# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
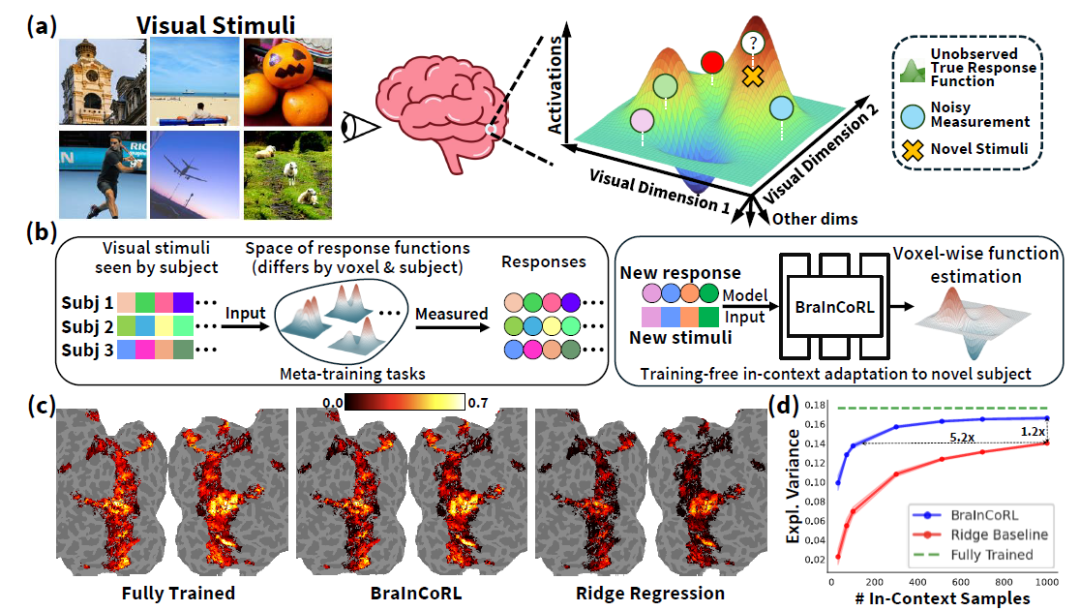
人类高级视觉皮层在个体间存在显著的功能差异,而构建大脑编码模型(brain encoding models)—— 即能够从视觉刺激(如图像)预测人脑神经响应的计算模型 —— 是理解人类视觉系统如何表征世界的关键。传统视觉编码模型通常需要为每个新被试采集大量数据(数千张图像对应的脑活动),成本高昂且难以推广。尽管现有方法可利用预训练视觉模型(如 CLIP )提取图像特征,并通过线性回归拟合脑响应,这类模型仍严重依赖大量被试内数据,在少样本甚至零样本条件下难以快速适应新个体,限制了其在临床、个性化神经科学等现实场景中的应用。
为解决这一挑战,BraInCoRL(Brain In-Context Representation Learning)提出一种基于元学习的上下文Transformer跨被试脑编码模型,仅凭少量示例图像及其对应的脑活动数据,即可无需微调地预测新被试在面对全新图像时的脑响应。该模型在多个公开fMRI数据集上表现出卓越的数据效率与泛化能力,甚至可跨扫描仪、跨协议进行有效预测。
本工作发表于 NeurIPS 2025 中的文章《Meta-Learning an In-Context Transformer Model of Human Higher Visual Cortex》。

