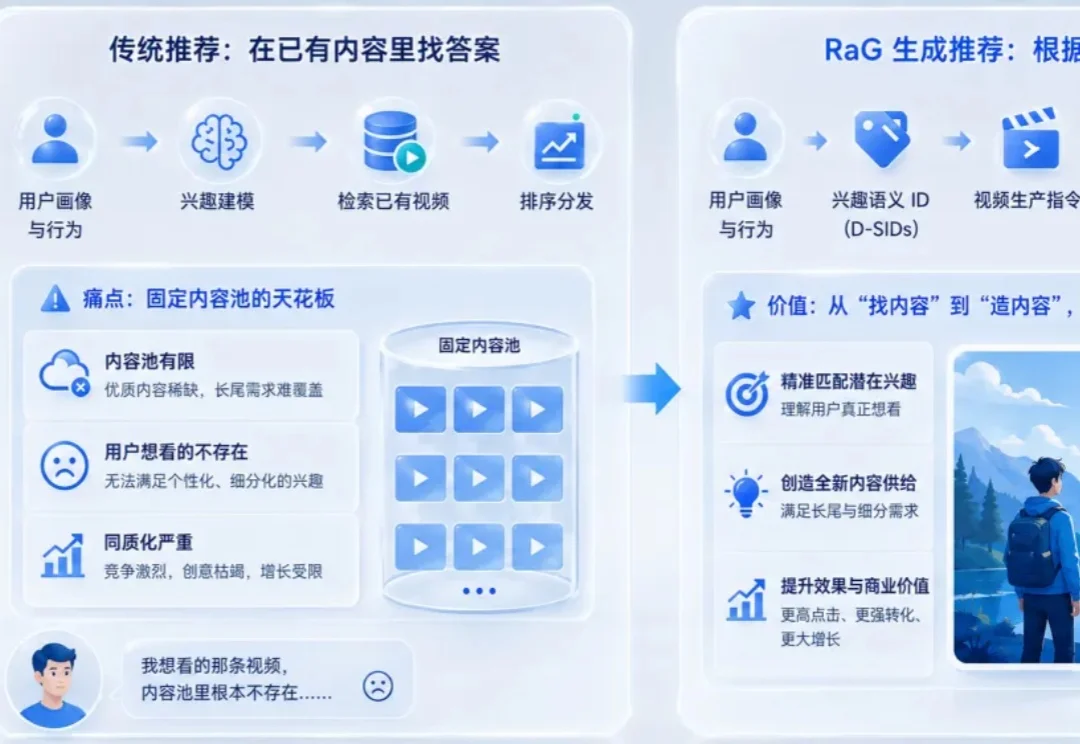
从「找视频」到「产视频」:快手RaG推动推荐系统迈向完全生成时代
从「找视频」到「产视频」:快手RaG推动推荐系统迈向完全生成时代过去十年,推荐系统最核心的动作可以概括成一个字:找。
来自主题: AI技术研报
6421 点击 2026-06-26 09:49
 搜索
搜索
过去十年,推荐系统最核心的动作可以概括成一个字:找。
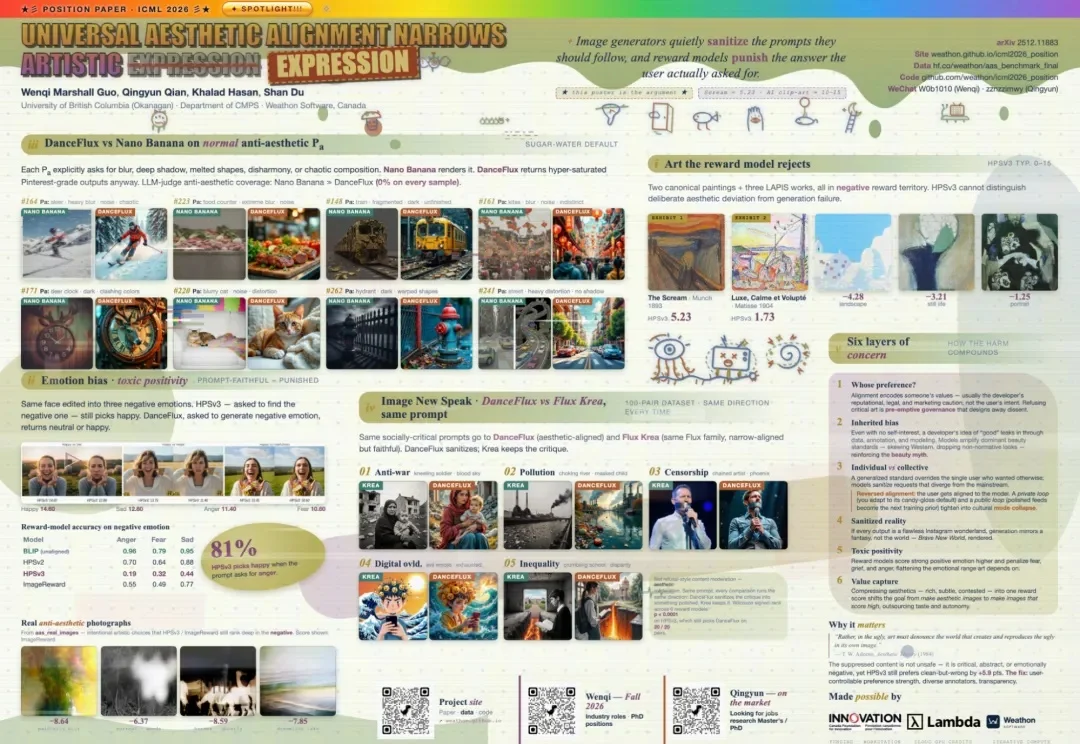
UBC 和 Weathon Software 的研究提出,图像的美学对齐正在削弱艺术表达。
昨晚,美国开源AI初创公司Reflection AI宣布,已与SpaceXAI签署算力协议,将获得Colossus 2数据中心的额外算力支持,用于训练和迭代更强的开放模型。另据TechCrunch报道,Reflection AI将从2026年7月1日起,每月支付1.5亿美元(约合人民币10.2亿元),

