
本周 AI 项目推荐:Link、Agentic Wallets、Token Pay......Token支付底座长啥样
本周 AI 项目推荐:Link、Agentic Wallets、Token Pay......Token支付底座长啥样什么是AI原生支付?随着全世界个体token的消耗量猛增,越来越多的大玩家和初创公司开始瞄准AI支付机制和基础设施的问题。
来自主题: AI资讯
7483 点击 2026-06-29 10:20
 搜索
搜索
什么是AI原生支付?随着全世界个体token的消耗量猛增,越来越多的大玩家和初创公司开始瞄准AI支付机制和基础设施的问题。
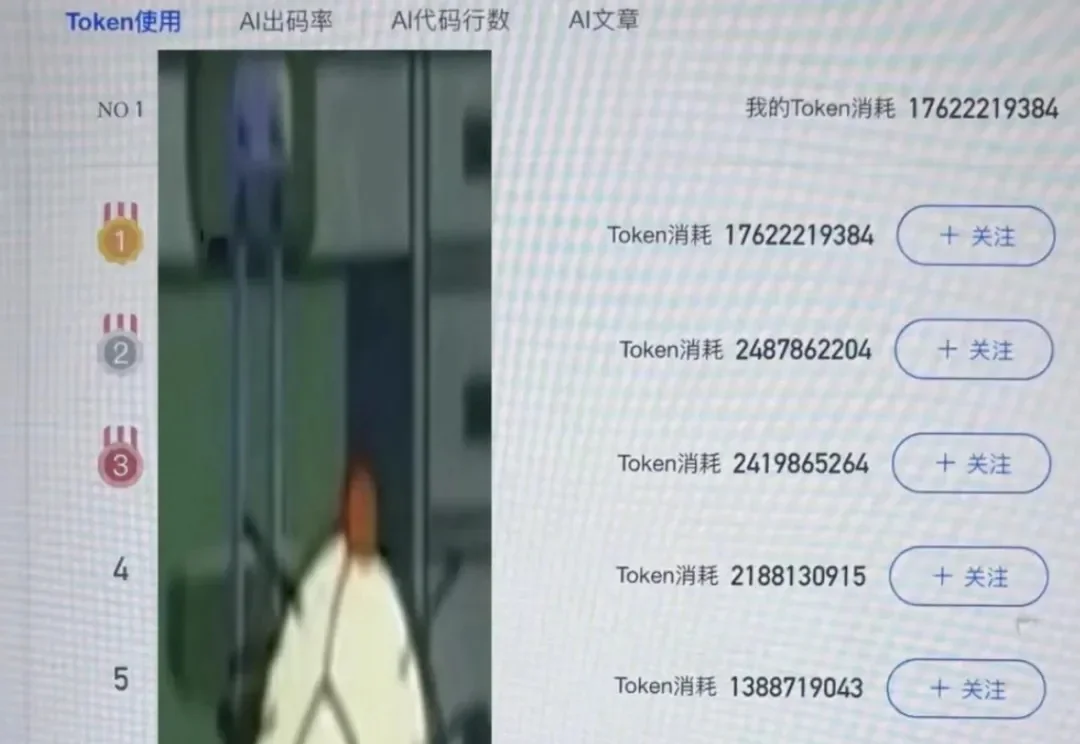
不用够token会被骂,AI生成率必须大于80%,谁在强制打工人用AI?

AI的「大火」一来,Token作为计算燃料,正变得和石油一样珍贵。然而AI繁荣下,一种抽象的景象正在程序员间发生:大厂员工Token用不完,网上求问「如何能快速大量消耗」;小公司程序员却在绝地求生,自费买Token,甚至费劲心思在网上挖免费Token上班。
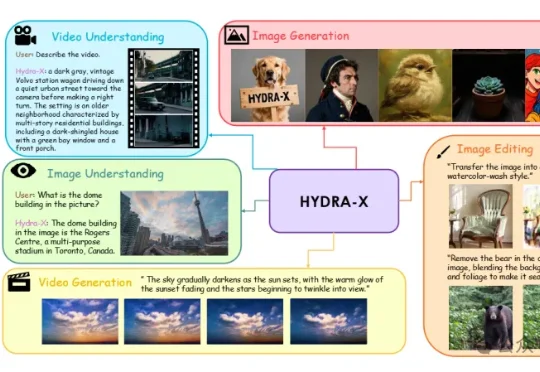
南大王利民团队&腾讯混元的HYDRA系列(HYDRA,HYDRA-X)工作挑战了这个惯例,用一个基于ViT的统一视觉Tokenizer,帮助原生多模态模型更好地“看懂”和“创作”。训练一个基于ViT的Unified Tokenizer,使其同时具有理解和生成的能力,进而同时作为理解和生成的Autoencoder,来支持原生多模态模型(Unified Multimodal Models)的训练。

上周一个做电商的朋友找我吐槽。 他说公司上了AI客服,预算每月5000块。第一个月账单出来:1万2。第二个月:1万8。第三个月他直接把系统关了。

扩散模型又被玩出新花样了。

180 万亿。这是截至今年 6 月,豆包大模型的日均 token 调用量。

大厂把AI按token租给你,River AI想让你直接拥有它,这是Babuschkin出走xAI后打出的第一张牌。
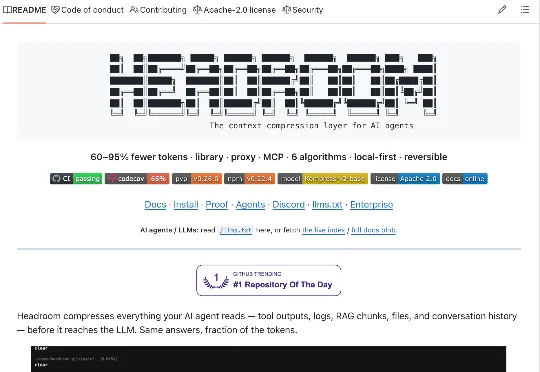
一个开源的省Token工具Headroom,火了!公开页面显示Headroom已有4万多个star,最新版本是v0.26.0。一个“上下文压缩层”工具能到这个热度,已经说明很多问题。
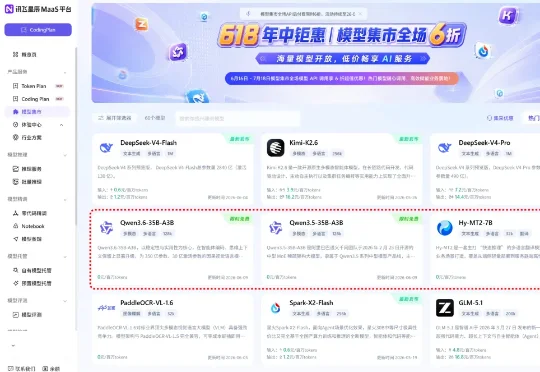
前几天听说讯飞星辰 MaaS 平台在做活动,一些模型可以限时免费调用,我第一反应就是先领了再说。这次活动限时开放了 Qwen3.6-35B-A3B 和 Qwen3.5-35B-A3B 两个模型的免费调用权益,新老用户都可以参与。