
斯坦福报告:中国自主培养,顶尖AI人才崛起
斯坦福报告:中国自主培养,顶尖AI人才崛起斯坦福胡佛研究所追踪了 DeepSeek 七篇论文背后 356 名研究者的完整职业轨迹。美国培养出的最优秀 AI 人才正在大规模回流中国,而中国本土管道已经能独立产出前沿模型的核心贡献者。
来自主题: AI技术研报
9558 点击 2026-06-21 10:44
 搜索
搜索
斯坦福胡佛研究所追踪了 DeepSeek 七篇论文背后 356 名研究者的完整职业轨迹。美国培养出的最优秀 AI 人才正在大规模回流中国,而中国本土管道已经能独立产出前沿模型的核心贡献者。

来自西湖大学和香港中文大学(深圳)的团队沿着这一思路提出 Drifting Preference Optimization(DrPO),把漂移场用于单步文生图模型的偏好后训练。在 DrPO 中,奖励只负责对候选图像排序,不参与反向传播。具体而言,针对同一个文本提示词,当前模型生成一组候选图像。高分样本在特征空间中产生吸引,低分样本产生排斥,并结合参考模型约束给出模型的更新方向。

Waniwani宣布完成了800万美元的种子轮融资,由Seedcamp领投,Redstone、Zone II Ventures、Plug & Play、OPRTRs Club、Kima Ventures以及一批知名天使投资人跟投。
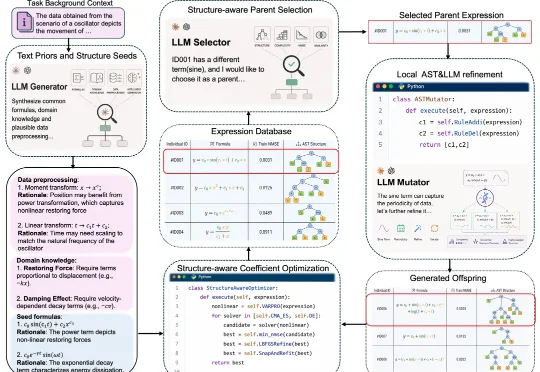
来自博世中央研究院与清华大学的研究人员提出 FunctionEvolve 框架,在两大基准测试上大幅刷新了这项任务的结果。在 LLM-SRBench 的 129 个合成科学方程任务上,FunctionEvolve 最终给出的公式在 55.8% 的任务上与真实公式等价(SA@1 = 72/129),是此前最好结果的 3.6 倍;

刚刚,外媒The Information援引两位知情人士报道,爆款通用Agent产品Manus的早期中国支持者,计划掏出20亿美元(约合人民币135亿元),向Meta回购该公司。
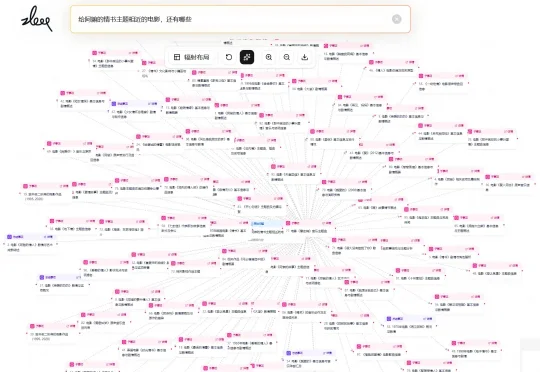
广州智跃深空人工智能科技有限公司 Zleap AI 提出的 SAG(SQL-Retrieval Augmented Generation) 出场了。其实,名字已经点题了——不是 Graph、Hippo,而是 SQL-Retrieval。它的核心想法是在离线阶段,SAG 先把原始文本先整理成「事项 + 实体」的数据库结构。等查询来了,再围绕当前问题,用 SQL 动态串出一张局部线索网。

在这场69分钟完整访谈里,Dario Amodei 说人类真正面对的不是某个突然降临的奇点,而是一条已经开始垂直起飞的指数曲线。

Bessemer(投出过 Shopify、Twilio 那家老牌 VC)发了一篇讲 AI 时代怎么找 PMF(产品市场契合)的文章。开篇就把一个我们默认的错觉点破了:
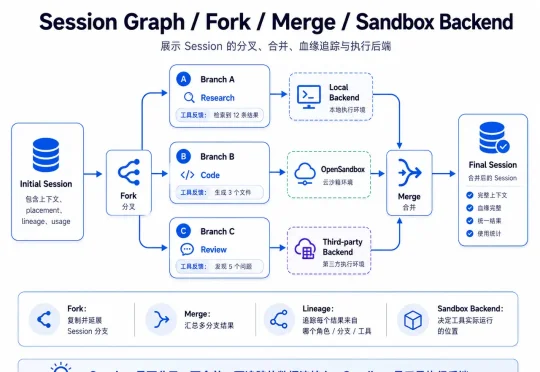
最近,一个来自清华大学与中山大学的团队(Rath Team)把他们的解法开源了,叫OpenRath:这是一个像PyTorch的多智能体、多会话运行时。它的主张是:别再围着Agent转了。真正该被当成一等公民的,是Session。
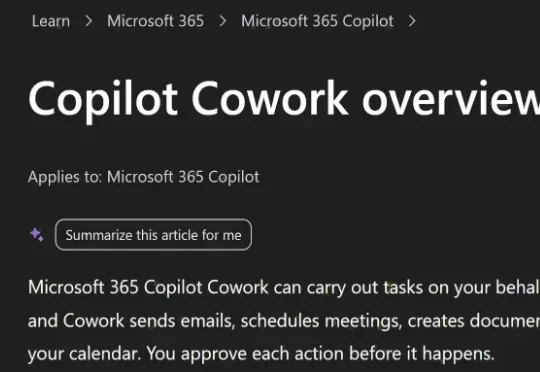
当地时间6月16日,微软宣布将企业AI工具Copilot Cowork转向按使用量计费。另据外媒Axios报道,在扩大该工具访问范围的同时,Copilot Cowork近期考虑引入由微软托管的DeepSeek模型,作为更低成本的模型选项。