# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在当前的AI Research浪潮中,Autonomous Agents已经改变了我们获取信息的方式——从被动接收到主动检索。
然而,现有的Agent似乎都有一个共同的处理盲区:视频。

视频是互联网上信息密度最高的模态。但现有的AI要么是阅读理解高手(处理文本),要么只能盯着被喂到嘴边的一小段视频片段做问答。
真正的Agentic Video Browsing应该是什么样的?
它应该像人类一样:在海量视频中主动搜索,通过标题筛选,快速拖动进度条定位,最后只在关键时刻“全神贯注”地观看细节。
基于这个理念,研究团队提出了Video-Browser,并构建了全新的基准测试Video-BrowseComp。

在开放世界的视频搜索中,现有的方法面临着一个两难的困境(Modality Gap vs. Context Explosion):
1. 直接视觉推理(Direct Visual Inference,e.g.,RAG):简单粗暴地把视频帧流喂给MLLM。效果好,但贵到离谱。长视频会导致Context瞬间爆炸,不仅推理慢,还受限于上下文窗口。
2. 文本摘要(Summarization):先把视频转成文本摘要,再让Agent读文本。省钱了,但细节丢了。很多视觉细节(如“那只笔是什么颜色的?”)无法被通用的文本摘要捕捉。
我们需要一种既能像文本搜索一样高效,又能像视觉推理一样精准的新范式。
为了解决上述问题,研究团队提出了一种名为Pyramidal Perception(金字塔感知)的架构。
正如其名,研究团队将视频处理过程看作一个金字塔,由底向上,层层递进,计算量逐级增加,但处理的数据量逐级减少。
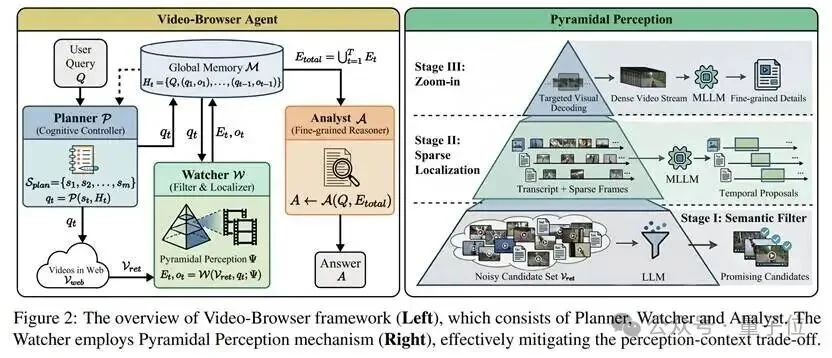
整个Video-Browser Agent包含三个核心组件:Planner(规划器)、Watcher(观察者)和Analyst(分析师)。
其中最核心的Watcher采用了三层金字塔机制:
面对海量的搜索结果,不需要打开每一个视频。Agent首先利用LLM分析视频的元数据(标题、简介等),以“零视觉成本”快速剔除无关内容,只保留最有希望的候选者。
对于入选的视频,不需要从头看到尾。Agent结合全量字幕和稀疏采样帧,快速扫描视频结构,定位出可能包含答案的时间窗口(Temporal Proposals)。
这是最关键的一步。在锁定的极短时间窗口内,进行高帧率解码,调用强大的MLLM进行精细的视觉推理。将最昂贵的计算资源,只花在最有价值的几秒钟上。
为了验证Agent的能力,研究团队发现现有的video benchmark往往陷入了被动感知的误区:给模型一段剪好的视频,问它里面发生了什么。
