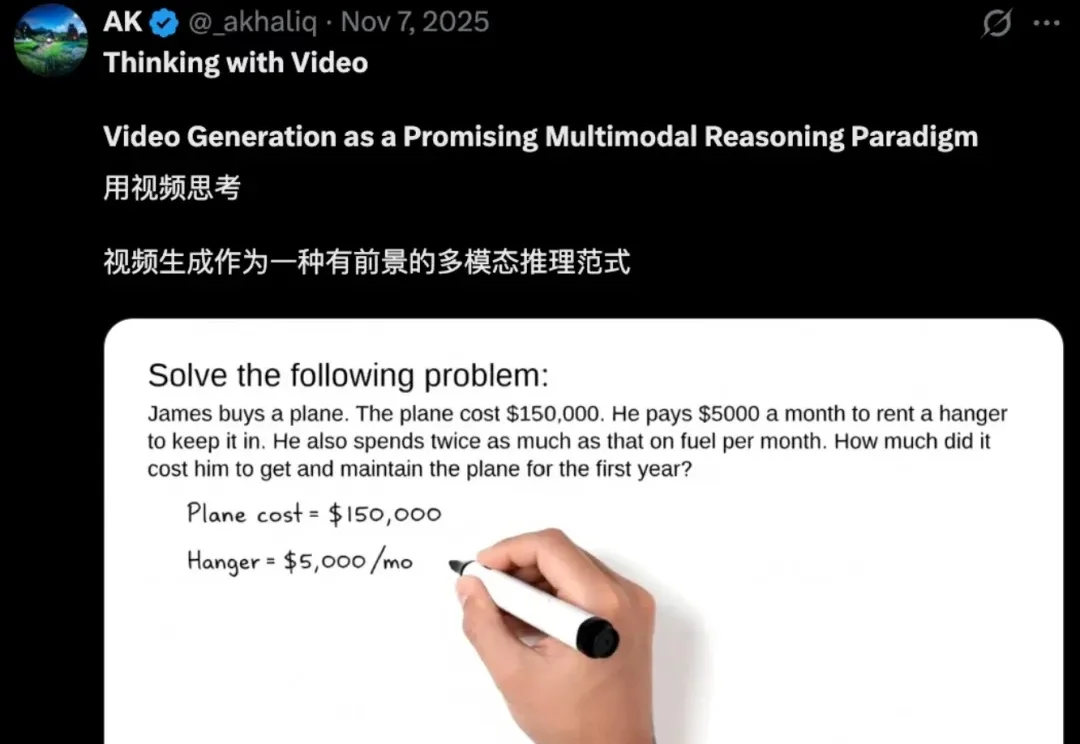
视频生成作为多模态推理新范式 | CVPR 2026
视频生成作为多模态推理新范式 | CVPR 2026被CVPR 2026收录!
来自主题: AI技术研报
9823 点击 2026-06-15 09:47
 搜索
搜索
被CVPR 2026收录!
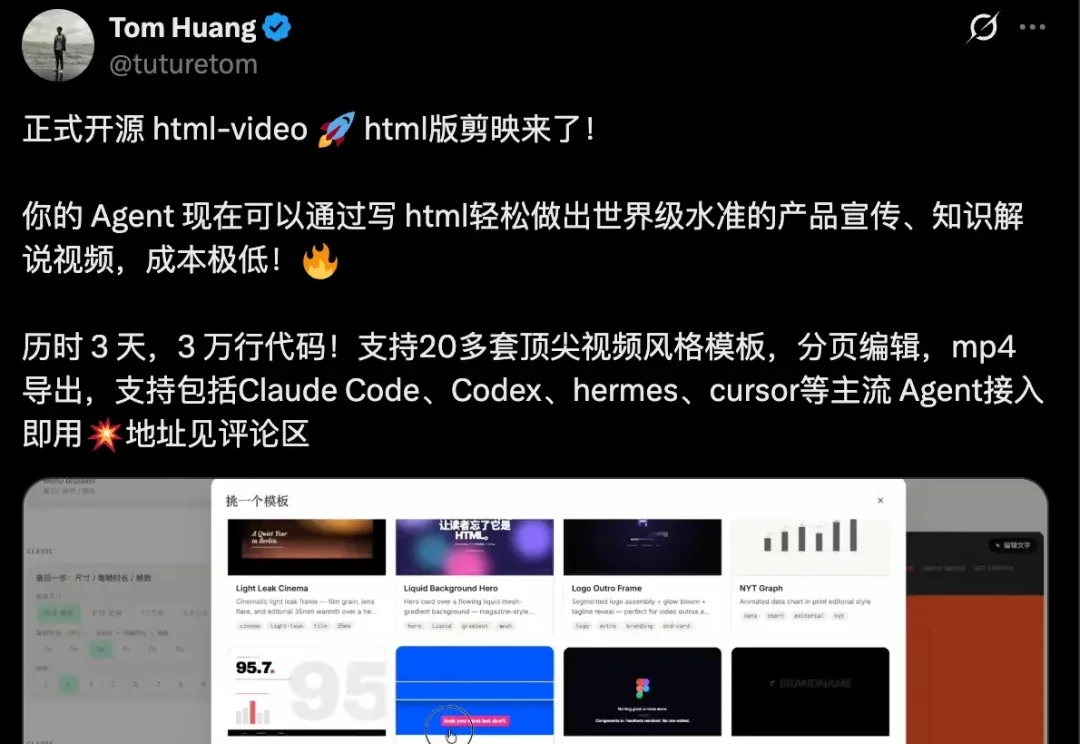
视频制作行业正在经历一场革命。

早在 2023 年大模型快速发展期,哈工大张民教授立知大模型团队已开展多模态大模型驱动的视频内容创作智能体研究,并全球首发开源了电影制作智能体 FilmAgent 与动画片生成智能体 Anim-Director,受到国内外智能体研究者与文艺创作者的广泛关注。
昨天,OpenDesign团队(nexu.io)释出了号称html版剪映的‘html-video’项目,完全开源:https://github.com/nexu-io/html-video。