# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

几十年来,人工智能领域一直在思考一个看似简单但非常根本的问题:
如果一个智能体要在真实世界中行动、规划,并且和环境互动,它需要一个怎样的「世界模型」?
在很多早期研究中,世界模型就是一个预测引擎:只要给它一个抽象的控制指令,比如「向前走一米」或者「向左转 30 度」,它就能模拟出未来的图像。这类方式在实验室环境里已经发挥过很大作用,但一旦放到真正复杂的人类生活环境,就常常捉襟见肘。
毕竟,人并不是一个漂浮在空中的摄像头。人有四肢、有关节、有骨骼,也有着非常具体的物理限制:
这些物理约束决定了:并不是所有动作都能被执行,很多计划只能在可达、可平衡、可承受的范围内完成。而正是这样的物理性,才塑造了人类真实的动作方式,也塑造了我们能够看到的和不能看到的信息。
举一些例子:
这些都不是凭空的,而是被身体结构和运动学约束的行为。所以如果 AI 也要像人一样预测未来,就得学会:预测自己的身体能做到什么动作,以及由此产生的视觉后果。
从心理学、神经科学到行为学,人们早就发现一个规律:在执行动作之前,人会先预演接下来会看到什么。
例如:
这种「预演」能力让人类能及时修正动作并避免失误。也就是说,我们并不是光靠看到的画面做出决策,而是一直在用大脑里的「想象」,预测动作的结果。
如果未来的 AI 想在真实环境中做到和人一样自然地计划,就需要拥有同样的预测机制:「我如果这样动,接下来会看到什么?」
世界模型并不新鲜,从 1943 年 Craik 提出「小规模大脑模型」的概念开始,到 Kalman 滤波器、LQR 等控制理论的出现,再到近年用深度学习做视觉预测,大家都在试图回答:「我采取一个动作,未来会怎样?」
但是这些方法往往只考虑了低维度的控制:像「前进」、「转向」这类参数。相比人类的全身动作,它们显得非常简陋。因为人类的动作:
如果一个世界模型不能考虑身体动作如何塑造视觉信息,它很难在现实世界里生存下来。
基于这样的背景,来自加州大学伯克利分校、Meta的研究者们提出了一个看起来简单但非常自然的问题:「如果我真的做了一个完整的人体动作,那接下来从我的眼睛会看到什么?」
相比传统模型只用「速度 + 方向」做预测,PEVA 把整个人的 3D 姿态(包括关节位置和旋转)一并喂进模型,和历史的视频帧一起输入,从而让 AI 学会:身体的动作,会如何重新组织我们能看到的世界。
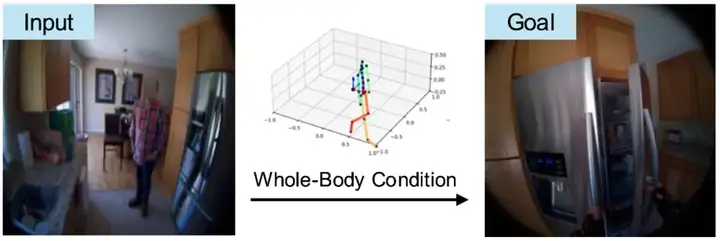
举一些例子:
这就是 PEVA 的核心:预测未来,不只是预测像素,而是预测身体驱动下的视觉后果。

PEVA 目前能做的事情包括:

不仅做单次预测,还能生成最长 16 秒的视觉流。

支持「反事实」推断:如果做另一个动作,会看到什么?
在多条动作序列之间做规划,通过视觉相似度挑出更优方案。

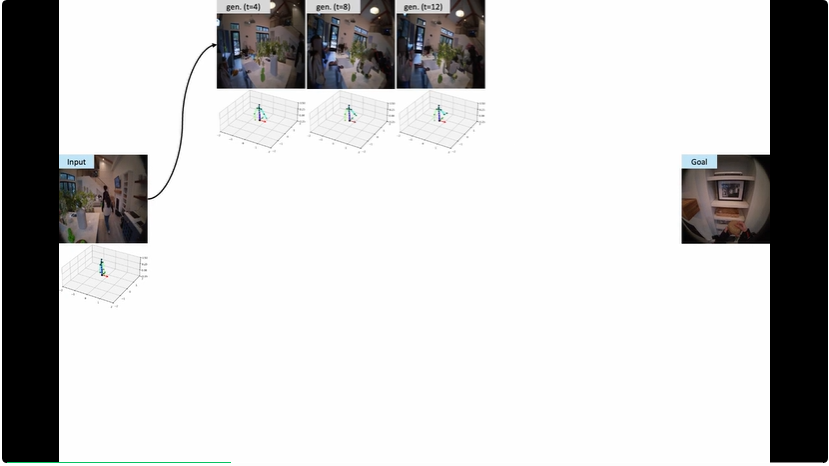
在多样化的日常环境中学习,避免过拟合在简单场景。
一句话总结,PEVA 就像一个「身体驱动的可视化模拟器」,让 AI 获得更接近人类的想象方式。
PEVA 的技术很简单直接,主要包括:
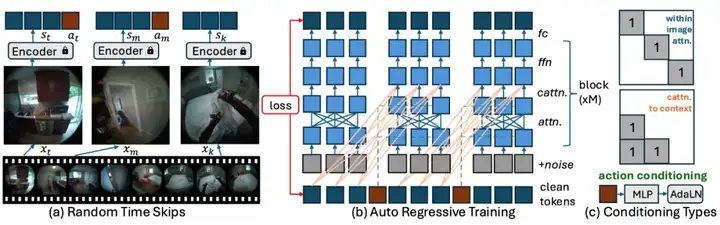
研究者在文章中也用大篇幅讨论了局限和展望:例如只做了单臂或部分身体的规划,目标意图还比较粗糙,没法像人那样用语言描述目标,这些都值得后续慢慢补齐。
从评估看,PEVA 在几个方面算是一个可行的探索:
这些能力至少证明了一个方向:用身体驱动未来的视觉预测,是走向具身智能的一种合理切入点。
后续还值得探索的方向包括:
当 AI 试着像人一样行动时,也许它同样需要先学会:如果我这么动,接下来会看到什么。
或许可以这样说:「人类之所以能看见未来,是因为身体在动,视觉随之更新。」
PEVA 只是一个很小的尝试,但希望为未来可解释、可信任的具身智能,提供一点点启发。
文章来自于“机器之心”,作者“机器之心”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
