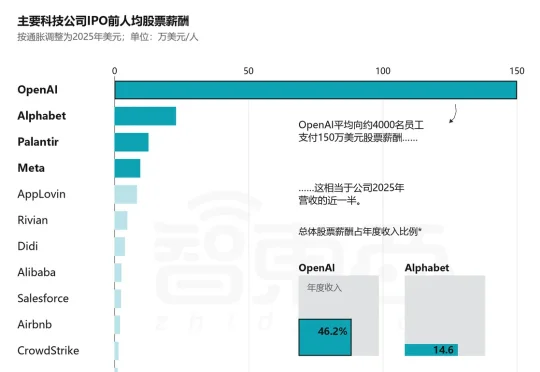
曝OpenAI、Claude员工已套现950亿!
曝OpenAI、Claude员工已套现950亿!据外媒The Information昨日报道,过去5年间,OpenAI和Anthropic的早期员工及投资者已通过私下股份出售合计套现约140亿美元(约合人民币950亿元)。这一轮员工造富潮正值AI行业IPO竞赛全面升温。6月12日,SpaceX以1.75万亿美元估值登陆纳斯达克,成为这波超级IPO潮中第一个落地的案例。而在此之前,SpaceX至少已连续5年安排员工减持。
来自主题: AI资讯
9457 点击 2026-06-15 21:21