基于 hyperframes框架(https://github.com/heygen-com/hyperframes)构建,Apache 2.0 开源,由 Open Design 团队原班人马打造;
在这场日益蔓延的“Token焦虑”中,Agnes AI的举动显得格外扎眼——这家全球榜单排名第九的AI Lab宣布,自6月1日起,旗下全模态模型API无限期免费开放。Agnes AI本次开放覆盖其三款核心模型:文本模型Agnes-2.0-Flash、图像模型Agnes-Image-2.0-Flash以及视频模型Agnes-Video-V2.0。
就在今天,美团龙猫大模型团队突然开源了商用级数字人视频生成模型 LongCat-Video-Avatar 1.5。在权威评测中,它的用户偏好胜率全面超越 Kling Avatar 2.0、OmniHuman-1.5 和 HeyGen 这三个头部玩家,并且直接以 MIT 协议开放,连商用限制都懒得设。
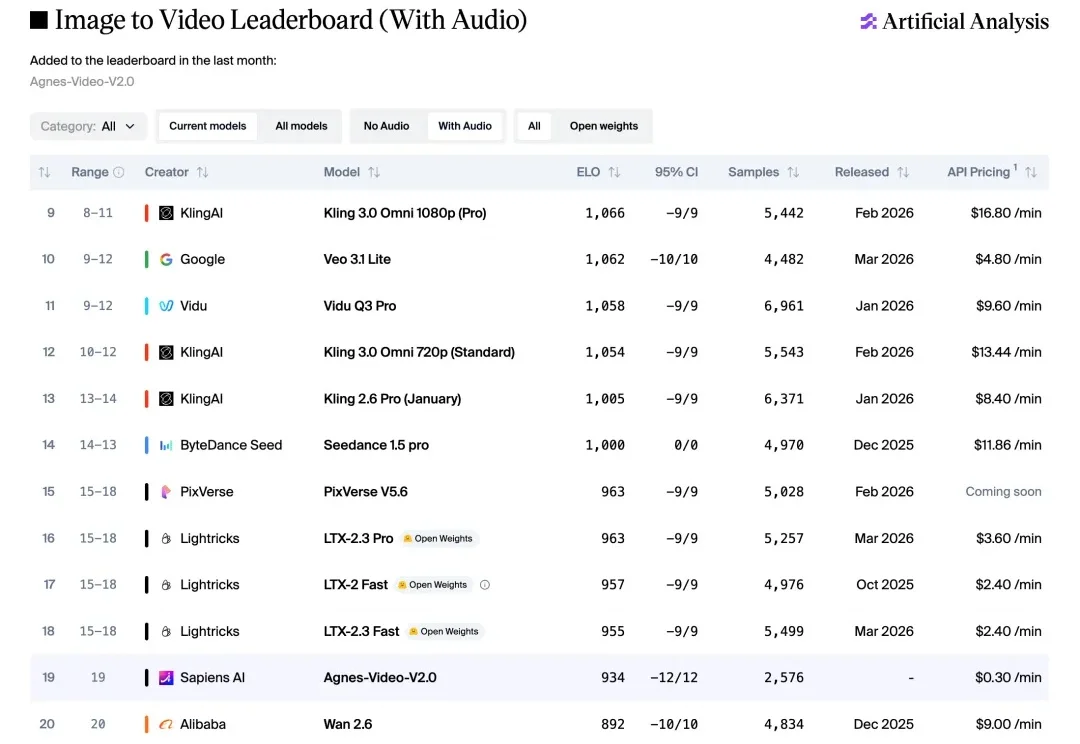
幽深森林,身着飘逸浅裙的乐手忘情地拉动琴弦。阳光穿透树冠洒落林间,斑驳光影与悠扬的琴声相融。镜头自低处仰拍环绕,营造出如梦似幻的氛围。
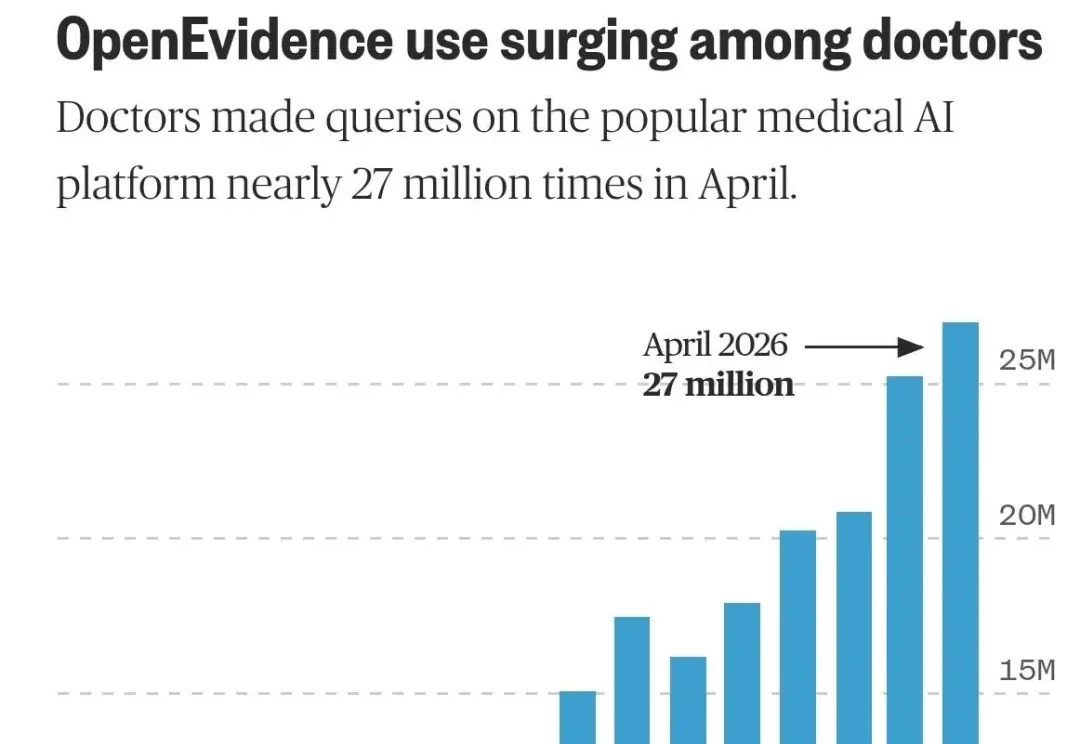
全网最火AI医疗,再创增长神话!

近日,由香港科技大学 MMLab 及合作团队完成的研究工作「UniVidX: A Unified Multimodal Framework for Versatile Video Generation via Diffusion Priors」被计算机图形学顶级会议 SIGGRAPH 2026 正式接收。
几天内席卷 Instagram 与 TikTok,海外播放突破 5000 万;用户可上传题目、选择喜欢的 AI Tutor 角色,并实时互动生成个性化视频讲解,让学习像刷短视频一样停不下来,验证了 AI-native 教育产品的新形态。