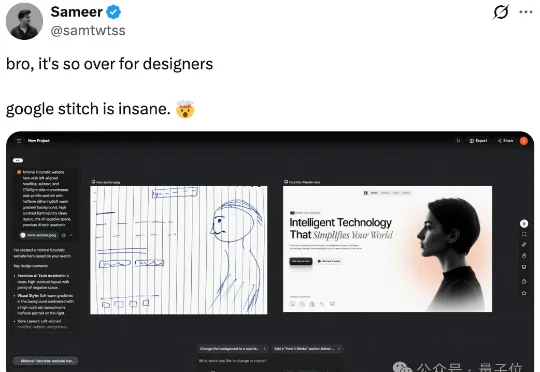
AI屠刀下一站“Vibe设计”!谷歌一个产品把合作伙伴Figma干崩了
AI屠刀下一站“Vibe设计”!谷歌一个产品把合作伙伴Figma干崩了谷歌宣布旗下AI设计工具Stitch支持Vibe Design。你都不需要键盘,只需要用嘴就可以vide design出这样婶儿的UI和前端界面:不得不说,谷歌的审美是真的好。Gemini 3生成前端的艺术效果就有口皆碑。
来自主题: AI资讯
8869 点击 2026-03-20 14:43
 搜索
搜索
谷歌宣布旗下AI设计工具Stitch支持Vibe Design。你都不需要键盘,只需要用嘴就可以vide design出这样婶儿的UI和前端界面:不得不说,谷歌的审美是真的好。Gemini 3生成前端的艺术效果就有口皆碑。

量子位获悉,前腾讯AI大牛刘威的创业项目,又有新进展。

最近,谷歌 NotebookLM 又出了个好玩好用的小功能:Cinematic Video Overviews(电影级视频概览)。与普通模板不同,这项功能可以根据我们上传的资料,自动生成定制化、沉浸式的视频讲解。
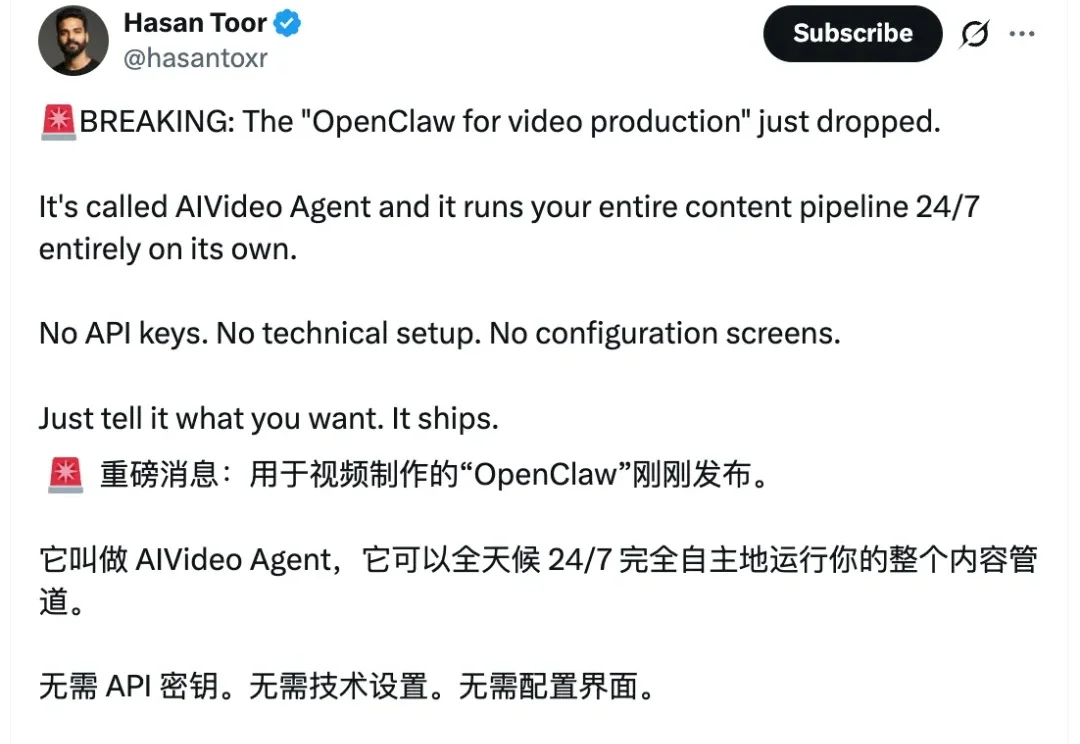
起猛了,现在龙虾也能做视频了???

