Kimi K2新模型来了!多项测试超Claude、审美超前代,免费可用
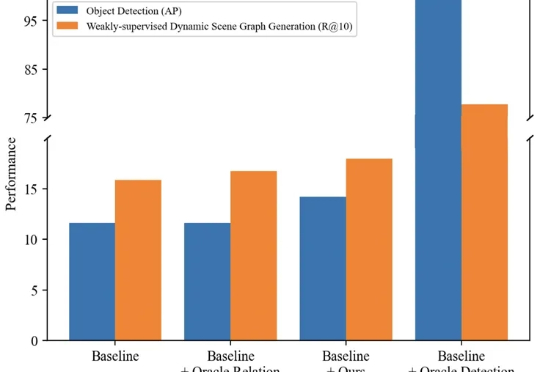
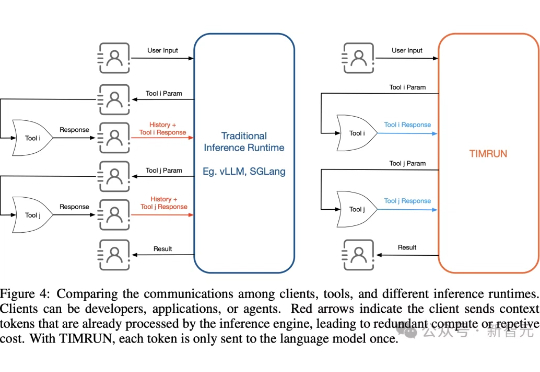
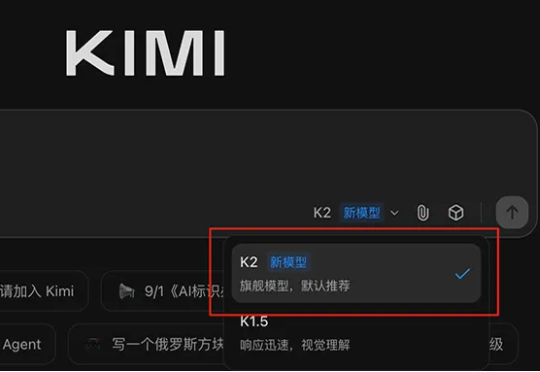
Kimi K2新模型来了!多项测试超Claude、审美超前代,免费可用智东西9月5日消息,刚刚,大模型独角兽月之暗面发布新模型Kimi K2-0905,目前,Kimi应用和网页版中的K2模型已全量升级到Kimi K2-0905。该模型的核心升级点为Agentic Coding能力增强、支持256K上下文、API支持高达60-100Token/s的输出速度、支持Claude Code。
来自主题: AI资讯
11014 点击 2025-09-05 16:54