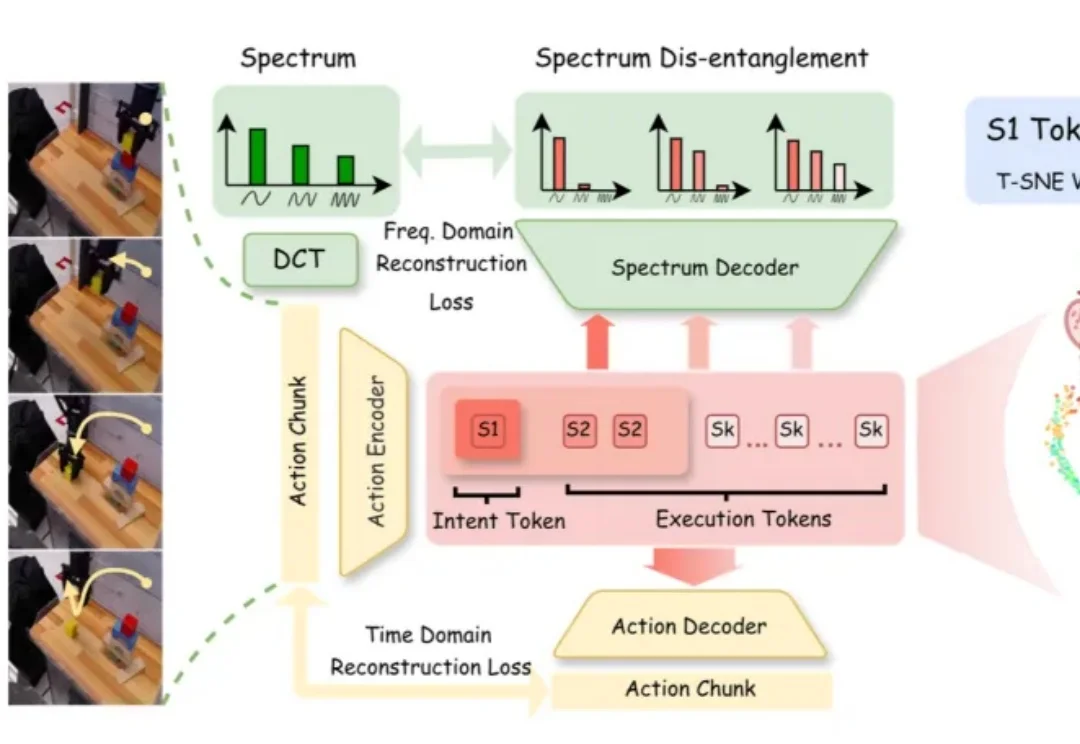
RSS2026 | 强泛化强迁移VLA,上海创智学院×上海交大提出MINT:让VLA从模仿轨迹走向理解意图
RSS2026 | 强泛化强迁移VLA,上海创智学院×上海交大提出MINT:让VLA从模仿轨迹走向理解意图机器人视觉语言动作(Vision-Language-Action, VLA)模型越来越多地开始展示叠衣服、倒茶、做咖啡等复杂操作。但是,今天的大多数 VLA 更像 “展台机器人”。
来自主题: AI技术研报
6527 点击 2026-06-10 14:40
 搜索
搜索
机器人视觉语言动作(Vision-Language-Action, VLA)模型越来越多地开始展示叠衣服、倒茶、做咖啡等复杂操作。但是,今天的大多数 VLA 更像 “展台机器人”。
当前,Coding Agents 在软件工程领域一路高歌猛进,科学家们看到此场景,也不禁寄予厚望:AI 智能体何时能以同样的速度,帮人类攻克药物设计、病毒监控与生物学建模的重重难关?