视频生成进入大规模时代,但计算成本也炸了。
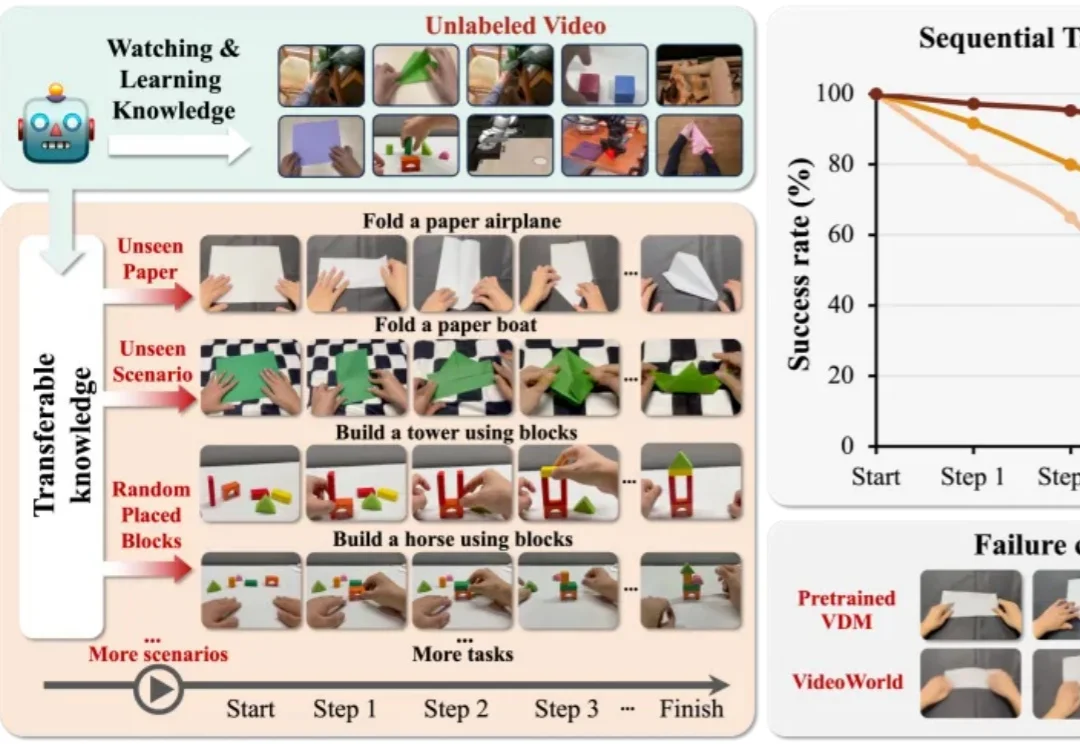
视觉世界模型 “VideoWorld 2” 由豆包大模型团队与北京交通大学联合提出。不同于 Sora 2 、Veo 3、Wan 2.2 等主流多模态模型,VideoWorld 系列工作在业界首次实现无需依赖语言模型,即可认知世界。
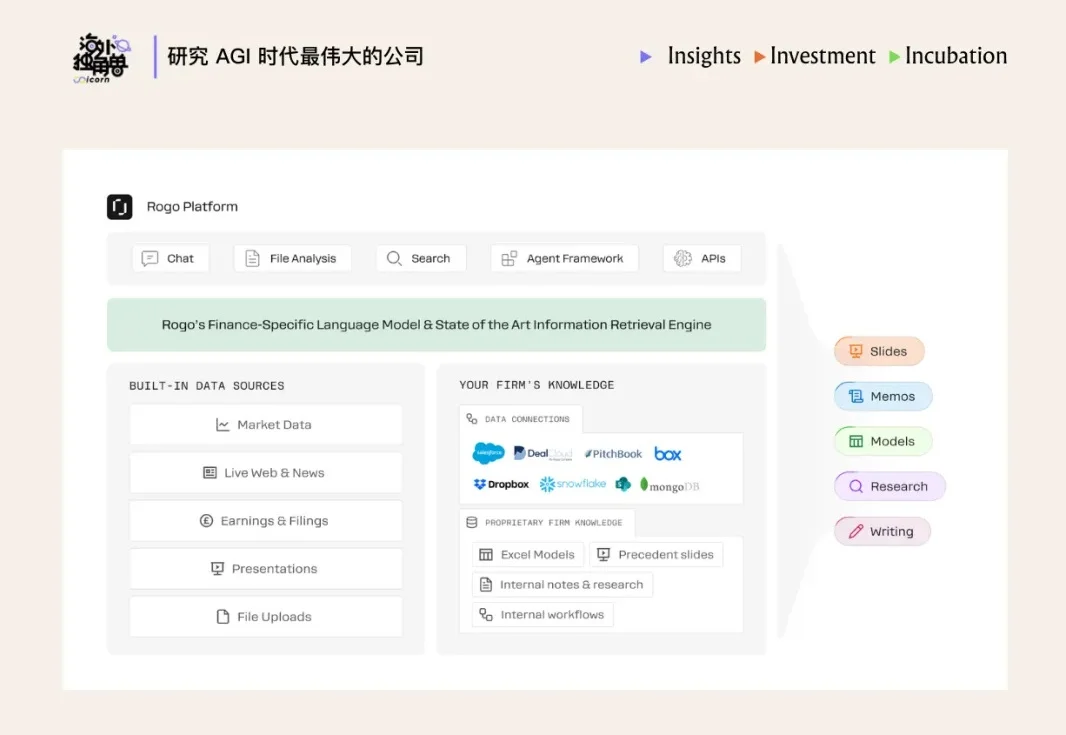
全球投行业每年处理超过 3.5 万亿美元的交易,但驱动这台庞大机器运转的,是数以万计每周工作超过百小时、从事着高度重复性劳动的初级分析师。Vertical Agent 开始加速很多专业领域的工作流,比如法律领域的 Harvey、医疗领域的 OpenEvidence,而在离钱最近的金融领域迟迟未能出现一款真正的统治级应用。
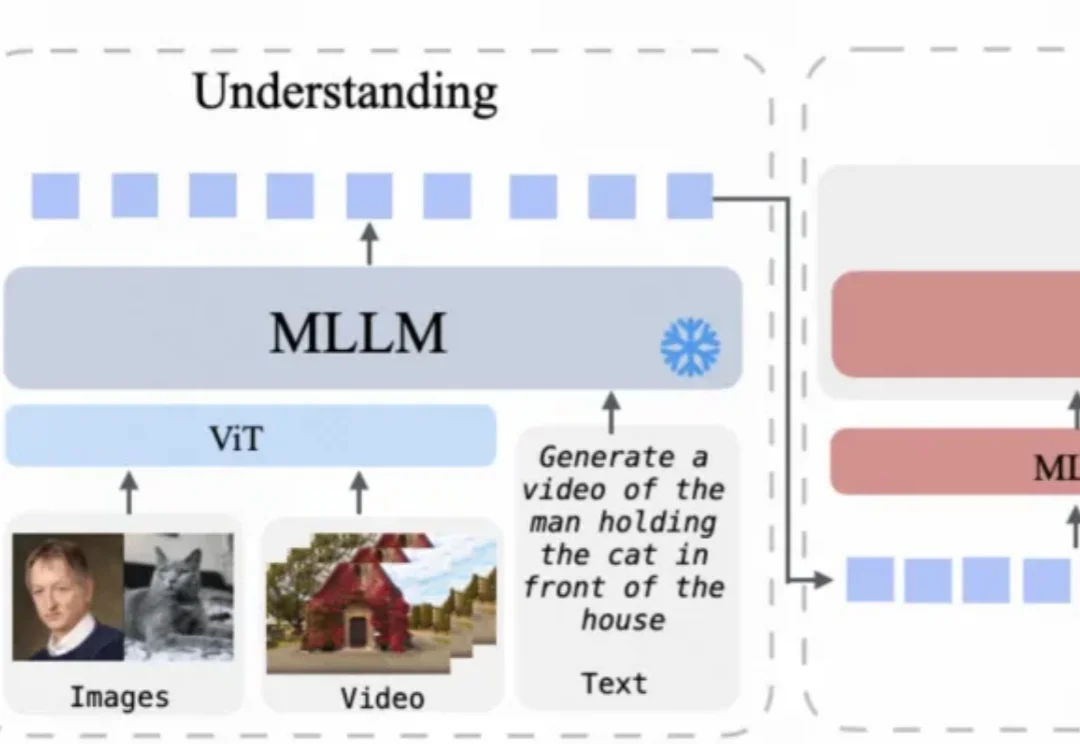
