
上下文记忆力媲美Genie3,且问世更早:港大和可灵提出场景一致的交互式视频世界模型
上下文记忆力媲美Genie3,且问世更早:港大和可灵提出场景一致的交互式视频世界模型要让视频生成模型真正成为模拟真实物理世界的「世界模型」,必须具备长时间生成并保留场景记忆的能力。然而,交互式长视频生成一直面临一个致命短板:缺乏稳定的场景记忆。镜头稍作移动再转回,眼前景物就可能「换了个世界」。
来自主题: AI技术研报
9136 点击 2025-08-21 11:25
 搜索
搜索
要让视频生成模型真正成为模拟真实物理世界的「世界模型」,必须具备长时间生成并保留场景记忆的能力。然而,交互式长视频生成一直面临一个致命短板:缺乏稳定的场景记忆。镜头稍作移动再转回,眼前景物就可能「换了个世界」。
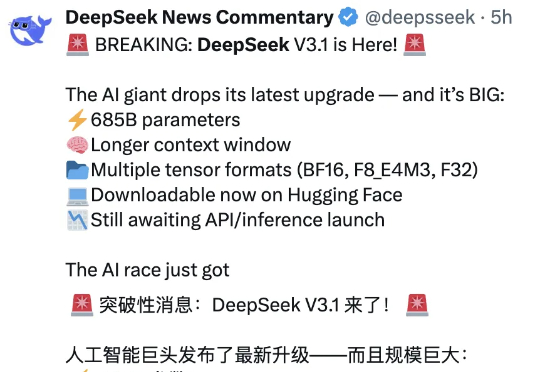
DeepSeek V3.1和V3相比,到底有什么不同?官方说的模模糊糊,就提到了上下文长度拓展至128K和支持多种张量格式,但别急,我们已经上手实测,为你奉上更多新鲜信息。

DeepSeek V3.1新版正式上线,上下文128k,编程实力碾压Claude 4 Opus,成本低至1美元。在昨晚,DeepSeek官方悄然上线了全新的V3.1版本,上下文长度拓展到128k。本次开源的V3.1模型拥有685B参数,支持多种精度格式,从BF16到FP8。
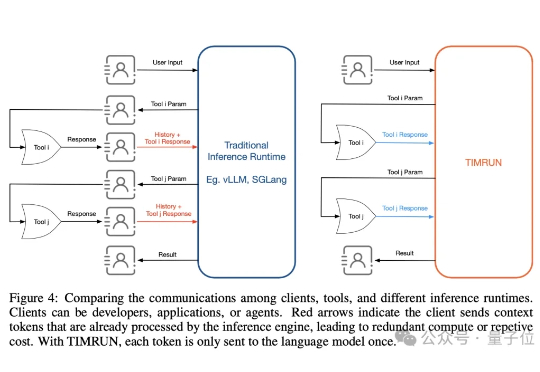
大模型的记忆墙,被MIT撬开了一道口子。 MIT等机构最新提出了一种新架构,让推理大模型的思考长度突破物理限制,理论上可以无限延伸。 这个新架构名叫Thread Inference Model,简称TIM。

没等到Deepseek R2,DeepSeek悄悄更新了V 3.1。官方群放出的消息就提了一点,上下文长度拓展至128K。128K也是GPT-4o这一代模型的处理Token的长度。因此一开始,鲸哥以为从V3升级到V 3.1,以为是不大的升级,鲸哥体验下来还有惊喜。
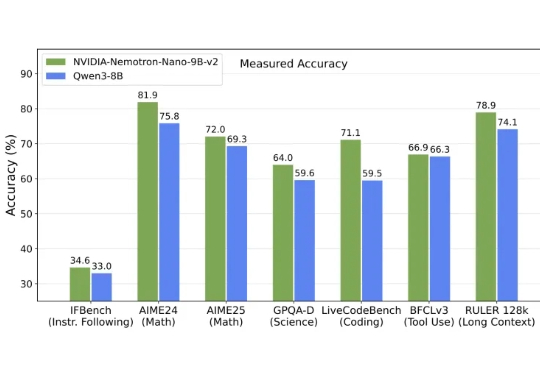
英伟达发布全新架构9B模型,以Mamba-Transformer混合架构实现推理吞吐量最高提升6倍,对标Qwen3-8B并在数学、代码、推理与长上下文任务中表现持平或更优。

在 AI 工具层出不穷的当下,很多人开始尝试用一个 AI 写故事、编脚本、润色文案。但对于日常需要写稿、整理内容的工作者来说,一个「替你写」的 AI,未必是最优解。幻觉、记忆、上下文,都是问题。
AI领域一度陷入“上下文窗口”的军备竞赛,从几千token扩展到数百万token。这相当于给了AI一个巨大的图书馆。但这些“百万上下文”的顶级模型,它究竟是真的“理解”了,还是只是一个更会“背书”的复读机?
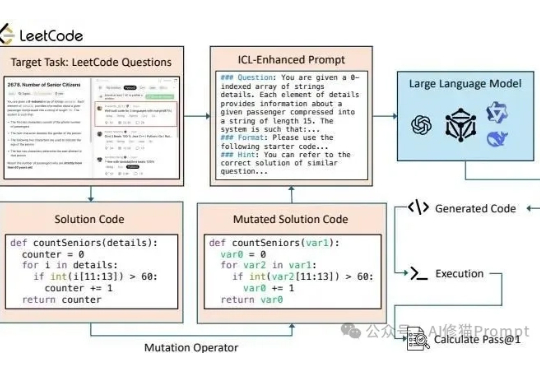
长久以来我们都知道在Prompt里塞几个好例子能让LLM表现得更好,这就像教小孩学东西前先给他做个示范。在Vibe coding爆火后,和各种代码生成模型打交道的人变得更多了,大家也一定用过上下文学习(In-Context Learning, ICL)或者检索增强生成(RAG)这类技术来提升它的表现。
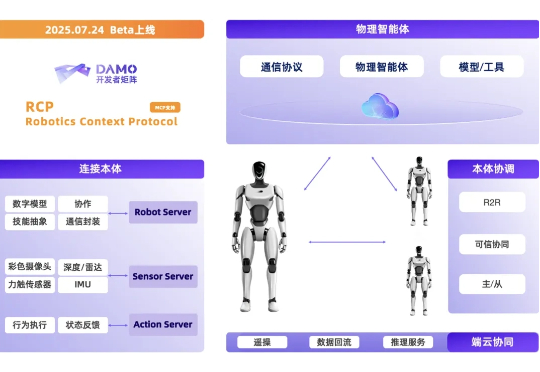
8 月 11 日,在世界机器人大会上,阿里达摩院宣布开源自研的 VLA 模型 RynnVLA-001-7B、世界理解模型 RynnEC、以及机器人上下文协议 RynnRCP ,推动数据、模型和机器人的兼容适配,打通具身智能开发全流程。