
字节Seed发布扩散语言模型,推理速度达2146 tokens/s,比同规模自回归快5.4倍
字节Seed发布扩散语言模型,推理速度达2146 tokens/s,比同规模自回归快5.4倍用扩散模型写代码,不仅像开了倍速,改起来还特别灵活! 字节Seed最新发布扩散语言模型Seed Diffusion Preview,这款模型主要聚焦于代码生成领域,它的特别之处在于采用了离散状态扩散技术,在推理速度上表现出色。
来自主题: AI资讯
8203 点击 2025-08-01 16:04
 搜索
搜索
用扩散模型写代码,不仅像开了倍速,改起来还特别灵活! 字节Seed最新发布扩散语言模型Seed Diffusion Preview,这款模型主要聚焦于代码生成领域,它的特别之处在于采用了离散状态扩散技术,在推理速度上表现出色。
当下的AI图像生成领域,Diffusion模型无疑是绝对的王者,但在精准控制上却常常“心有余而力不足”。
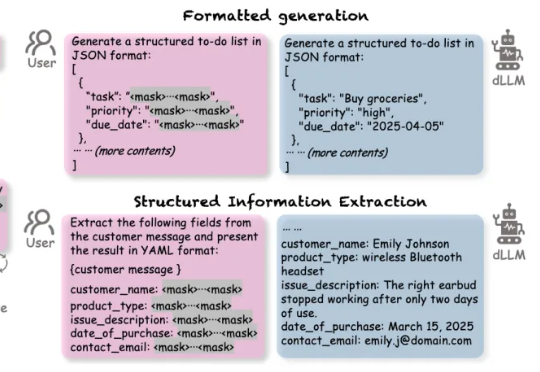
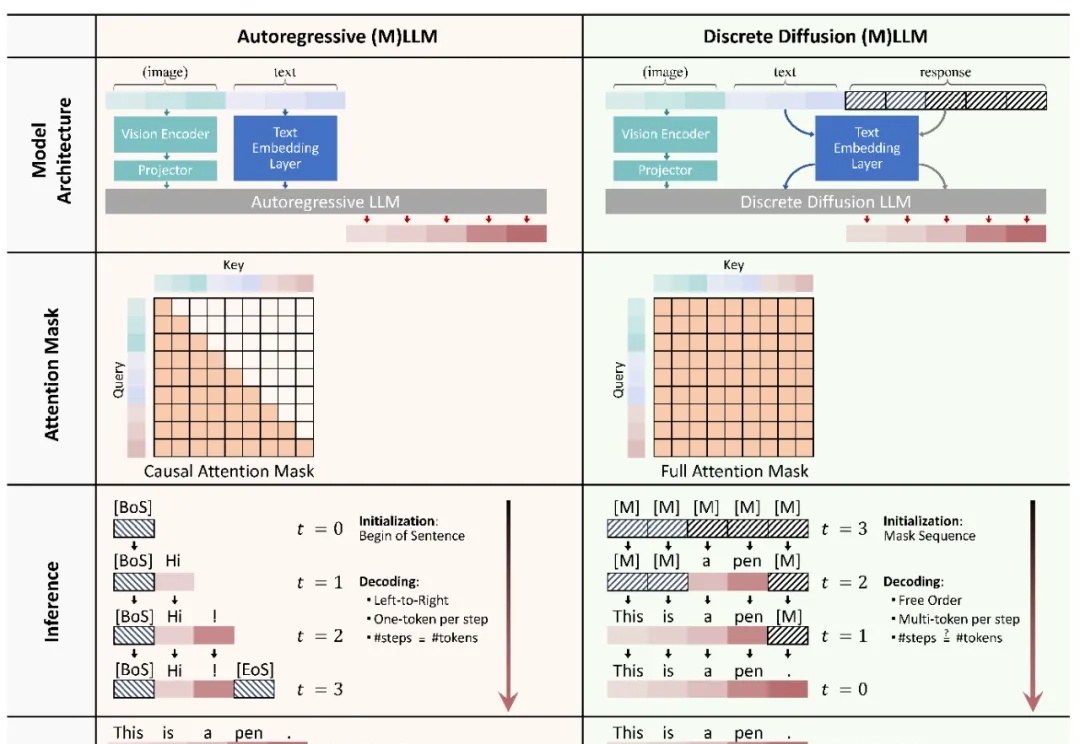
扩散语言模型(Diffusion-based LLMs,简称 dLLMs)以其并行解码、双向上下文建模、灵活插入masked token进行解码的特性,成为一个重要的发展方向。

AMD携手Stability AI宣布推出世界首款适用于Stable Diffusion 3.0 Medium的B16 NPU模型。该模型可直接运行于AMD XDNA 2 NPU之上,能够显著提升图像生成质量。新模型作为Amuse 3.1平台的组件之一亮相,于今天一起发布。
本文主要介绍 xML 团队的论文:Discrete Diffusion in Large Language and Multimodal Models: A Survey。

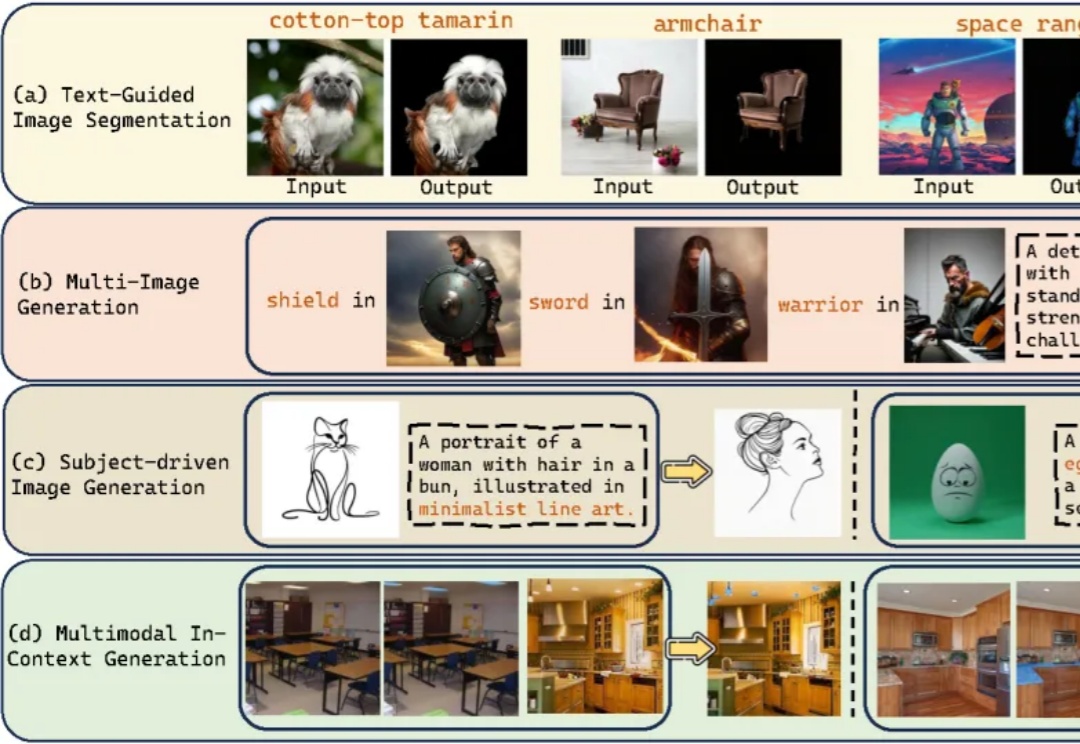
