为公司策略和风控体系的核心设计者之一。
九坤的投研与技术团队人数超过百人,90%以上毕业于清华、北大、复旦、斯坦福等国内外知名高校,博士占比超过60%。
公开信息显示,这家公司目前也倾向于从全球顶尖高校招募具有计算机、数学、物理、统计学等背景的应届毕业生。
在AI领域,幻方更早凭DeepSeek站到台前。
不过查询有关资料发现,此前九坤也很注重AI技术这一块。
目前,九坤的IT和算力建设位居国内量化机构前三,并建立了数据实验室(DATA LAB)、人工智能实验室(AI LAB)等多个前沿实验室。
本次发布的IQuest-Coder就出自其发起设立的独立研究平台至知创新研究院。
倒也不全是为了把AI用在金融市场预测和交易决策啦——前段时间(2025年12月16日),九坤已经推出过通用推理模型URM。
该模型在ARC-AGI正确率为53.8%,当允许多次尝试时,URM的成功率能达到85%以上;在更困难的ARC-AGI 2上也拿到了16.0%。
Paper最后附上了IQuest-Coder团队的成员名单。

挺长的,就不一一介绍了。
不过我们发现这篇paper的核心作者层,和《Scaling Laws for Code》《CodeSimpleQA》《From Code Foundation Models to Agents and Applications》作者阵容重合度非常高。
所以这里稍微展开介绍一下Core Contributor的几位成员。
(注:IQuestLab团队成员很多没有公开个人档案,我们这里放出可寻找到的公开资料)
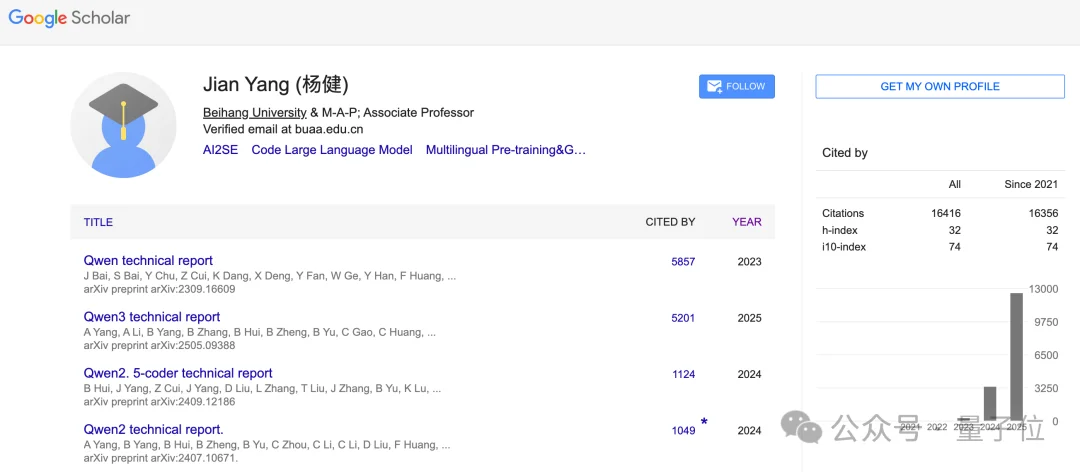
Jian Yang,谷歌学术被引量超过1.6万。
此前应该在Qwen 2.5和Qwen 3团队待过很长一段时间,2025年起开始在九坤投资发表论文。
Zhengmao Ye,本科毕业于西南交通大学,在四川大学获得计算机科学硕士学位。
此前,他曾在华为和商汤科技担任过技术工作人员。

你没看错,8位Core Contributor就找到了2位的公开资料,真的尽力了.gif
另外,paper的通讯作者,是九坤人工智能实验室首席研究员和负责人Bryan Dai。

Paper地址:
file:///Users/hengknows/Downloads/IQuest_Coder_Technical_Report%20(1).pdf
参考资料:[1]https://x.com/zephyr_z9/status/2006579658972868988?s=20[2]https://github.com/IQuestLab/IQuest-Coder-V1?tab=readme-ov-file[3]https://iquestlab.github.io/#/[4]https://www.reddit.com/r/LocalLLaMA/comments/1q0x19t/anyone_tried_iquestcoderv1_yet_the_40b_numbers/
文章来自于微信公众号 “量子位”,作者 “量子位”


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
