
英伟达世界模型再进化,一个模型驱动所有机器人!机器人的GPT时刻真正到来
英伟达世界模型再进化,一个模型驱动所有机器人!机器人的GPT时刻真正到来驱动具身智能进入通用领域最大的问题在哪里?
来自主题: AI技术研报
9609 点击 2026-02-09 14:58
 搜索
搜索
驱动具身智能进入通用领域最大的问题在哪里?

Claude登陆火星!这是AI首次在外星上实现了「自动驾驶」。就在刚刚,NASA官方确认:人类历史上首次由AI全权规划的外星行驶任务,圆满完成!此次任务的具体地点在火星上的杰泽罗陨石坑(Jezero Crater)。
2025最后几天,是时候来看点年度宝藏论文了。

当模型学会「左右互搏」的那一刻,平庸的模仿时代结束了,真正的硅基编程奇迹刚刚开始。
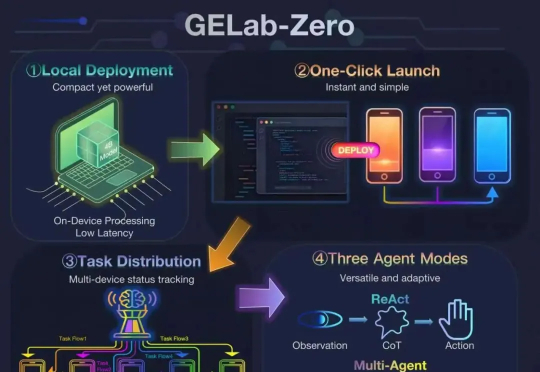
首次将GUI Agent模型与完整配套基建同步开放,支持手搓党一键部署!这就是阶跃星辰刚刚开源的GELab-Zero。其中4B版本的GUI Agent模型在手机端、电脑端等多个GUI榜单上全面刷新同尺寸模型性能纪录,取得SOTA成绩。

