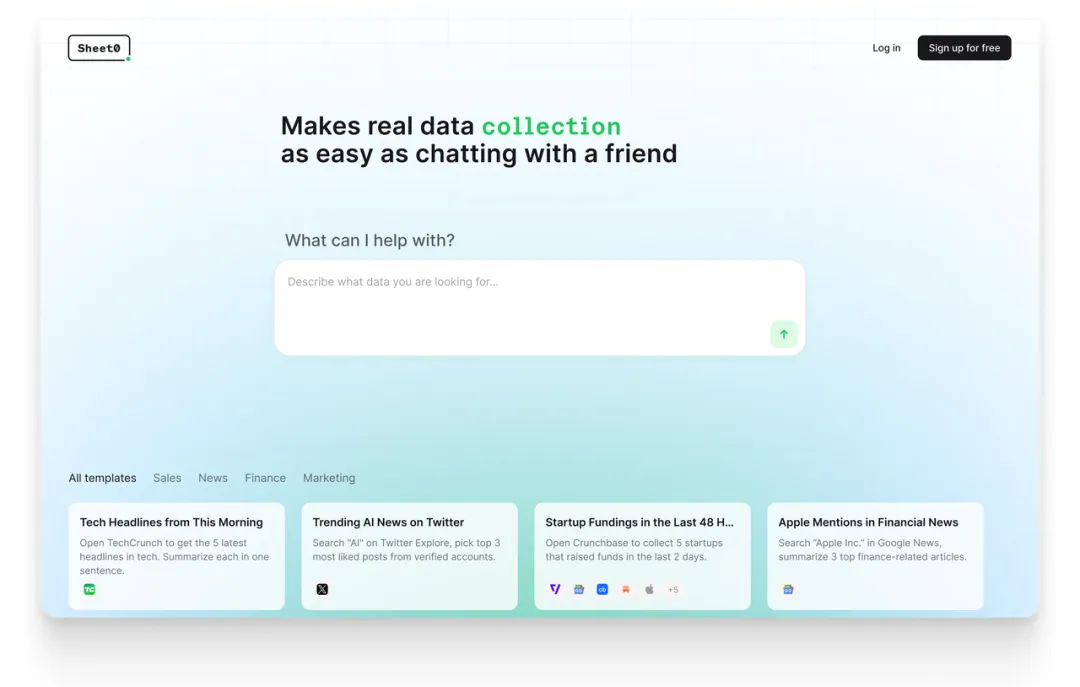
Sheet0.com王文锋,两人团队融资500万美元,要打造属于Agent的Google.com
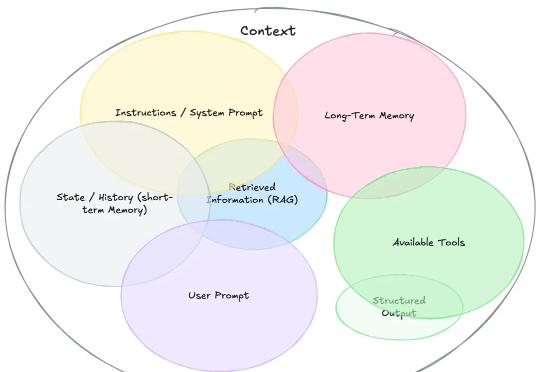
Sheet0.com王文锋,两人团队融资500万美元,要打造属于Agent的Google.com创始人王文锋作为连续创业者,在AI、基础软件与大规模分布式数据处理领域的近十年工作经验,让他在数据工程、上下文构建(Context Engineering)以及可组合系统架构上具备深厚功底。这不仅让 Sheet0 能在技术实现上跑得更快、更稳,也让他在市场节奏与产品定位上有着极为稀缺的超前判断力。
来自主题: AI资讯
10316 点击 2025-08-11 14:10