但这并不是真实的Agent。在真实世界中,Agent不会有人把视频喂到嘴边,它们必须像人类一样,在开放的互联网海洋中主动寻找线索。为了衡量这种真正的Agentic能力,研究团队构建了Video-BrowseComp。”
这是一个要求Agent必须具备Mandatory Video Dependency(强制视频依赖)的基准测试。其设计原则是:“Hard-to-Find,Easy-to-Verify”。
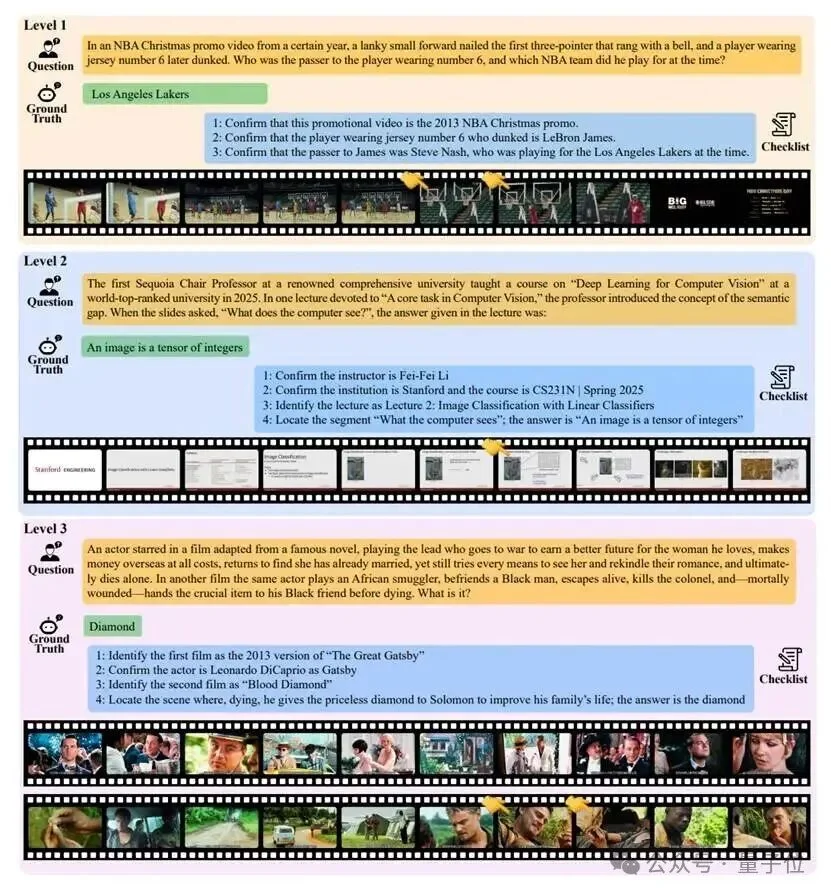
研究团队设计了三个难度等级:
Level 1 (显式检索):有明确的关键词,考查定位能力。
Level 2 (隐式检索):没有直接关键词,需要理解描述并进行推理。
Level 3 (多源推理):最难级别。答案分散在多个视频中,需要Agent像侦探一样拼凑线索。
研究团队在Video-BrowseComp上对比了GPT-5.2,Gemini-1.5-Pro等SOTA模型(包括Search-Augmented版本)。结果显示:
性能提升:Video-Browser (基于GPT-5.2)达到了26.19%的准确率,相比直接视觉推理基线提升了37.5%。
效率飞跃:得益于金字塔感知,研究团队的Token消耗降低了58.3%。
打破Deep Research垄断:研究团队的方法在视频任务上甚至优于OpenAI的o4-mini-deep-research,证明了在视频领域,高效的视觉感知策略的优异性。

来看一个经典的例子(Benchmark Level 3):
问题:在电影《白日梦想家》中,主角Walter Mitty胸口口袋里有一支笔贯穿全片,笔盖的出现暗示了他内心的渴望。请问这支笔是什么颜色的?

❌直接视觉推理(Direct Visual Inference):看了所有帧,但由于信息过载,模型声称“没看到笔” 。
❌文本摘要(Summarization):通过将电影转成文本,但文本中没有提到“笔的颜色”这种细节,模型回答“未提及” 。
✅ Video-Browser (Ours):成功定位到特写镜头,Zoom-in模式下清晰识别出了红色的笔盖,回答正确!
Video-Browser是迈向Agentic Open-web Video Browsing的重要一步。
研究团队通过模拟人类的认知过程——先浏览、再定位、后精读,成功解决了视频搜索中精度与成本的矛盾。
所有的代码、数据和Benchmark现已开源,研究团队希望该工作能为社区提供一个新的研究支点。
项目主页:
https://github.com/chrisx599/Video-Browser
论文链接:
https://arxiv.org/abs/2512.23044
文章来自于“量子位”,作者 “Video-Browser团队”。


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
