Kimi最强编程模型Kimi K2.7 Code来了:Token消耗直降30%,过度思考有救了,附一手实测
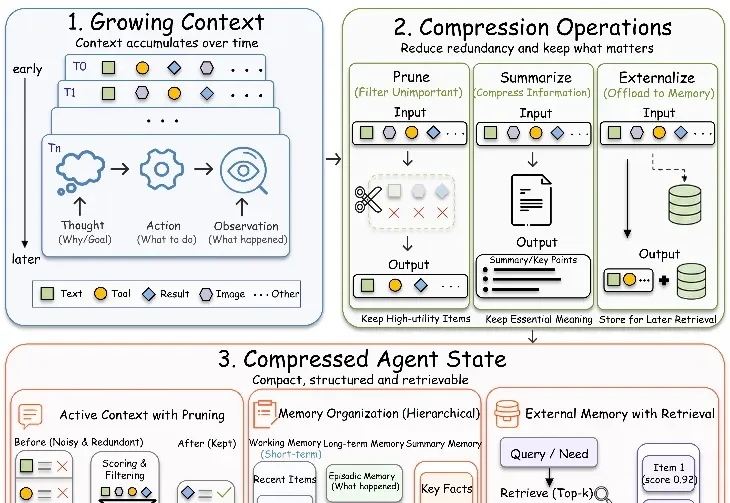
Kimi最强编程模型Kimi K2.7 Code来了:Token消耗直降30%,过度思考有救了,附一手实测今天,月之暗面发布并开源Kimi K2.7 Code编程模型,参数量达1.1万亿,提供256K上下文窗口。这一模型重点提升了长上下文编程场景的指令遵循能力、长程编程任务的性能表现,并且大幅改善了在长程任务中的过度思考倾向,平均token消耗减少30%。
来自主题: AI资讯
10075 点击 2026-06-13 00:31