清华、NVIDIA、斯坦福提出DiffusionNFT:基于前向过程的扩散强化学习新范式,训练效率提升25倍
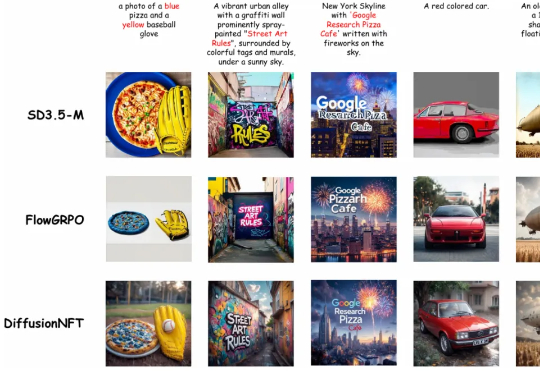
清华、NVIDIA、斯坦福提出DiffusionNFT:基于前向过程的扩散强化学习新范式,训练效率提升25倍清华大学朱军教授团队,NVIDIA Deep Imagination 研究组与斯坦福 Stefano Ermon 团队联合提出了一种全新的扩散模型强化学习(RL)范式 ——Diffusion Negative-aware FineTuning (DiffusionNFT)。该方法首次突破现有 RL 对扩散模型的基本假设,直接在前向加噪过程(forward process)上进行优化
来自主题: AI技术研报
10970 点击 2025-10-08 11:43