人类高级视觉皮层(如梭状回面孔区 FFA、海马旁位置区 PPA 等)对语义类别(人脸、场景、食物等)具有选择性响应。尽管这些区域在被试间位置大致一致,但精细的功能组织存在显著个体差异 —— 这使得为每个新被试构建高精度编码模型必须依赖大量功能磁共振成像(fMRI)扫描(通常需数千图像),成本极高。
当前主流方法多采用“图像特征 + 线性回归”的范式,虽在单个被试上表现良好,但无法跨被试泛化,必须为每位新用户重新训练模型。近期一些工作尝试引入 Transformer 架构建模多被试数据,但仍需在新被试数据上进行微调,未能真正摆脱对大量个体数据的依赖。
针对这一瓶颈,本文提出一种全新的建模范式:将每个脑体素(voxel)视为一个独立的、从视觉刺激到神经响应的响应函数。fMRI 测量仅提供该函数在有限输入下的带噪采样,而训练目标是从这些稀疏观测中推断出一个可计算、可泛化的映射。基于元学习和上下文学习范式,本文提出一种全新的BraInCoRL脑编码架构,在训练阶段从多被试数据中学习视觉皮层响应的共享结构;在测试阶段,仅需提供极少量(如 100 张)新被试的图像-脑响应对作为上下文,即可无需任何微调,直接生成适用于该被试的体素级编码器,并准确预测其对全新图像的神经活动。
BraInCoRL 的核心思想是将每个体素的视觉响应建模为一个独立的函数推断任务,并将其置于元学习(meta-learning)与上下文学习(in-context learning, ICL)的统一框架下。

