
OpenAI官宣退役o3与GPT-4.5!
OpenAI官宣退役o3与GPT-4.5!o3被封「GOAT」、GPT-4.5被叫「灵魂写手」,OpenAI说退就退。GPT-5.6已在热身——但「更强」能不能信?OpenAI自己说:未必。
来自主题: AI资讯
9162 点击 2026-05-31 11:45
 搜索
搜索
o3被封「GOAT」、GPT-4.5被叫「灵魂写手」,OpenAI说退就退。GPT-5.6已在热身——但「更强」能不能信?OpenAI自己说:未必。
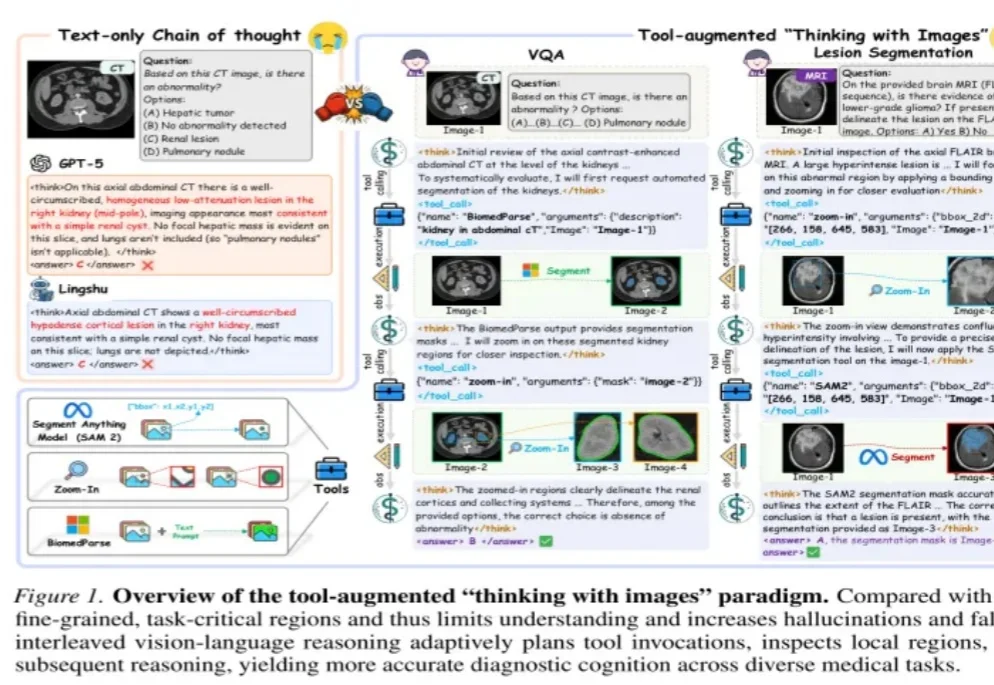
医学AI会写解释,但不代表它真的“看到”了关键证据。

OpenAI的人才地震还在继续!刚刚,前研究副总裁Max Schwarzer宣布离职,这位亲手主导o1、o3和整个GPT-5系列post-training的核心人物,选择加入Anthropic,重返一线RL研究。
还记得三个月前,来自三星的一位研究员的独作论文发布即爆火,颠覆了递归推理模型架构,让一个仅包含 700 万个参数的网络,性能比肩甚至超越 o3-mini 和 Gemini 2.5 Pro 等尖端语言模型,震惊了大量业内研究人士。
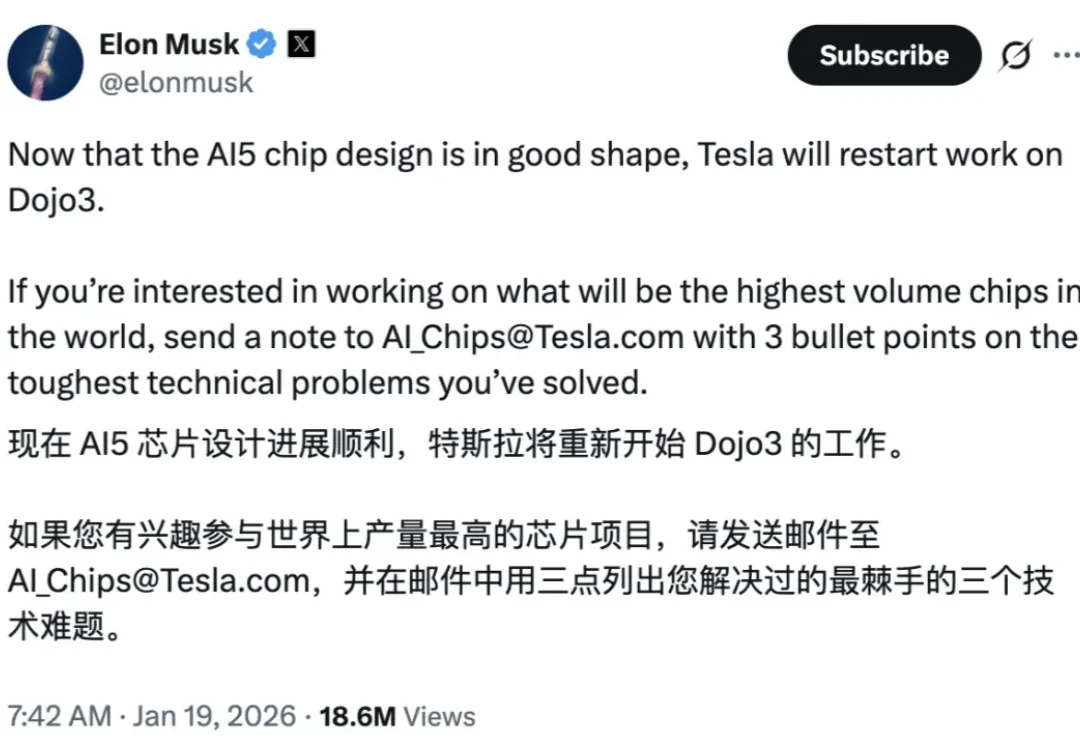
刚刚,马斯克丢了个重磅炸弹:「AI5 芯片设计进展顺利,特斯拉将重启 Dojo3 的工作。」
