三个月,一场必然失败的Tokenmaxxing
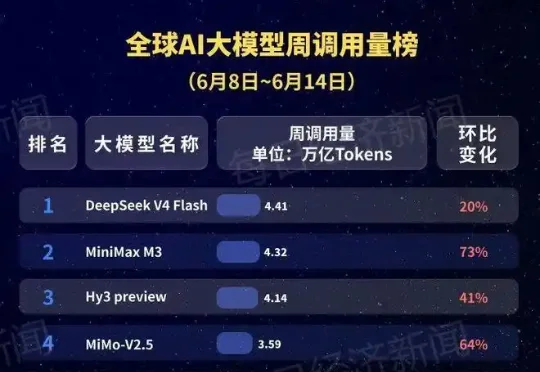
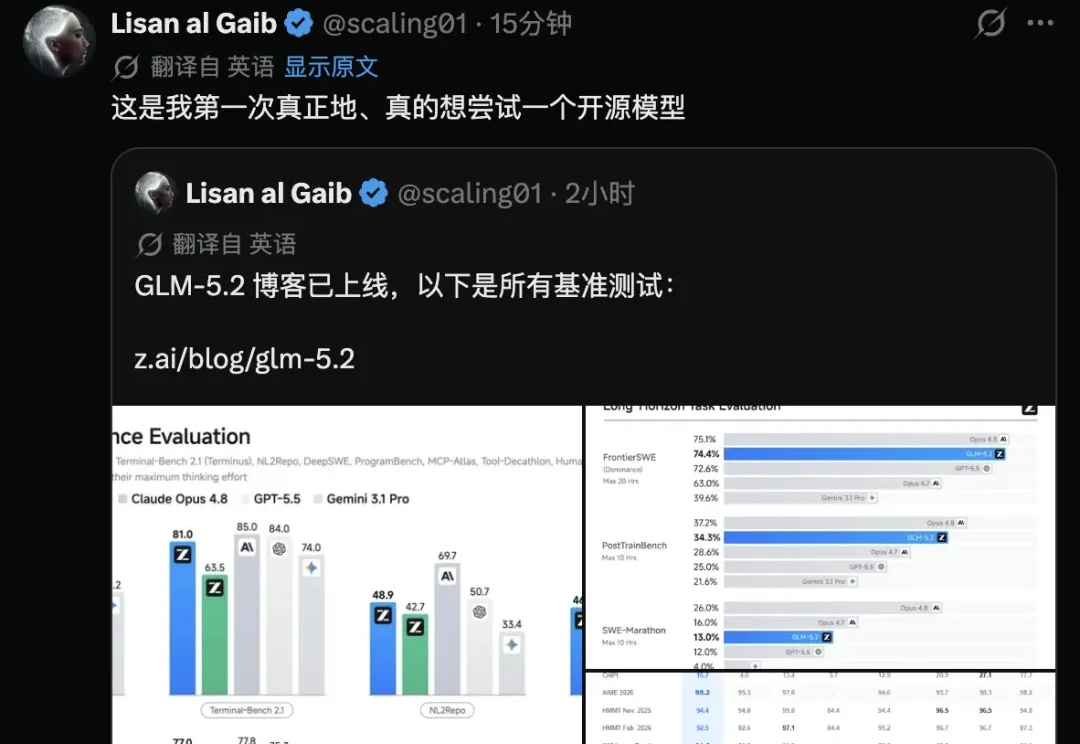
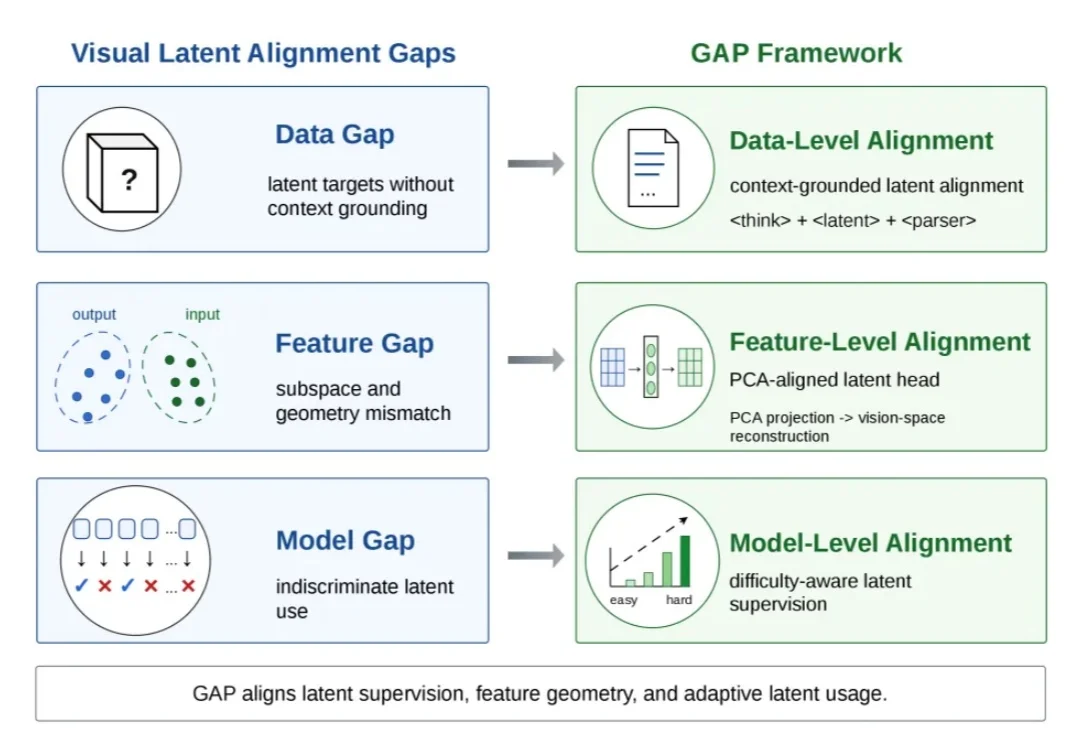
三个月,一场必然失败的Tokenmaxxing早在3月20日,纽约时报的凯文·罗斯就发现了在硅谷开发者中,出现了一种叫做 Tokenmaxxing的现象。这个现象最早出现在OpenAI、Anthropic等前沿模型开发公司。OpenAI 的工程师一周用了 2100 亿个token,大概是 33 个维基百科的量;Claude Code 的工程师则一个月单人可以烧15万美元token。
来自主题: AI资讯
8296 点击 2026-06-20 14:12