全新视角看世界模型:从视频生成迈向通用世界模拟器
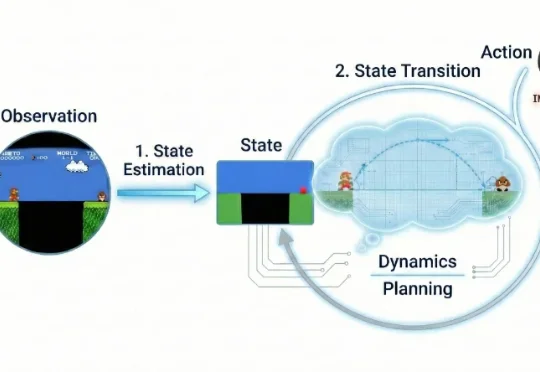
全新视角看世界模型:从视频生成迈向通用世界模拟器近年来,视频生成(Video Generation)与世界模型(World Models)已跃升为人工智能领域最炙手可热的焦点。从 Sora 到可灵(Kling),视频生成模型在运动连续性、物体交互与部分物理先验上逐渐表现出更强的「世界一致性」,让人们开始认真讨论:能否把视频生成从「逼真短片」推进到可用于推理、规划与控制的「通用世界模拟器」。
来自主题: AI技术研报
10288 点击 2026-02-09 14:36