自 Stable Diffusion、Flux 等扩散模型 (Diffusion models) 席卷图像生成领域以来,文本到图像的生成技术取得了长足进步。但它们往往只能根据精确的文字或图片提示作图,缺乏真正读懂图像与文本、在多模 态上下文中推理并创作的能力。能否让模型像人类一样真正读懂图像与文本、完成多模态推理与创作,一直是学术界和工业界关注的热门问题。
近年来,随着扩散模型(Diffusion Models)和扩散 Transformer(DiT)在视频生成领域的广泛应用,AI 合成视频的质量和连贯性有了飞跃式提升。像 OpenAI Sora、HunyuanVideo、Wan2.1 等大模型,已经能够生成结构清晰、细节丰富且高度连贯的长视频内容,为数字内容创作、虚拟世界和多媒体娱乐带来了巨大变革。
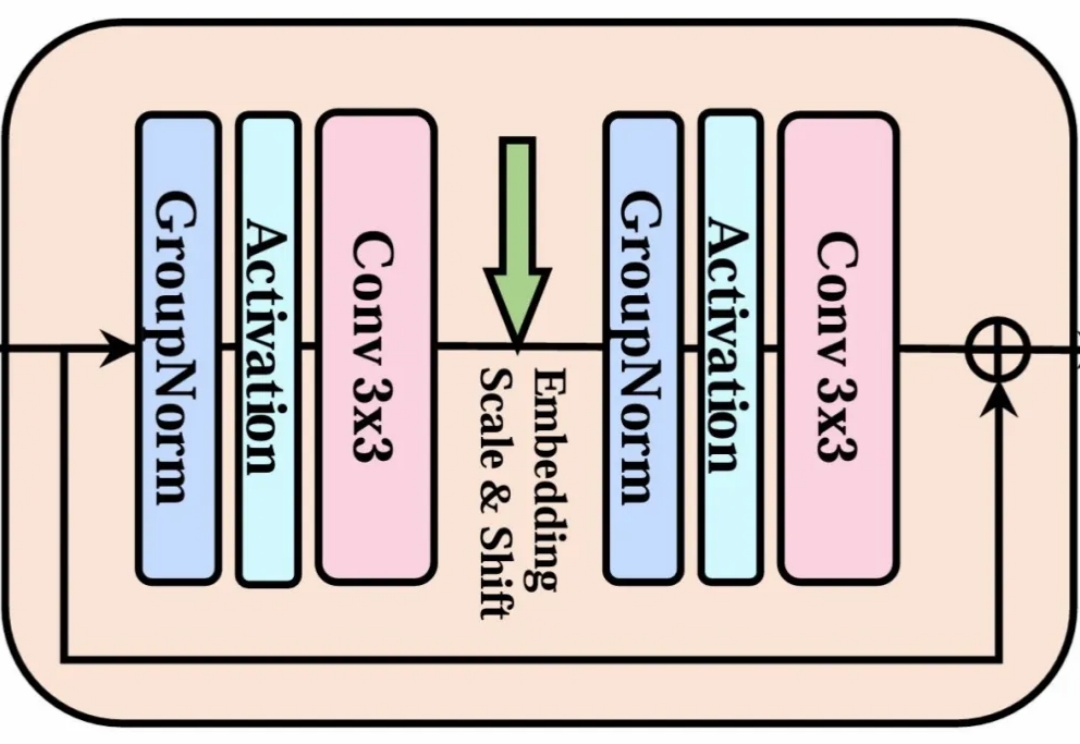