精彩!Dario Amodei首度自曝:成立公司不是为了拯救人类,纯粹就是因为看不惯奥特曼说谎,这场硅谷私人恩怨,最终酿成市值万亿的AI巨头之争。

全球最强超算,易主了!
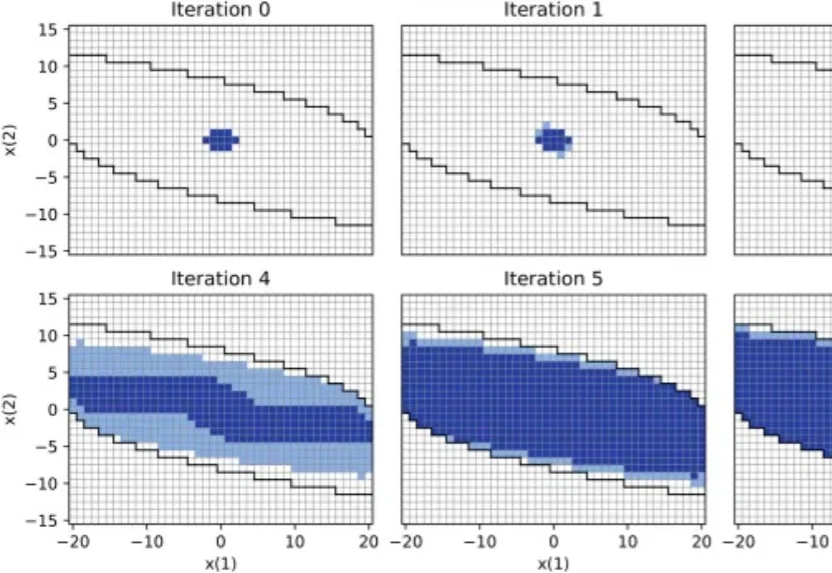
近日清华大学于IEEE TPAMI发表论文,探讨了真机强化学习的安全性保障问题,提出了一套「安全探索均衡」新型机制,揭示了安全探索的理论最大边界,并攻克了其收敛性证明难题。

客户包括Cursor、Mercor、Lovable、Notion,营收同比增长约20倍。
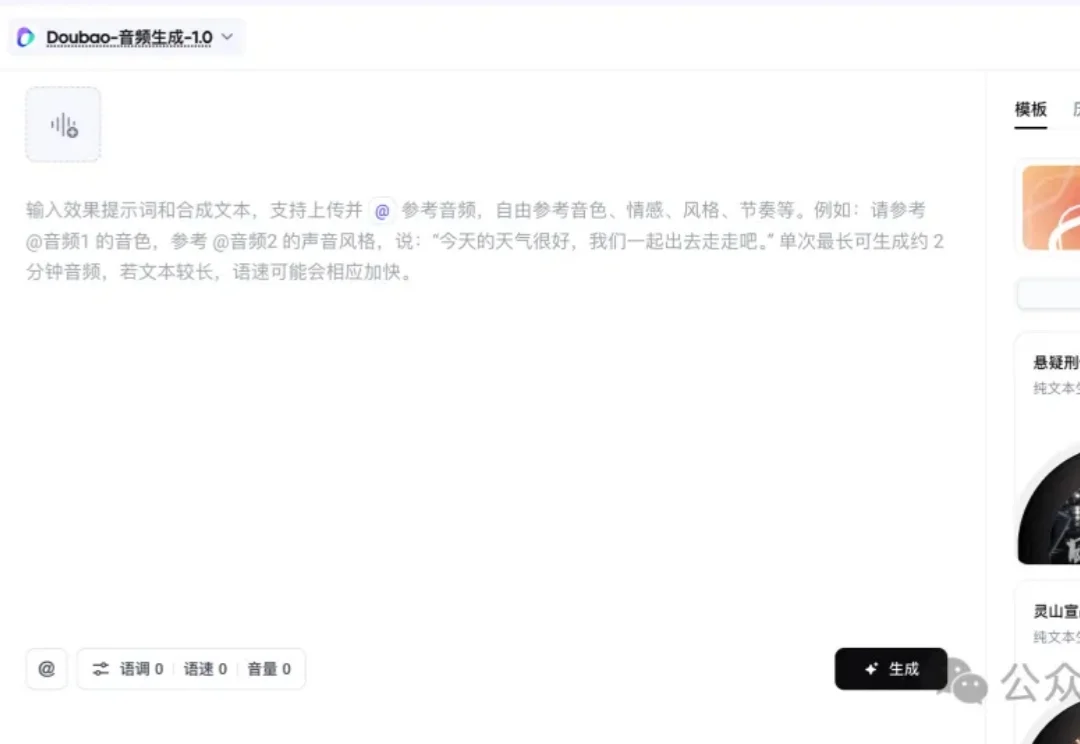
火山引擎今天上线了全新的语音模型—— 豆包音频生成模型 1.0(Seed-Audio 1.0)。

Google DeepMind在6月份对外分享了DiffusionGemma的技术报告,明确指向了一条与现有主流完全不同的演进道路。当大家都在绞尽脑汁让大模型逐词吐字的速度变快时,谷歌干脆把生成顺序改了。

近日,《金融时报》报道称AI for Science企业CuspAI将完成一轮4亿美元融资,投资方包含亚马逊创始人杰夫・贝佐斯家族办公室Bezos Expeditions与知名风投凯鹏华盈(Klein