Writing-Zero: 打破 AI 写作天花板, 让 AI 写作更像"人"
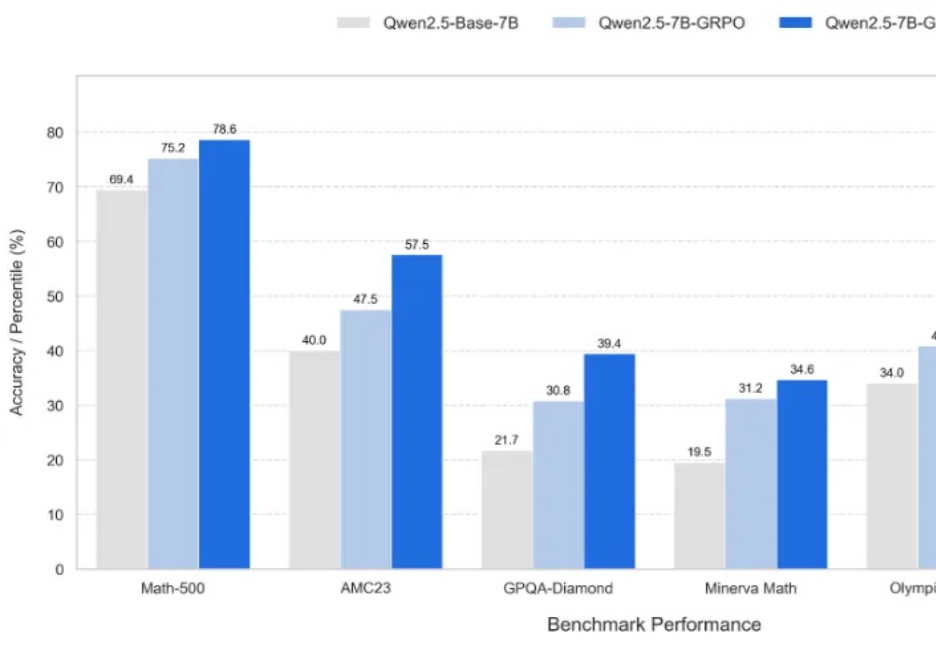
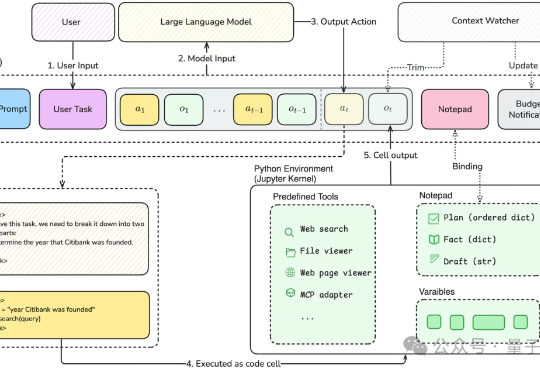
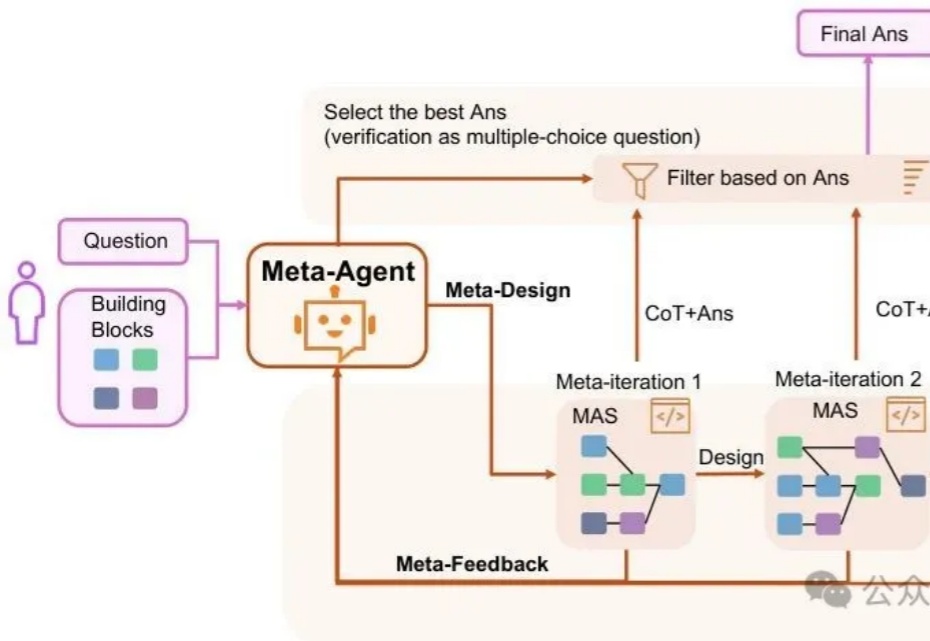
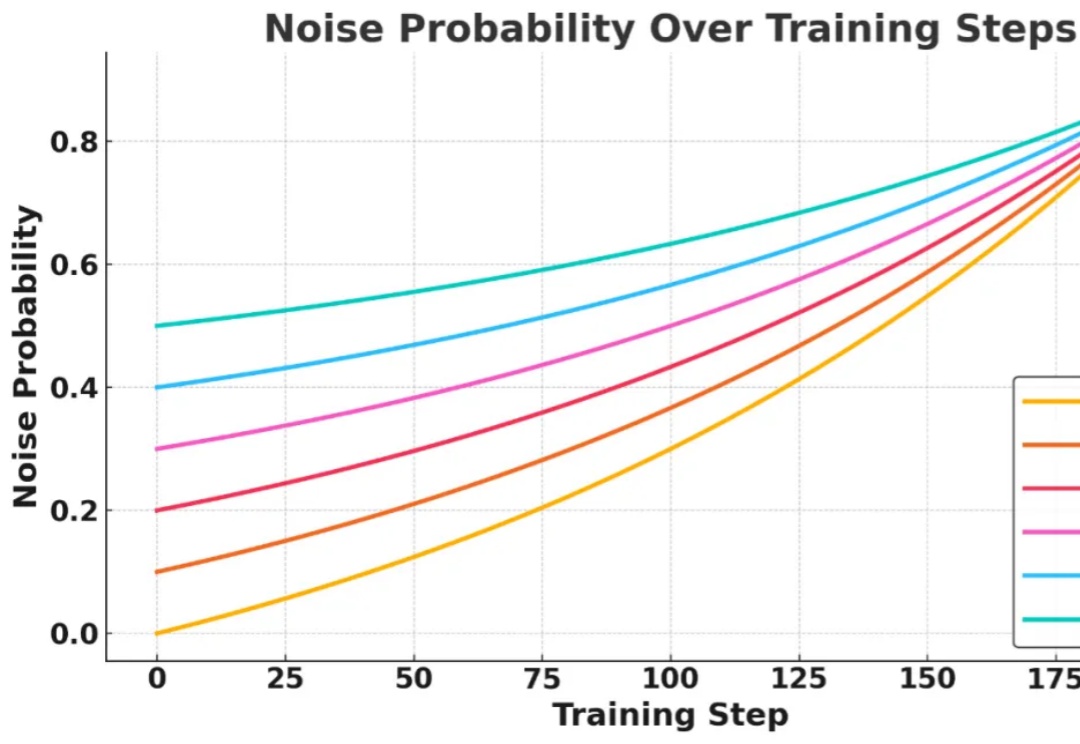
Writing-Zero: 打破 AI 写作天花板, 让 AI 写作更像"人"近年来, 大语言模型 (LLM) 在数学、编程等 "有标准答案" 的任务上取得了突破性进展, 这背后离不开 "可验证奖励" (Reinforcement Learning with Verifiable Rewards, RLVR) 技术的加持。RLVR 依赖于参考信号, 即通过客观标准答案来验证模型响应的可靠性。
来自主题: AI资讯
9072 点击 2025-07-31 11:02