当整个 AI 视觉生成领域都在 Transformer 架构上「卷生卷死」时,一项来自北大、北邮和华为的最新研究却反其道而行之,重新审视了深度学习中最基础、最经典的模块——3x3 卷积。
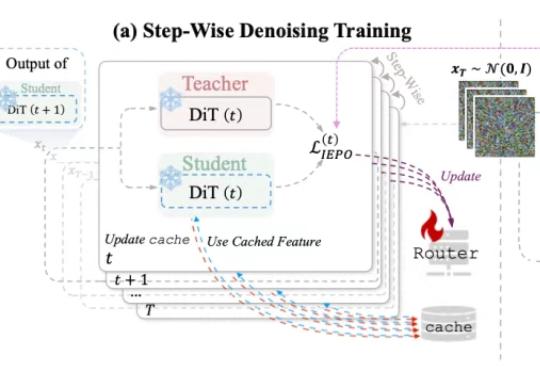
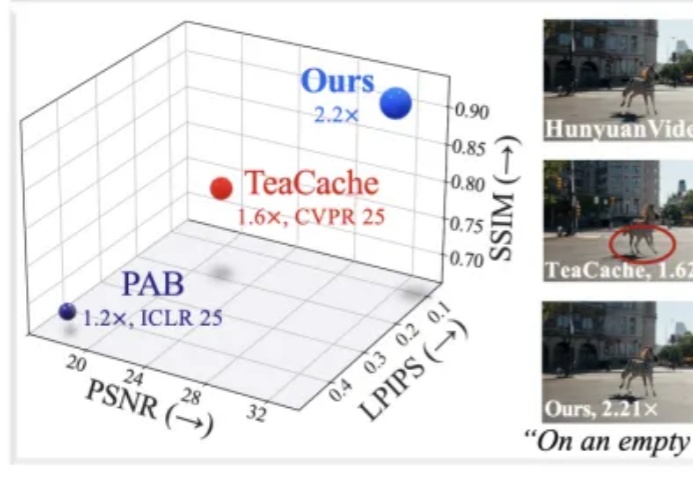
面对扩散模型推理速度慢、成本高的问题,HKUST&北航&商汤提出了全新缓存加速方案——HarmoniCa:训练-推理协同的特征缓存加速框架,突破DiT架构在部署端的速度瓶颈,成功实现高性能无损加速。
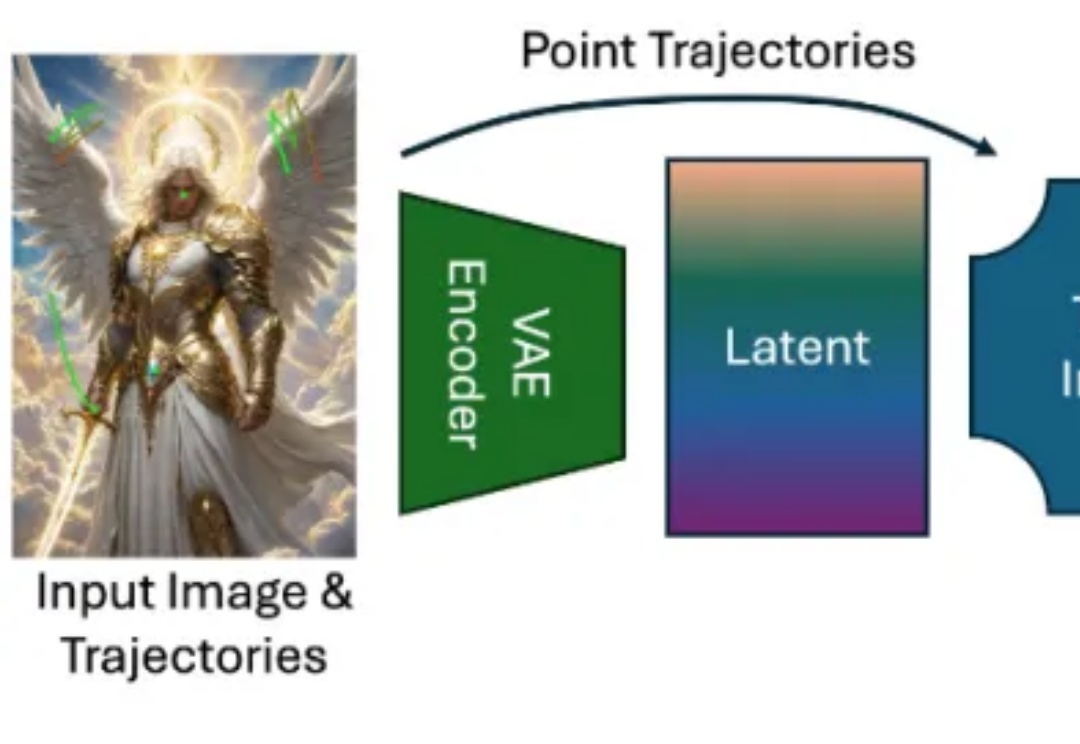
近年来,随着扩散模型(Diffusion Models)、Transformer 架构与高性能视觉理解模型的蓬勃发展,视频生成任务取得了令人瞩目的进展。从静态图像生成视频的任务(Image-to-Video generation)尤其受到关注,其关键优势在于:能够以最小的信息输入生成具有丰富时间连续性与空间一致性的动态内容。