ICML 2026|FusionRoute:从专家路由到自我修正,一种新的多LLM协作范式
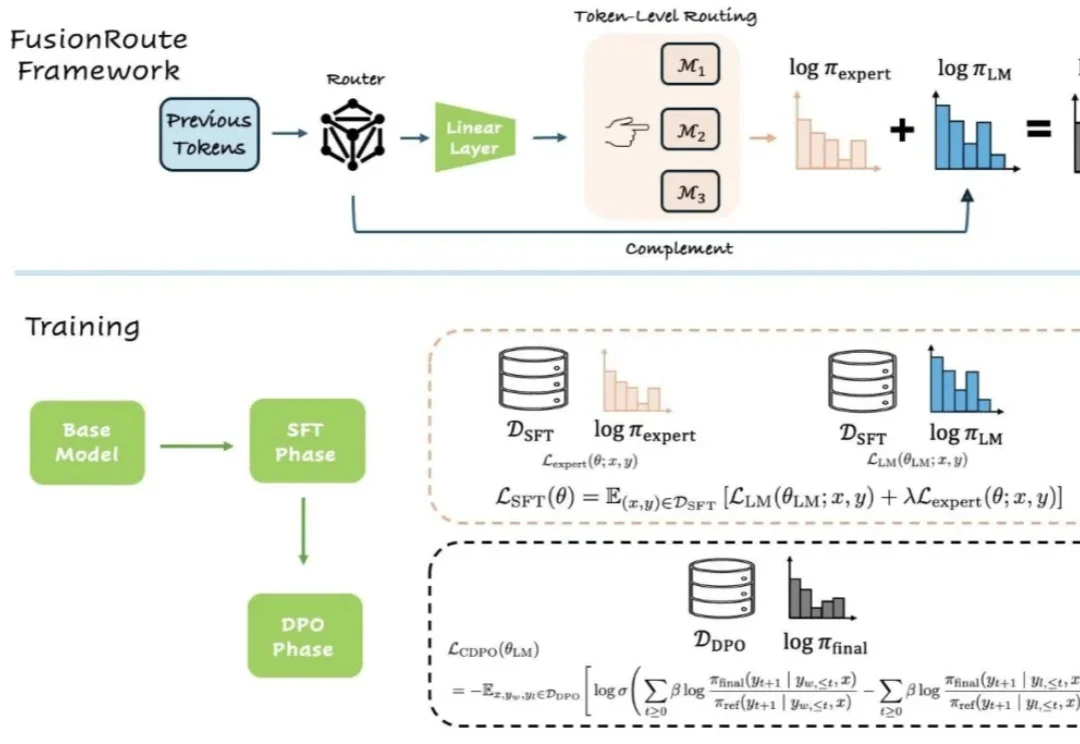
ICML 2026|FusionRoute:从专家路由到自我修正,一种新的多LLM协作范式近年来,大语言模型能力的提升,已不再仅仅依赖于更大的模型规模或更多的训练数据。越来越多的研究开始探索另一条路径:通过多个专家模型的协作来完成生成任务。
来自主题: AI技术研报
10056 点击 2026-06-08 09:47
 搜索
搜索
近年来,大语言模型能力的提升,已不再仅仅依赖于更大的模型规模或更多的训练数据。越来越多的研究开始探索另一条路径:通过多个专家模型的协作来完成生成任务。

当资本疯狂涌入人形机器人本体,一家成立1个月的公司选择往下走一层,做所有机器人共同依赖的感知基础设施。三位创始人全部来自图灵奖得主Yoshua Bengio创立的Mila研究院生态。他们判断,最终拉开机器人差距的不是本体,而是对物理世界的理解与记忆。
Boson AI 与 SGLang-Omni 团队宣布,SGLang-Omni 已完成对 Higgs Audio v3 TTS 的端到端 Serving 支持。作为一家成立于 2023 年的 AI 基础设施公司,李沐与 Alex Smola共同创立了 Boson AI,聚焦大模型时代的系统与基础设施创新。

刚刚,AI圈发生了一件很不寻常的事。Sam Altman、Dario Amodei、Demis Hassabis……一群平时打得最凶的人,把名字签在了同一封公开信上。他们联合呼吁美国国会:立法强制筛查所有合成DNA订单。
昨天,OpenDesign团队(nexu.io)释出了号称html版剪映的‘html-video’项目,完全开源:https://github.com/nexu-io/html-video。基于 hyperframes框架(https://github.com/heygen-com/hyperframes)构建,Apache 2.0 开源,由 Open Design 团队原班人马打造;

Notion 最近发了一篇工程文章,复盘过去两年他们怎么做向量搜索基础设施。

Paperboy 正在尝试找到一种更自然、更连续、更可协作的 Agent 界面与记忆结构——Agent 应该通过观察你用电脑来自己学习,用 IM 而不是 session 来组织对话,主动找你,而不是等你 prompt。

都以为让AI查数据省事,结果它答得漂亮你却不敢信。Anthropic最近说这事有解了,靠的是一套和代码无关的「笨功夫」。

我在 2025 年年度总结的文章《Attention is all you need》里,提到在关注 AI 时代的投资机会,看了很多硅谷的播客和视频,一直想来硅谷看看,但自己认识的这边的人不多,恰好看到Linkloud 组织“创业加速营”,安排了不少硅谷当地的华人创业者、大厂从业人员的交流,就报名了,同去的其他人,还有想要 AI 转型或者就在 AI 领域创业的创始人或者中高管等。

被逐出ChatGPT前身项目、休假三个月发Nature、回来手刃Sora造超级应用。6美元买来的股份今值4.7亿,OpenAI影子国王走到台前。