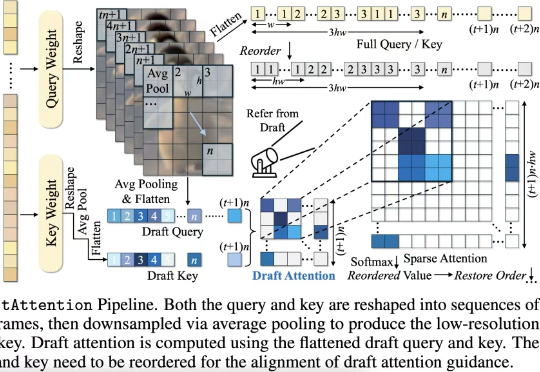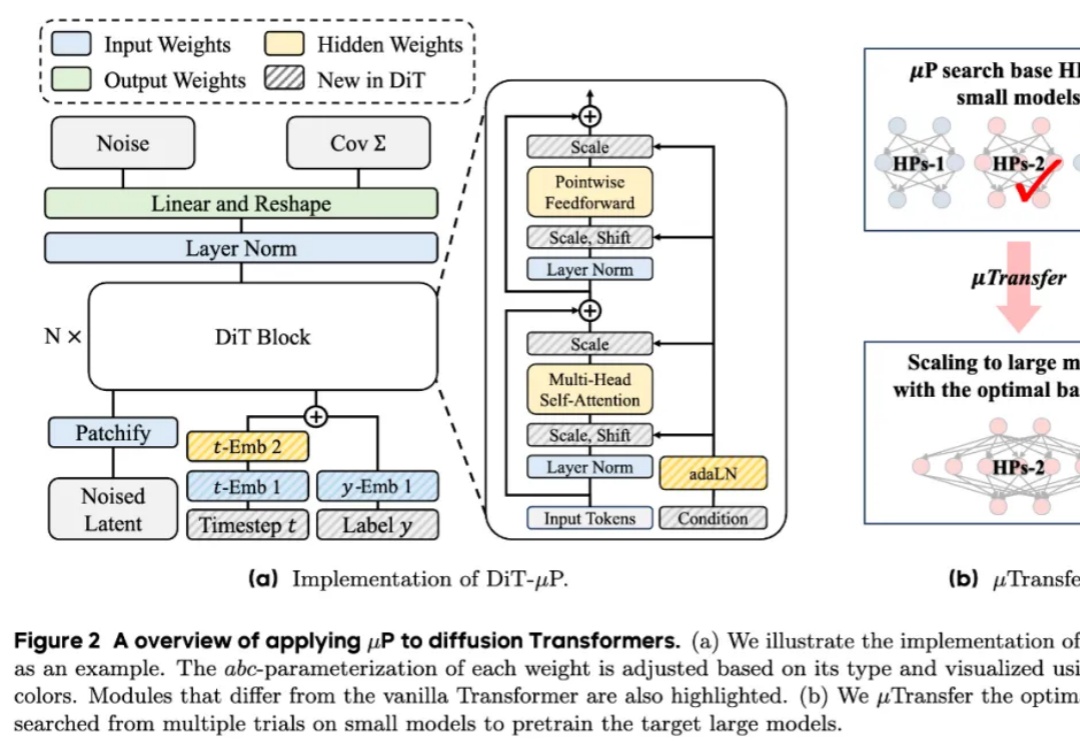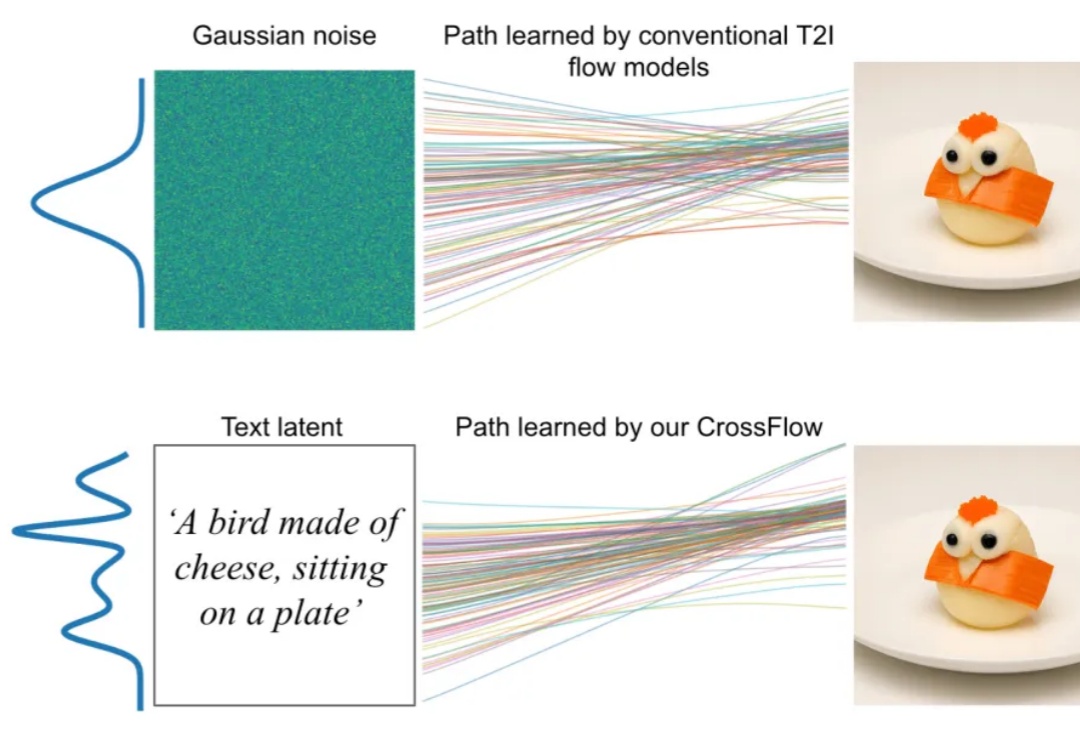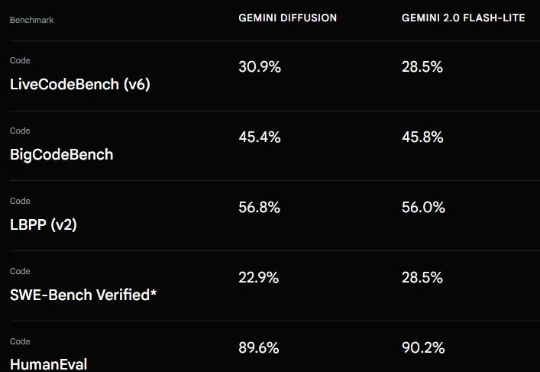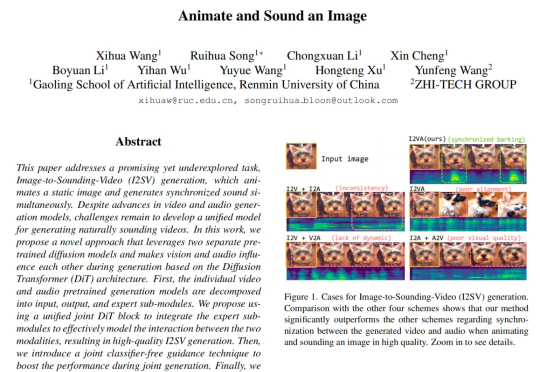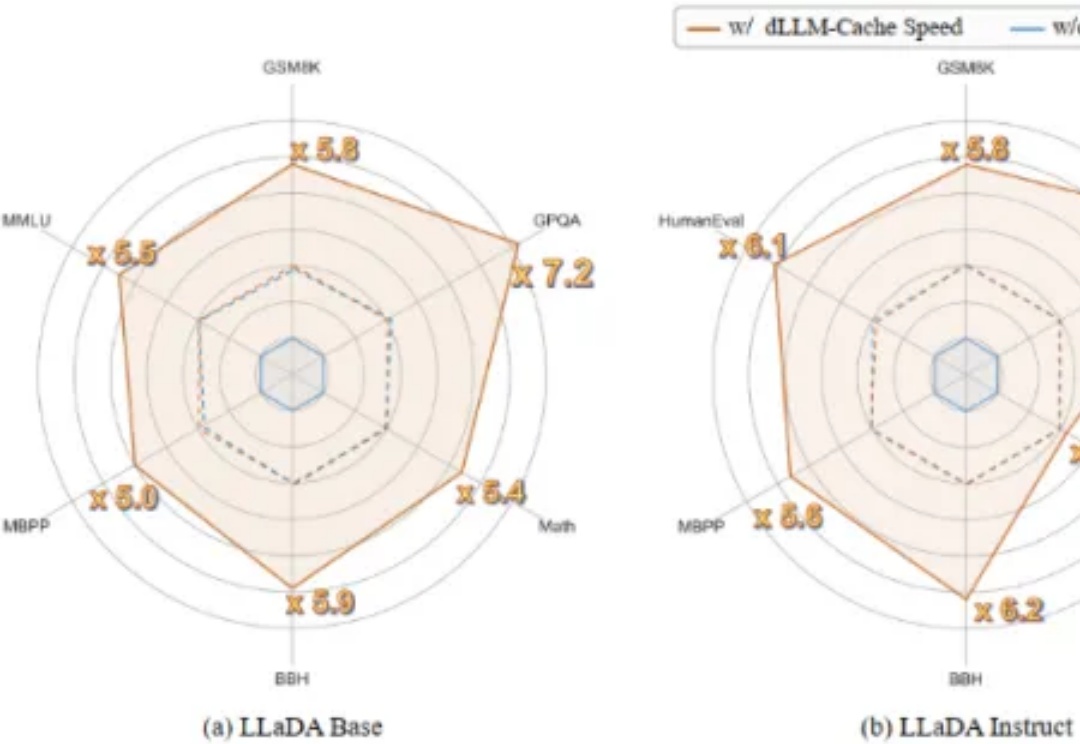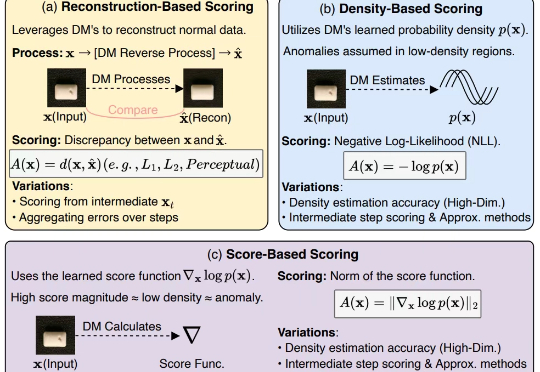
UofT、UBC、MIT和复旦等联合发布:扩散模型驱动的异常检测与生成全面综述
UofT、UBC、MIT和复旦等联合发布:扩散模型驱动的异常检测与生成全面综述扩散模型(Diffusion Models, DMs)近年来展现出巨大的潜力,在计算机视觉和自然语言处理等诸多任务中取得了显著进展,而异常检测(Anomaly Detection, AD)作为人工智能领域的关键研究任务,在工业制造、金融风控、医疗诊断等众多实际场景中发挥着重要作用。
来自主题: AI资讯
7769 点击 2025-07-01 10:55