RAE+VAE? 预训练表征助力扩散模型Tokenizer,加速像素压缩到语义提取
RAE+VAE? 预训练表征助力扩散模型Tokenizer,加速像素压缩到语义提取近期,RAE(Diffusion Transformers with Representation Autoencoders)提出以「 冻结的预训练视觉表征」直接作为潜空间,以显著提升扩散模型的生成性能。
来自主题: AI技术研报
11718 点击 2025-11-14 10:21
 搜索
搜索
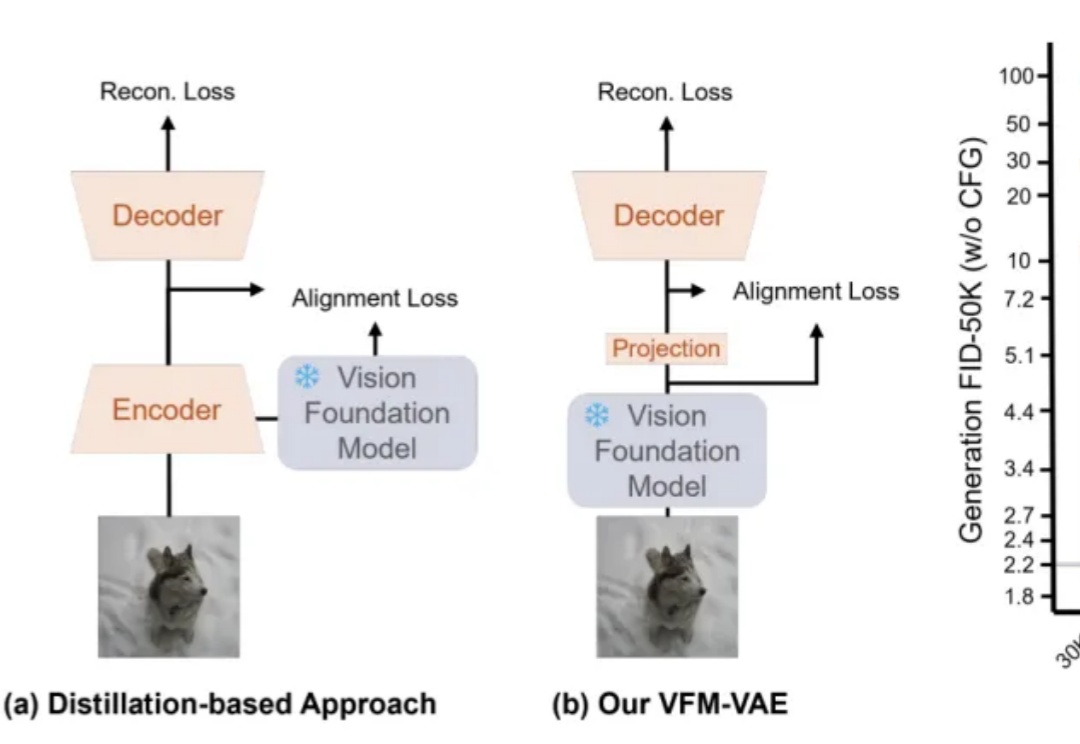
近期,RAE(Diffusion Transformers with Representation Autoencoders)提出以「 冻结的预训练视觉表征」直接作为潜空间,以显著提升扩散模型的生成性能。

近日,诺贝尔奖得主、美国华盛顿大学教授大卫·贝克(David Baker)和团队再次将 AI 成果送上 Nature,他们开发出一种基于 AI 的蛋白质结构生成模型 RFdiffusion,能在指定病毒表面特定表位的情况下,辅助人类从头设计出能够与之结合的抗体结构。
扩散大语言模型得到了突飞猛进的发展,早在 25 年 2 月 Inception Labs 推出 Mercury—— 第一个商业级扩散大型语言模型,同期人民大学发布第一个开源 8B 扩散大语言模型 LLaDA,5 月份 Gemini Diffusion 也接踵而至。

近日,上海人工智能实验室针对该难题提出全新范式 SDAR (Synergistic Diffusion-AutoRegression)。该方法通过「训练-推理解耦」的巧妙设计,无缝融合了 AR 模型的高性能与扩散模型的并行推理优势,能以极低成本将任意 AR 模型「改造」为并行解码模型。