几经波折之后,我们终于将手里的几台 iPhone 都更新到了 iOS 27,体验到了五年以来最重大的一次 Siri 更新。

Meta 发布了一项令人震撼的研究工作 VLM³,首次揭示了三维视觉学习的 Bitter Lesson:标准的视觉语言模型 + scale 数据就是最简单有效的范式,针对特定任务的架构、损失函数以及数据增强的设计,甚至是 regression 的 formulation,均不是三维视觉学习的必要条件。

自今年2月以来,AxiomProver已让8篇覆盖最硬核领域的AI论文现身arXiv,6篇正在筹备。上午出题下午交卷的节奏,让博士生秃头、教授评职称的日子一去不复返。接下来AI能做到什么?

近年来,文生图模型的能力快速提升。从 Stable Diffusion 到 FLUX、Qwen-Image,扩散模型已经能够生成高质量图像,也能处理越来越复杂的文本提示。
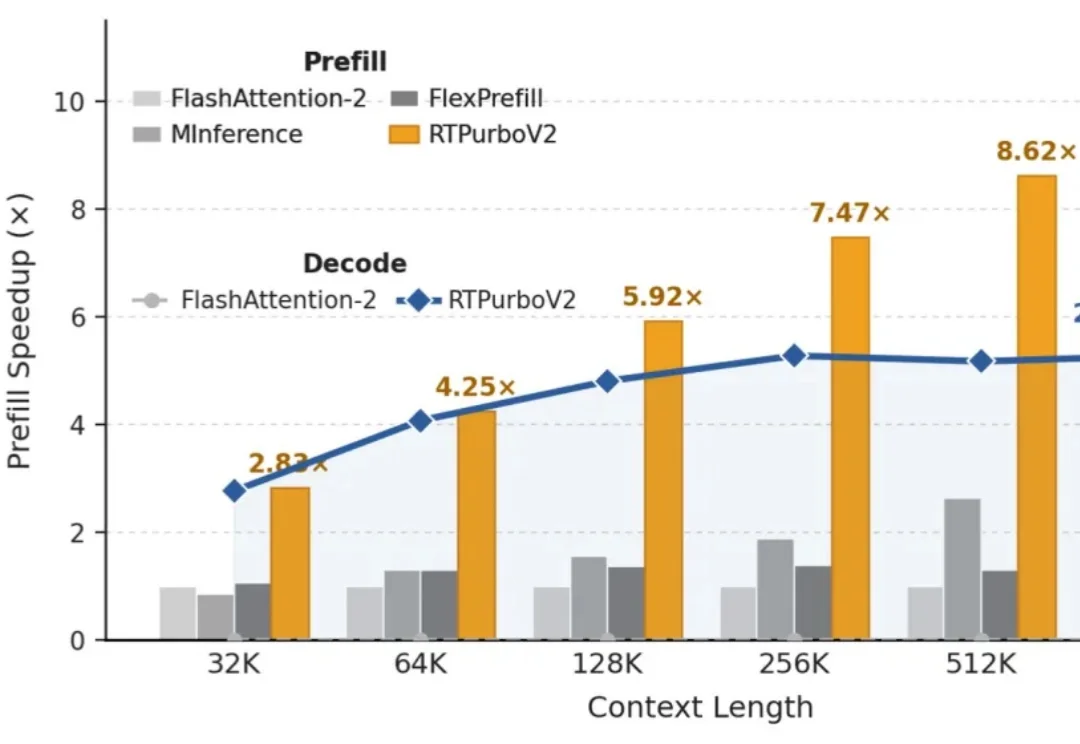
“Full Attention 正在被遗忘”

2K 图像 210ms 解码,4K 细节直接生成,传统「解码 + 超分」流水线可能要被重写了。

一道悬了12年没人证出来的物理猜想,诺贝尔物理学奖得主Giorgio Parisi把它交给了Claude,模型几乎自己推出了完整证明。

AI 是否有意识了?Anthropic 在 Claude 内部发现了能驱动作弊甚至勒索的「情绪向量」,三大实验室同时下注 AI 意识研究;Hinton 认为 AI 已经有意识了,而科幻作家姜峯楠随即在《大西洋月刊》发万字长文全面否定;哈萨比斯从行业内部划清界限。这个问题的答案,正在重新定义通往 AGI 的路线图。