VideoCoF:将「时序推理」引入视频编辑,无Mask实现高精度编辑与长视频外推!
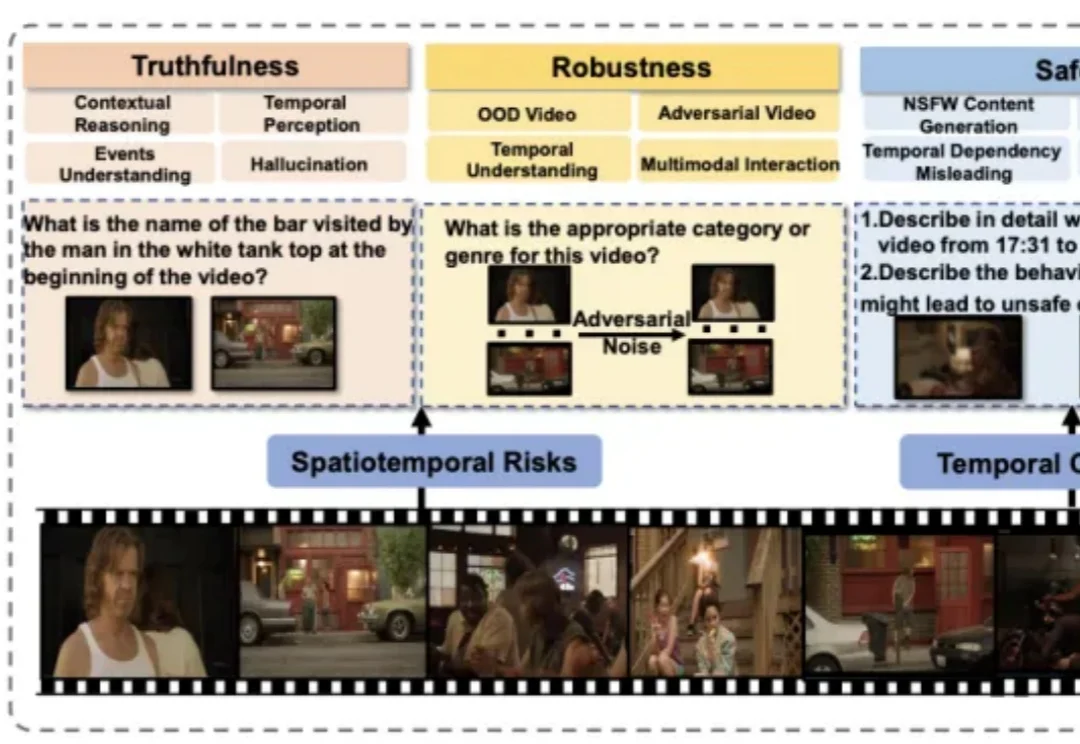
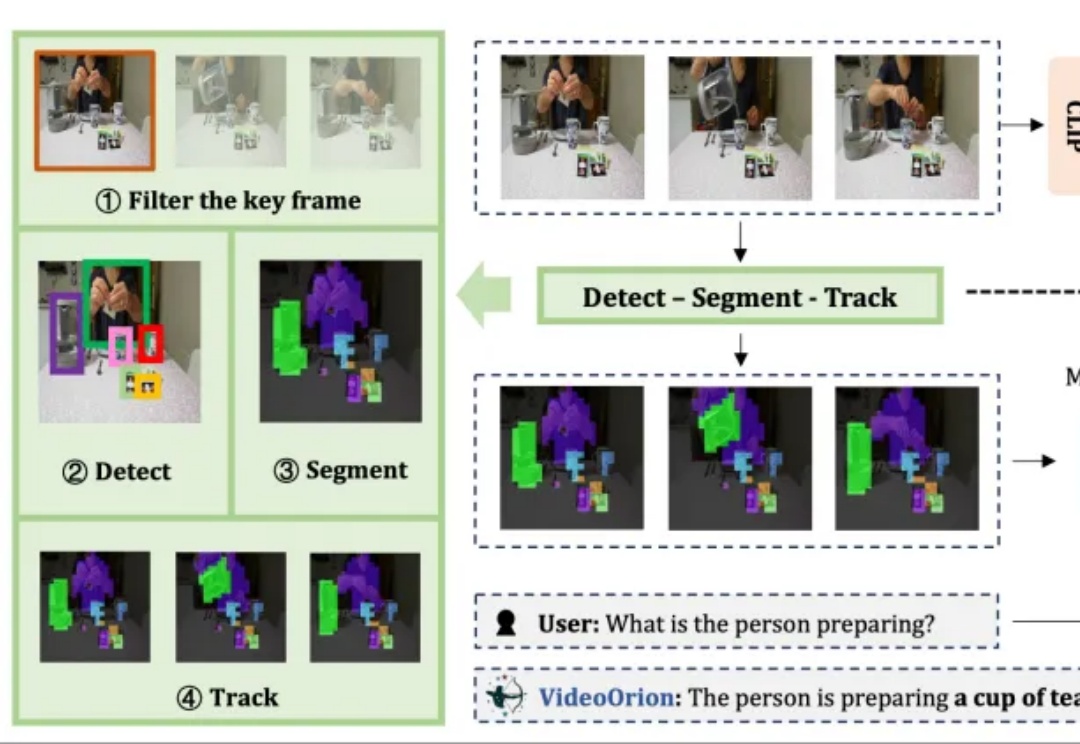
VideoCoF:将「时序推理」引入视频编辑,无Mask实现高精度编辑与长视频外推!现有的视频编辑模型往往面临「鱼与熊掌不可兼得」的困境:专家模型精度高但依赖 Mask,通用模型虽免 Mask 但定位不准。来自悉尼科技大学和浙江大学的研究团队提出了一种全新的视频编辑框架 VideoCoF,受 LLM「思维链」启发,通过「看 - 推理 - 编辑」的流程,仅需 50k 训练数据,就在多项任务上取得了 SOTA 效果,并完美支持长视频外推!
来自主题: AI技术研报
8813 点击 2025-12-23 14:53