近年来,基于扩散模型的图像生成技术发展迅猛,催生了Stable Diffusion、Midjourney等一系列强大的文生图应用。然而,当前主流的训练范式普遍依赖一个核心组件——变分自编码器(VAE),这也带来了长久以来困扰研究者们的几个问题:
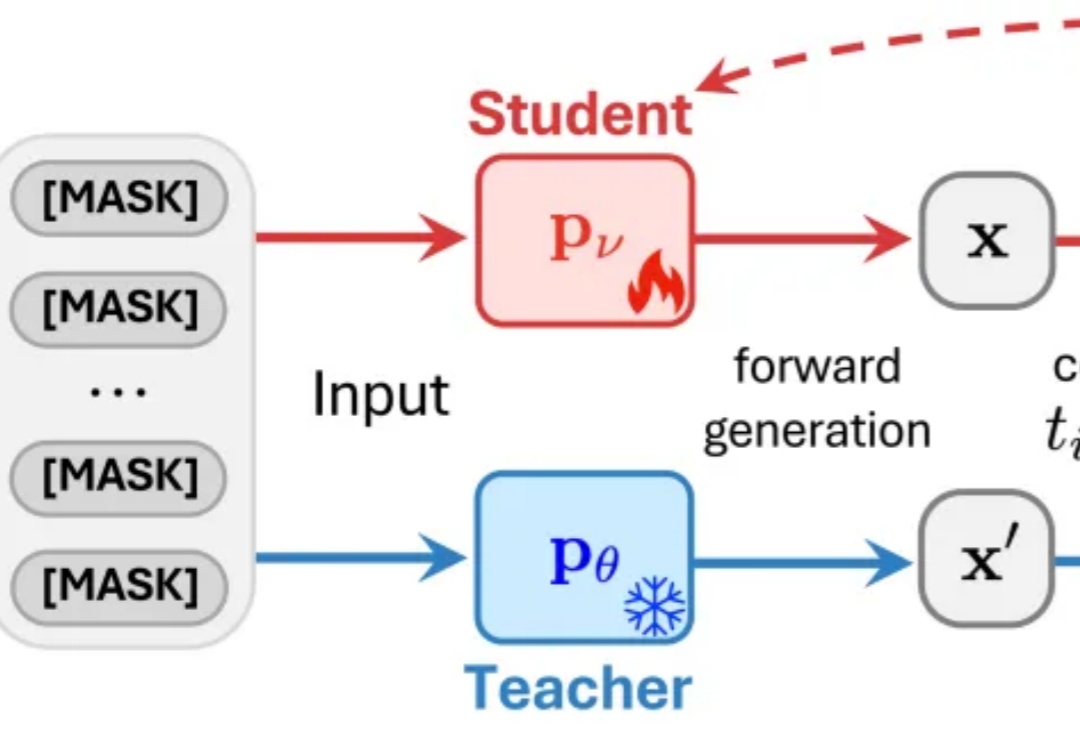
近日,来自普渡大学、德克萨斯大学、新加坡国立大学、摩根士丹利机器学习研究、小红书 hi-lab 的研究者联合提出了一种对离散扩散大语言模型的后训练方法 —— Discrete Diffusion Divergence Instruct (DiDi-Instruct)。经过 DiDi-Instruct 后训练的扩散大语言模型可以以 60 倍的加速超越传统的 GPT 模型和扩散大语言模型。

长期以来,扩散模型的训练通常依赖由变分自编码器(VAE)构建的低维潜空间表示。然而,VAE 的潜空间表征能力有限,难以有效支撑感知理解等核心视觉任务,同时「VAE + Diffusion」的范式在训练

近期,扩散语言模型备受瞩目,提供了一种不同于自回归模型的文本生成解决方案。为使模型能够在生成过程中持续修正与优化中间结果,西湖大学 MAPLE 实验室齐国君教授团队成功训练了具有「再掩码」能力的扩散语言模型(Remasking-enabled Diffusion Language Model, RemeDi 9B)。