只靠模型性能,永远解决不了工程问题,真正的解法在云端Agent——这是芸思智能(Vinsoo)团队在研发之初就建立的认知。Vinsoo3.0中,Vinsoo云端Agent通过架构革命,实现了对传统工具的降维打击。

去年下半年,B2、B3两轮融资的钱还没捂热,这不,就在刚刚,新鲜热乎C1轮融资又双叒叕光速到位~行业首个实现双向对话、实时翻译的智能眼镜INMO GO3,首发仅3天,全渠道预订量就突破20000台。
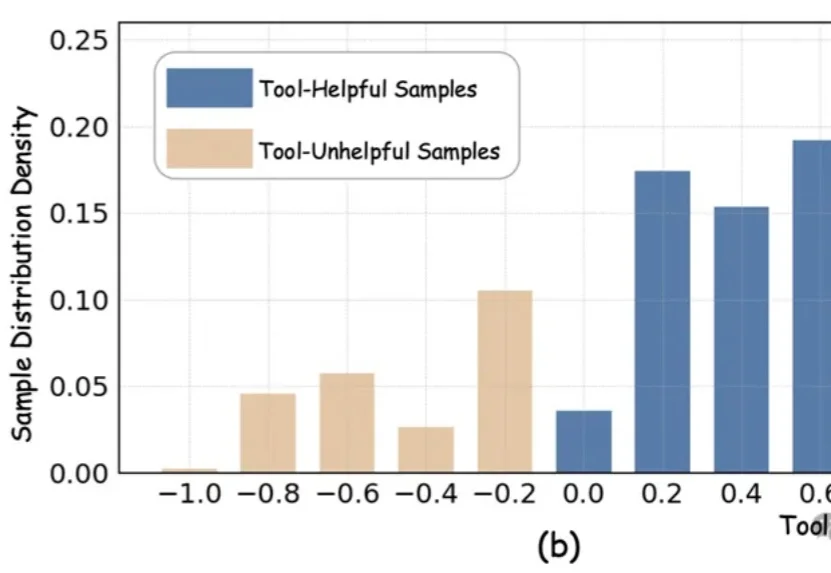
近期,以DeepEyes、Thymes为代表的类o3模型通过调用视觉工具,突破了传统纯文本CoT的限制,在视觉推理任务中取得了优异表现。
“What is meant often goes far beyond what is said, and that is what makes conversation possible.” ——H. P. Grice
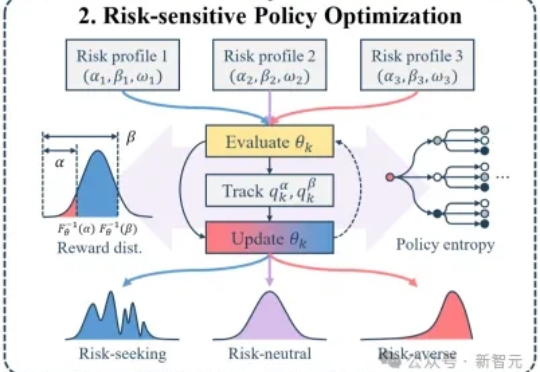
大模型后训练的痛点:均值优化忽略低概率高信息路径,导致推理能力停滞。RiskPO双管齐下,MVaR目标函数推导梯度估计,多问题捆绑转化反馈,实验中Geo3K准确率54.5%,LiveCodeBench Pass@1提升1%,泛化能力强悍。