一码难求背后,能自己上线应用的AI产品野心多大?
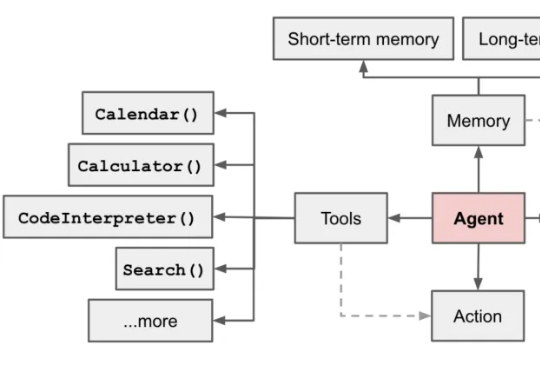
一码难求背后,能自己上线应用的AI产品野心多大?在过去很长一段时间里,科技圈似乎人均都成了“提示词工程师”,大家都在琢磨怎么用最精妙的语言驯服AI。但包括Andrej Karpathy在内的很多行业大佬已经开始反思了,他们认为,决定AI效果的关键,可能早就不是怎么问,而是你给AI喂了什么料。这个思路,就是最近越来越火的上下文工程(Context Engineering)。
来自主题: AI资讯
8434 点击 2025-07-23 09:39