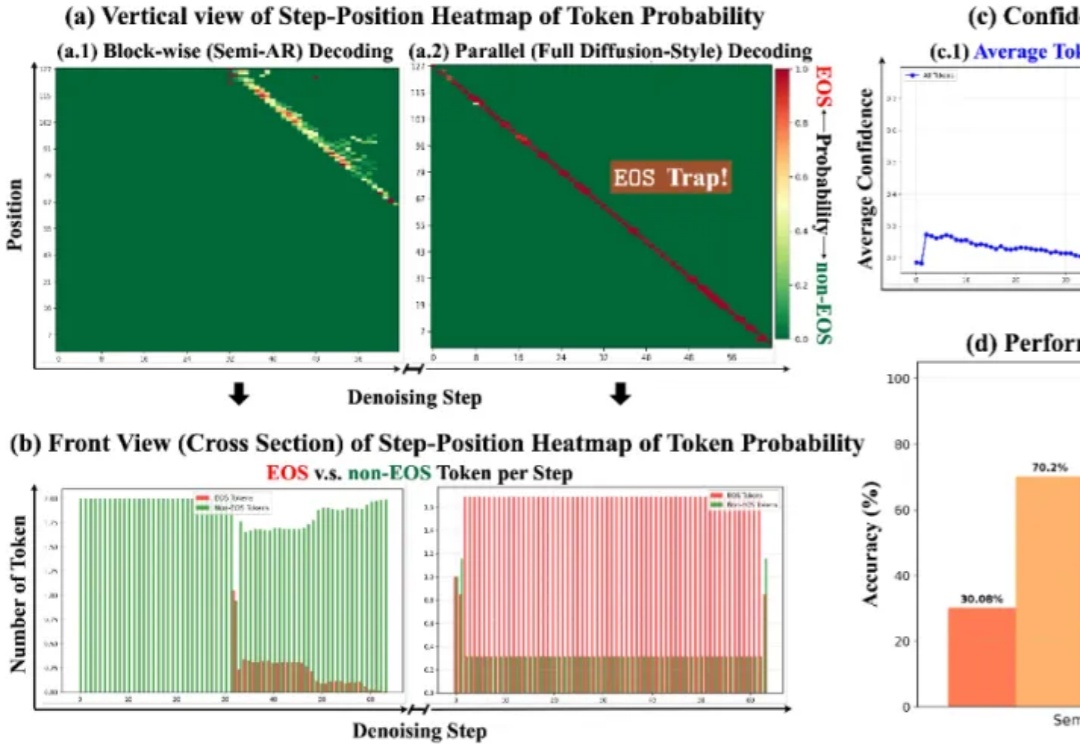
扩散语言模型(Diffusion Language Models,DLM)一直以来都令研究者颇感兴趣,因为与必须按从左到右顺序生成的自回归模型(Autoregressive, AR)不同,DLM 能实现并行生成,这在理论上可以实现更快的生成速度,也能让模型基于前后文更好地理解生成语境。
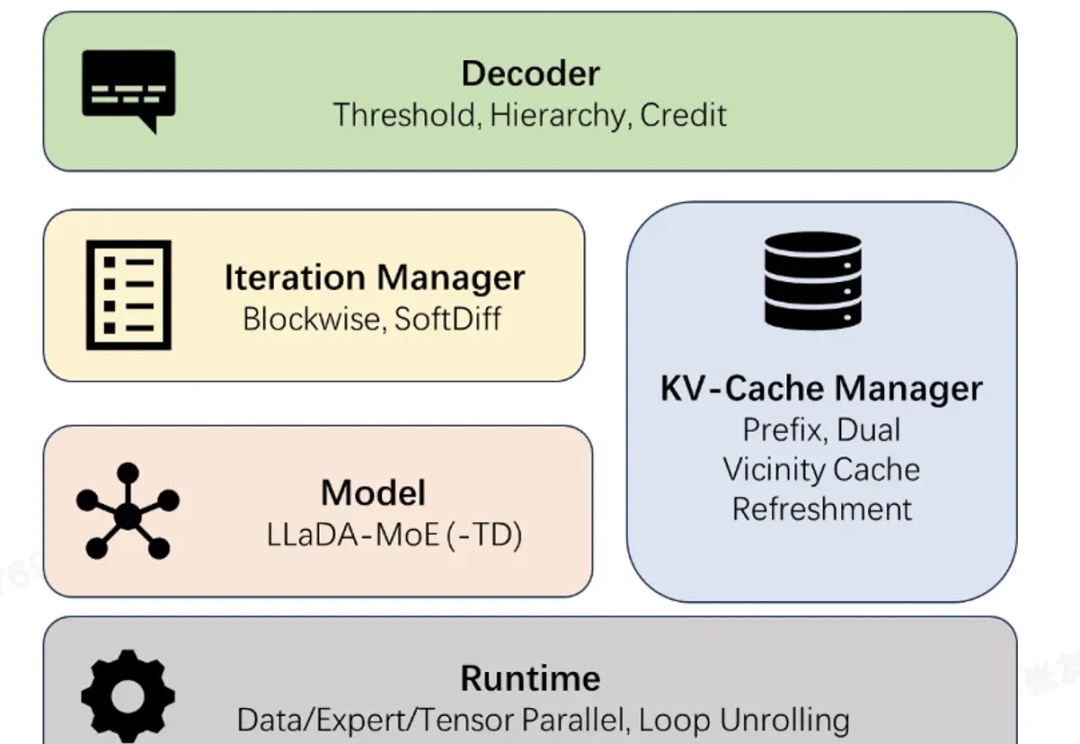
近日,蚂蚁集团正式开源业界首个高性能扩散语言模型(Diffusion Large Language Model,dLLM)推理框架 dInfer。