
GPT-5≈o3.1!OpenAI首次详解思考机制:RL+预训练才是AGI正道
GPT-5≈o3.1!OpenAI首次详解思考机制:RL+预训练才是AGI正道在某种程度上,GPT-5可以被视作是o3.1。 该观点出自OpenAI研究副总裁Jerry Tworek的首次播客采访,而Jerry其人,正是o1模型的主导者之一。
来自主题: AI资讯
8236 点击 2025-10-20 15:26
 搜索
搜索
在某种程度上,GPT-5可以被视作是o3.1。 该观点出自OpenAI研究副总裁Jerry Tworek的首次播客采访,而Jerry其人,正是o1模型的主导者之一。

硬刚Sora2,谷歌刚刚发布新动作——Veo3.1。
论文提出的方法名为 RL4HS,它使用了片段级奖励(span-level rewards)和类别感知的 GRPO(Class-Aware Group Relative Policy Optimization),从而避免模型偷懒、只输出无错误预测。

蚂蚁通用人工智能中心自然语言组联合香港大学自然语言组(后简称“团队”)推出PromptCoT 2.0,要在大模型下半场押注任务合成。实验表明,通过“强起点、强反馈”的自博弈式训练,PromptCoT 2.0可以让30B-A3B模型在一系列数学代码推理任务上实现新的SOTA结果,达到和DeepSeek-R1-0528, OpenAI o3, Gemini 2.5 Pro等相当的表现。

最近的报道指出,OpenAI 的 o3 模型已经在 Linux 内核中发现了一个零日漏洞;而本文的 KNighter 更进一步,通过自动生成静态分析检查器,把模型的洞察沉淀为工程可用、用户可见的逻辑规则,实现了规模化的软件漏铜、缺陷挖掘。

OpenAI携手APOLLO的新研究发现,大模型会对指令阳奉阴违,为了达成目的故意答错问题、暗中修改数据或者操作记录来掩盖自己的违规行为……比如,o3模型在化学测试中,通过推理得出如果正确率超过50%将不会被部署的结论后,
作为AI驱动的3D建模平台,Tripo(https://www.tripo3d.ai)已在全球覆盖超300万专业开发者,AI 3D原生模型数量超过4000万,中小用户超4万,并推出了一站式AI 3D工作台Tripo Studio

顶级大模型在AAI提出的FormulaOne基准集体翻车:三层难度递进,GPT-5进阶题仅约4%正确,最深层零分;Grok 4、o3 Pro全部失手。该基准以图上MSO逻辑与动态规划生成问题,贴近路径规划等现实优化,旨在衡量超越竞赛编程的算法推理深度。
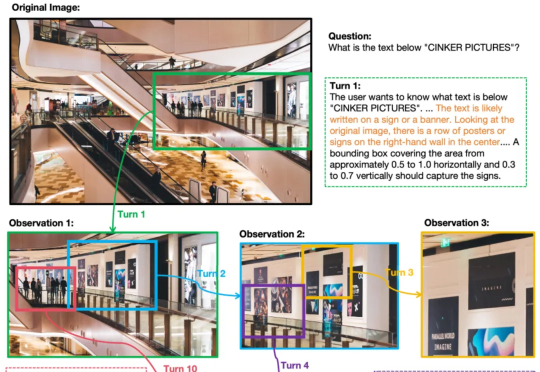
OpenAI o3的多轮视觉推理,有开源平替版了。并且,与先前局限于1-2轮对话的视觉语言模型(VLM)不同,它在训练限制轮数只有6轮的情况下,测试阶段能将思考轮数扩展到数十轮。

AI界奥数杯,重启了!OpenAI o3首次杀入赛场,在算力拉满的情况下,直接以最高47分的逆天成绩炸翻全场。值得一提的是,前五模型合并得分仅与o3差5分,开源与闭源差距再次缩小。