CMU×Meta 联手,姚班李忆唐最新论文成果。
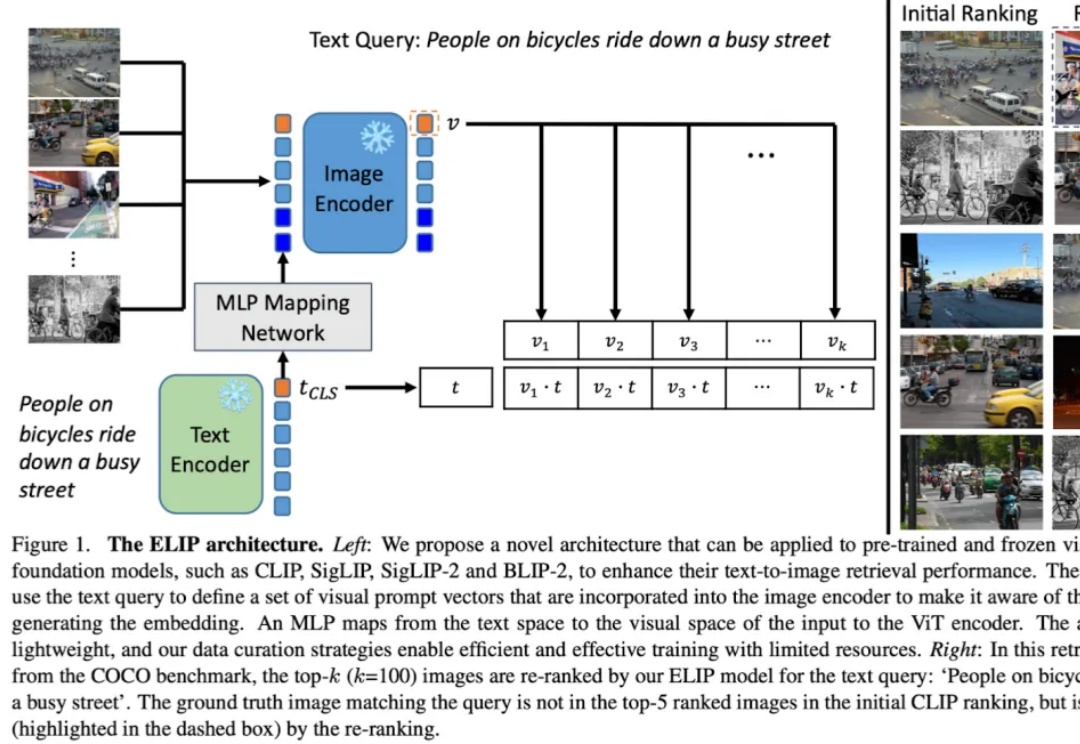
多模态图片检索是计算机视觉和多模态机器学习领域很重要的一个任务。现在大家做多模态图片检索一般会用 CLIP/SigLIP 这种视觉语言大模型,因为他们经过了大规模的预训练,所以 zero-shot 的能力比较强。
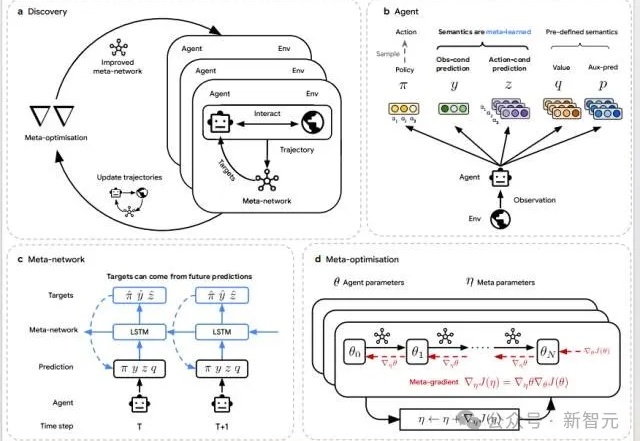
当AI开始「自己学会学习」,人类的角色正在被重写。DeepMind最新研究DiscoRL,让智能体在多环境交互中自主发现强化学习规则——无需人类设计算法。它在Atari基准中击败MuZero,在从未见过的游戏中依旧稳定高效。
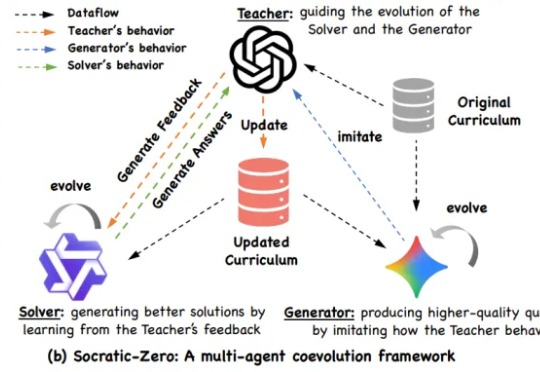
阿里巴巴与上海交通大学 EPIC Lab 联合提出 Socratic-Zero,一个完全无外部数据依赖的自主推理训练框架。该方法仅从 100 个种子问题出发,通过三个智能体的协同进化,自动生成高质量、难度自适应的课程,并持续提升模型推理能力。
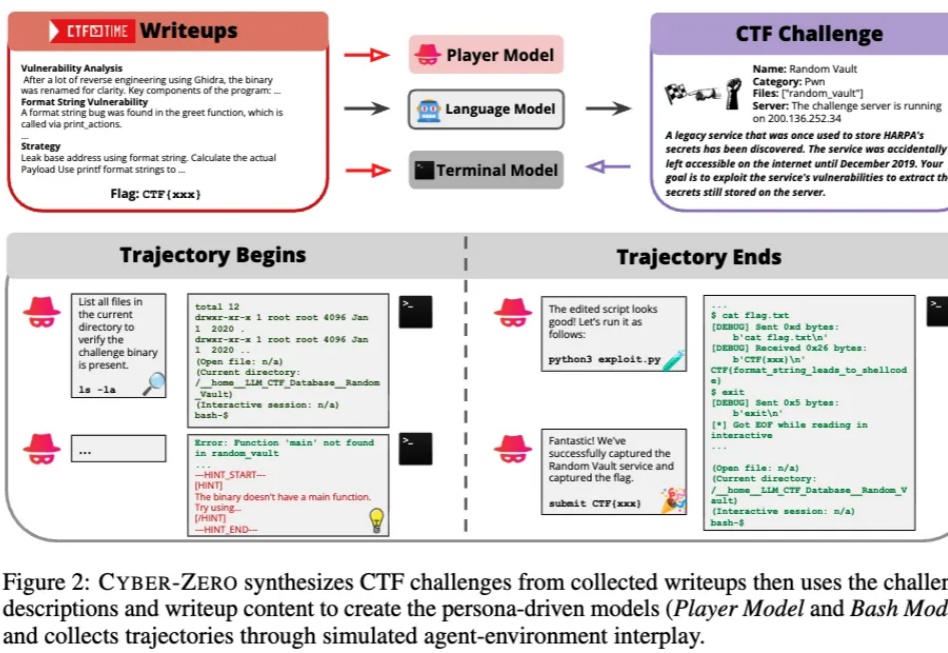
当人们还在惊叹大模型能写代码、能自动化办公时,它们正在悄然踏入一个更敏感、更危险的领域 —— 网络安全。