统一多模态模型在多模态内容理解与生成方面已展现出良好效果,但目前仍主要局限于图像领域。
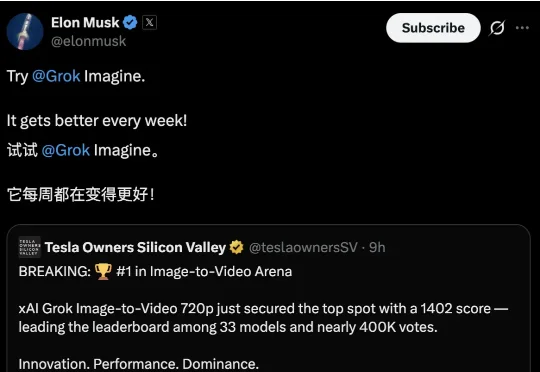
xAI的Grok图像转视频模型(grok-image-video-720p)登顶「Image-to-Video Arena」排行榜,以1404分的超高ELO评分力压群雄,位居第一。马斯克亲自发帖为自家Grok Image模型站台,称它每周都在迭代优化。
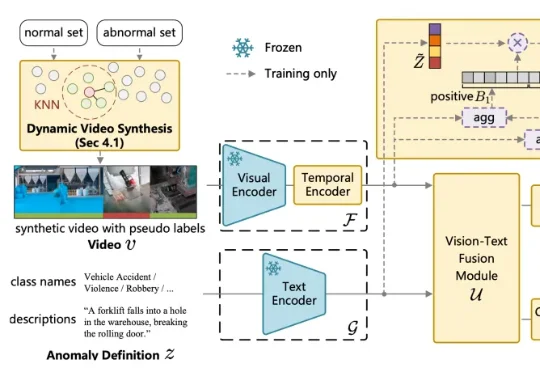
针对这一问题,中国传媒大学媒体融合与传播国家重点实验室的吴晓雨教授团队于 ICLR 2026 发表论文《Language-guided Open-world Video Anomaly Detection under Weak Supervision》,直面 VAD 领域的核心问题 —— 什么是异常?