
刚刚,Fable 5全球复活!限时7天,额度砍半
刚刚,Fable 5全球复活!限时7天,额度砍半刚刚,Anthropic正式官宣:Fable 5回来了!就这简单的一句话,让全网奔走相告。苦等19天,所有人像过年一样冲回Claude,就为了亲眼确认那个熟悉的名字重新亮起。而且千万注意,一旦额度达上限,Fable 5跑起来的Token消耗远超Opus 4.8。
来自主题: AI资讯
9034 点击 2026-07-02 09:31
 搜索
搜索
刚刚,Anthropic正式官宣:Fable 5回来了!就这简单的一句话,让全网奔走相告。苦等19天,所有人像过年一样冲回Claude,就为了亲眼确认那个熟悉的名字重新亮起。而且千万注意,一旦额度达上限,Fable 5跑起来的Token消耗远超Opus 4.8。

大模型公司在港股热度正酣,现在,卖Token的公司也开始冲刺了。硅基流动已向港交所提交上市申请,剑指港股「AI Token工厂第一股」。此前,硅基流动已完成7轮融资,估值77.4亿元。阿里、美团、商汤、蔚来、智谱等产业方和明星AI投资机构均有押注。

2026年,具身智能赛道的融资热度仍在持续,但投资人的提问方式已经变了。
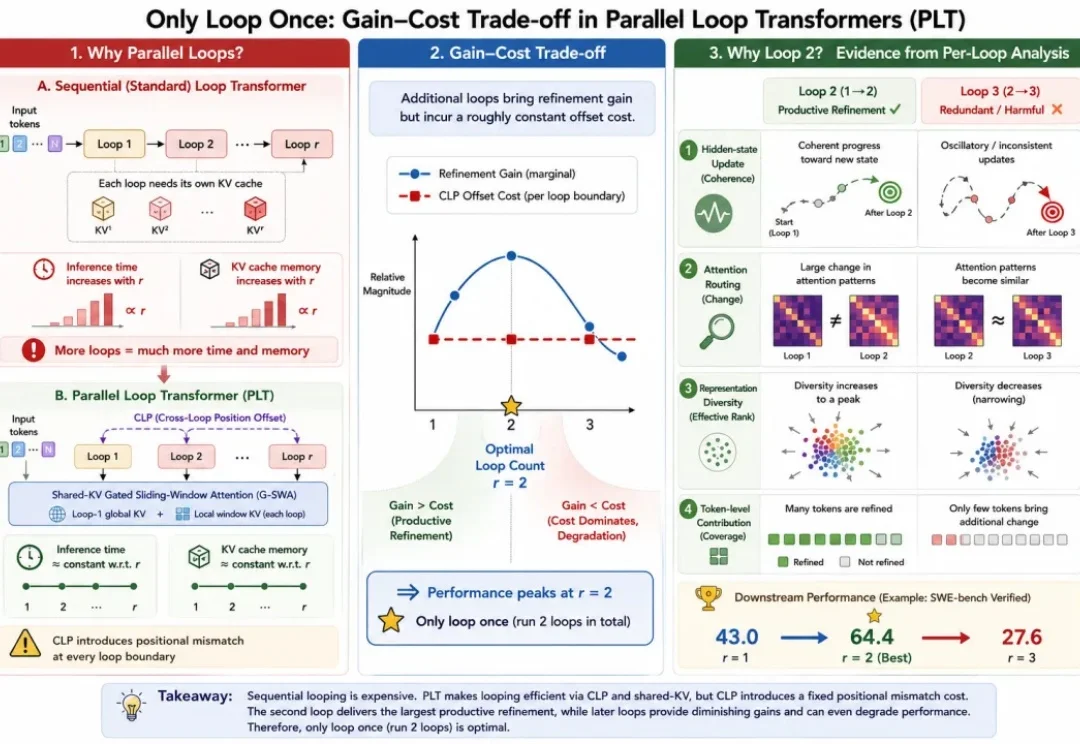
当所有人都在比谁「想得更久、算得更多」——推理模型动辄输出成千上万个思考 token,循环式架构恨不得在内部反复迭代十遍八遍——一项新研究反手泼了盆冷水:

如果只看标题,它很容易被归到“又一个万亿参数大模型”的队伍里:1.6 万亿总参数、MoE 架构、100 万 token 上下文、面向代码和 Agent 场景。但这次真正值得看的,不只是模型有多大,而是它背后的三个问题:国产算力能不能支撑前沿级大模型训练?

0 美元你能得到什么——Gemini 2.5 Flash 和 Pro 均可用,每分钟 1M tokens,原生支持文本、图像、音频、视频多模态输入 ,几秒钟生成 API Key,即开即用
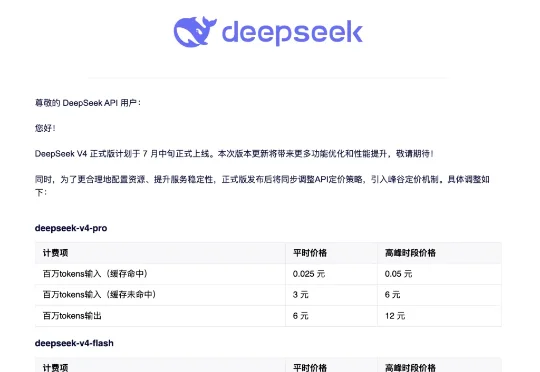
记者获悉,DeepSeek宣布价格调整,引入峰谷计费机制:以DeepSeek-v4-pro为例,其输入价格(缓存命中)平时为0.025元/百万tokens,高峰时期为0.05元/百万tokens;输入价格(缓存未命中)平时为3元/百万tokens,高峰时期为6元/百万tokens;输出价格平时为6元/百万tokens,高峰时期为12元/百万tokens。

你有没有想过一个问题: 我们平时选模型,到底有多少是因为它真的好用,又有多少是因为它便宜?
最近另一个叫「马尾辫」的项目在 GitHub 上开始被疯狂下载,直接拿下了 GitHub 热门榜单连续三周的周榜第一。这个项目的介绍图也特别有意思,在项目描述里写着,你一定认识他,长长的马尾辫,椭圆形眼镜,在公司待的时间比版本控制系统的历史还长。你给他看五十行代码;他看了看,什么也没说,然后只用一行替换掉。

什么是AI原生支付?随着全世界个体token的消耗量猛增,越来越多的大玩家和初创公司开始瞄准AI支付机制和基础设施的问题。