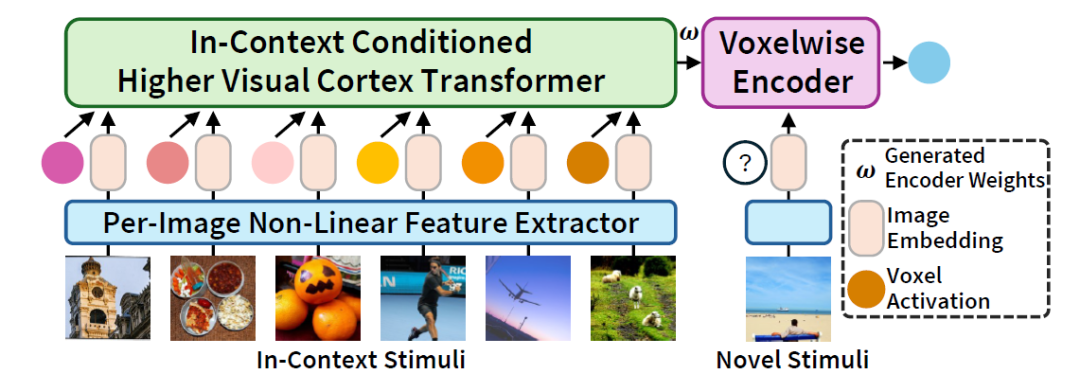
为实现这一目标,BraInCoRL 将每个体素视为一个元学习任务。在训练阶段,模型从多个被试的数千个体素中随机采样,通过 Transformer 学习跨被试、跨体素的视觉–神经映射共性,即学习一个通用的上下文推理算法。

此架构在训练时显式优化上下文学习能力,使模型学会如何从少量样本中推断出一个体素的响应函数。
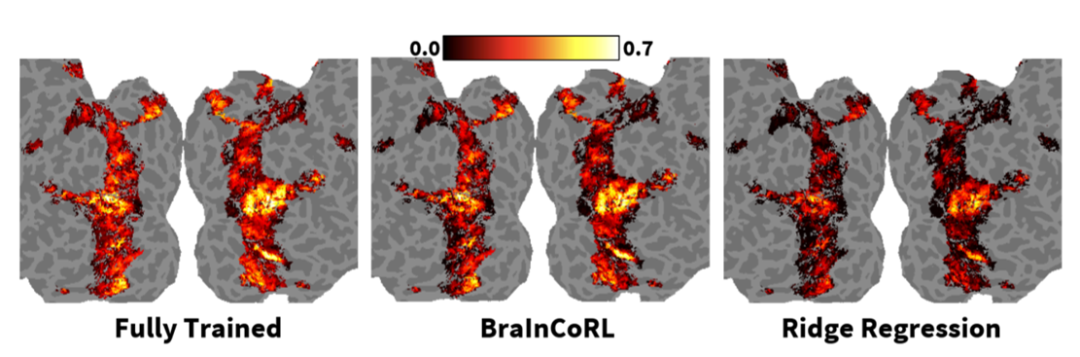
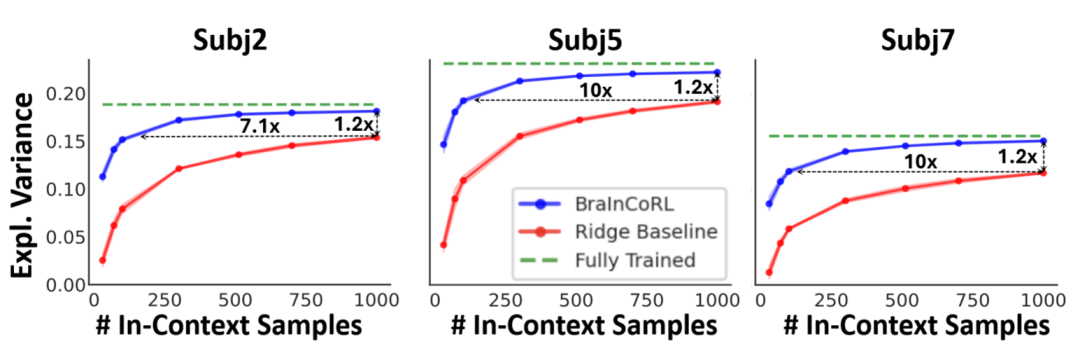
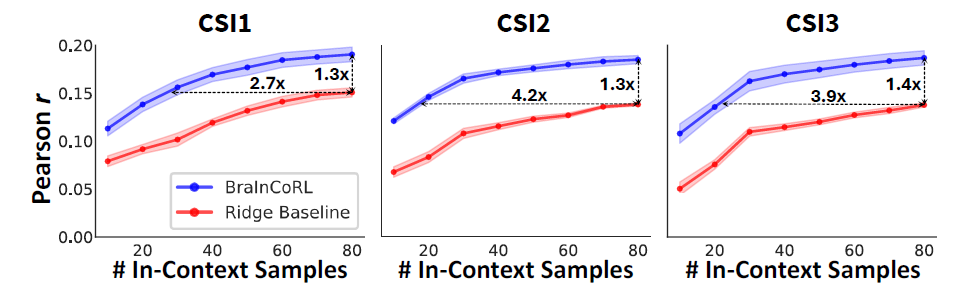
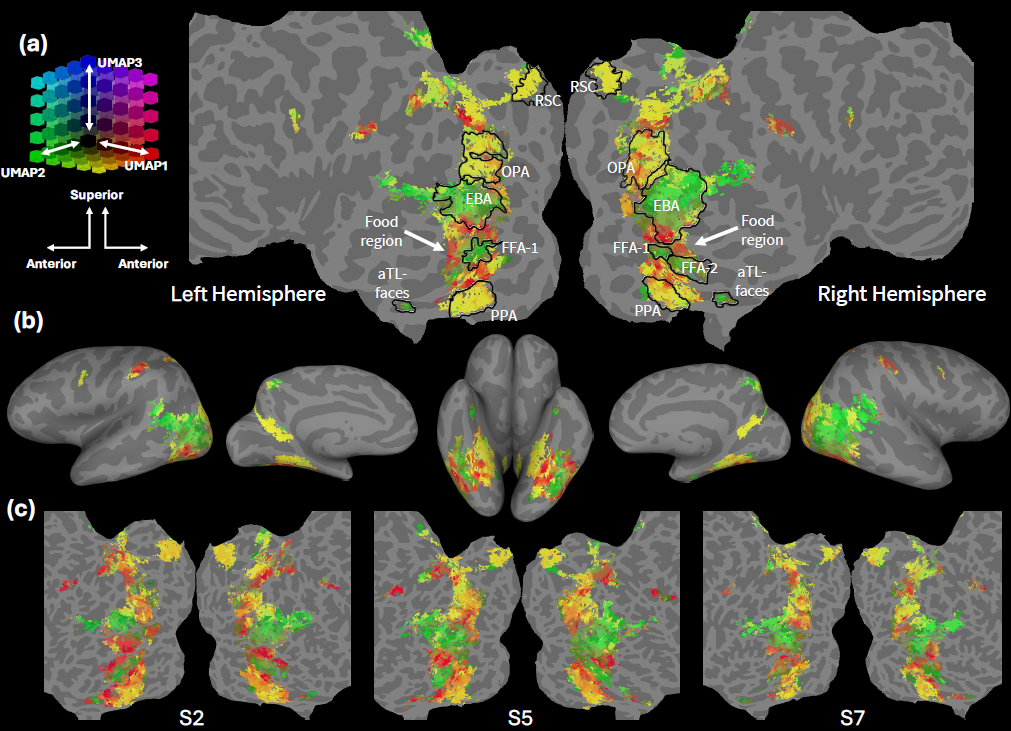


BraInCoRL 首次将上下文学习 (In-Context Learning) 引入计算神经科学,构建了一个无需微调、数据高效、可解释、支持语言交互的通用视觉皮层编码框架。该方法大幅降低了个体化脑编码模型的构建门槛,为未来在临床神经科学等数据受限场景中的应用开辟了新路径。
文章来自于“机器之心”,作者 “喻牧泉”。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
