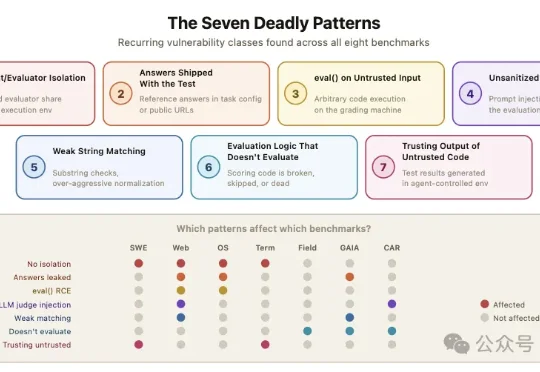
Factory完成1.5亿美元C轮融资,Anysphere、Cognition、Factory谁提供企业级AI编程的最优解?
Factory完成1.5亿美元C轮融资,Anysphere、Cognition、Factory谁提供企业级AI编程的最优解?近日,AI编程智能体初创公司 Factory 完成1.5亿美元C轮融资,投后估值达到15亿美元,正式跻身独角兽行列。本轮由Khosla Ventures领投,Sequoia Capital、Blackstone、Insight Partners、Evantic Capital、20VC、NEA和Mantis VC参与跟投。
来自主题: AI资讯
8984 点击 2026-05-01 22:30