# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
为什么AI生成的视频总是模糊卡顿?为什么细节纹理经不起放大?为什么动作描述总与画面错位?
其中一个重要原因在于,现有的开源千万级视频数据集分辨率基本低于1080P(1920×1080),且大部分视频的说明(caption)简单粗糙,不利于大模型学习。
当主流视频生成模型还在720P画质挣扎时,浙江大学APRIL实验室联合多家高校推出的高质量开源UHD-4K(其中22.4%为8K)文本到视频数据集——UltraVideo,破解了这一困局。
该数据集涵盖广泛主题(超过100种),每个视频配备9个结构化字幕及一个总结性字幕(平均824词)。
作为全球首个开源4K/8K超高清视频数据集,UltraVideo配合结构化语义描述框架,让视频生成实现从“勉强能看”到“影院级质感”的跨越式进化。
团队基于42K精选视频微调的UltraWan-4K模型,实现三大突破:

当前视频生成面临两大瓶颈:
分辨率陷阱:模型在低清数据训练后,直接生成4K视频会出现严重失真。如图2所示,naïve Wan-T2V-1.3B在1080P生成时画质显著下降,而提升到4K(2160×3840)分辨率时完全失效。
语义鸿沟:简单文本描述无法很好地细致控制主题、背景、风格、镜头、光影等影视级参数。

然而,以电影级应用为目标的4K/8K内容生成急需超高清数据与结构化语义视频描述指导。
UltraVideo通过严苛四阶筛选实现视频质量跃迁:
源头把控:人工从YouTube精选5000部4K/8K原片,时长从1分钟到2小时不等,并对视频进行二次人工审核,以确保尽可能避免低质量、模糊、水印和抖动等问题,在源头把控视频质量而减少后续流程的漏检负载。
统计信息过滤:去OCR字幕、去黑边、曝光/灰度检测淘汰劣质视频片段
模型二次过滤:视频美学评估、时序运动打分、视频-文本一致性排序、基于MLLM的16种常见视频缺陷过滤。
结构化描述:基于Qwen2.5-VL-72B自动化caption管线,生成9类语义标签(镜头运动/光影/氛围等),并通过Qwen3-4B汇总总结描述(每个视频平均824个单词)。
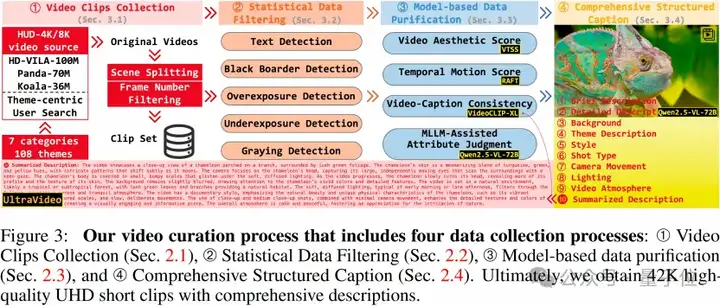
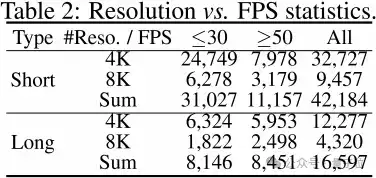
最终,团队获得了3s-10s的42k短视频和10秒以上的17k长视频,其中8K视频占比22.4%,以支持未来更高分辨率的研究。
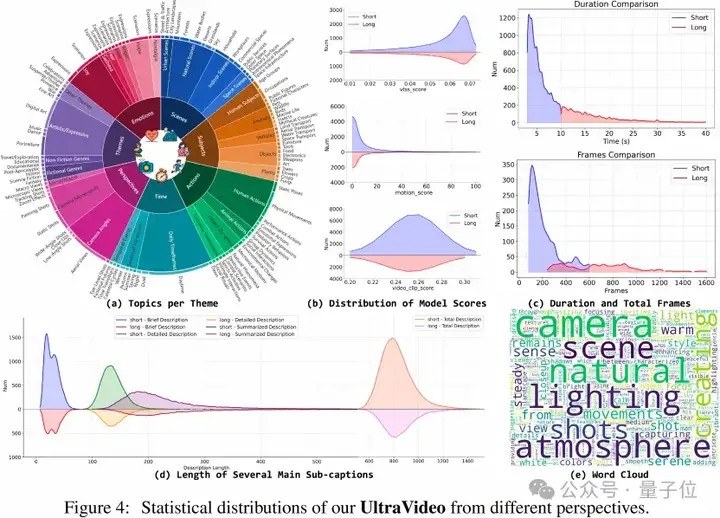
视频的主题多样性对视频模型的训练效果至关重要。团队对Koala-36M的标题进行了名词统计,经由LLMs和人工处理确认后,获得了七个主要主题(108个主题),即视频场景、主体、动作、时间事件、摄像机运动、视频类型以及情感。下图展示了对每个主题下不同主题的片段比例进行的统计分析。
基于UltraVideo数据集,团队在中小规模的Wan-T2V-1.3B上进行实验。
团队惊讶发现,仅用42K包含全面文本的极高视频质量数据就足以显著提升生成视频的审美和分辨率。
由于团队仅使用LoRA进行微调,并未涉及模型结构的修改,相关经验可以轻松地迁移到开源社区的其他T2V模型上。
此外,由于高分辨率需要更多的计算能力导致推理速度变慢,团队从VBench中随机抽取了十分之一(≃96)的提示进行测试。
如表4所示,团队比较了五个模型:(1)官方Wan-T2V-1.3B模型,分辨率为480×832(2)将分辨率提高到1K(1088×1920)(3)1K全参数微调(4)1K LoRA PEFT。(5)4K LoRA PEFT
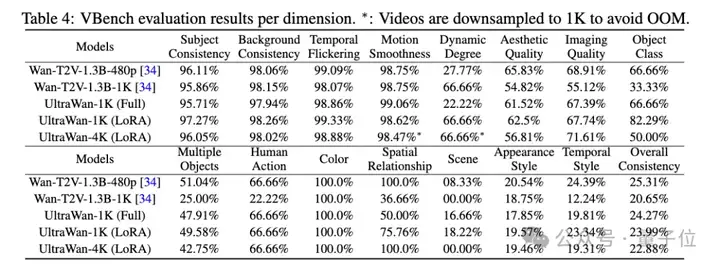
结果显示,
1、将官方模型扩展到1K会导致性能显著下降。
2、基于UltraWan-1K的全参数训练显著提升了1K分辨率下的生成效果。但与原生模型相比,训练超参数(如批大小和提示)的差异可能导致其整体结果略差于基于UltraWan-1K的LoRA模型。考虑到训练成本,研究团队推荐使用基于LoRA的UltraWan-1K方案。
3、更高的UltraWan-4K模型在图像质量和时间稳定性相关的指标上表现更好。但其较低的帧率(推理使用33帧以确保时间超过1秒)导致某些指标与UltraWan-1K相比有所下降。
团队基于42K精选视频微调的UltraWan-4K模型,实现三大突破——原生4K生成:直接输出4K(3840×2160)分辨率视频;语义精准控制:利用结构化描述实现镜头语言控制;资源高效:仅用LoRA轻量化训练,单卡可部署。
下图展示了定性的效果对比。官方的Wan-T2V-1.3B无法直接生成高分辨率1K视频,而UltraWan能够处理语义一致的1K/4K生成任务。

这是首次证明,少量极致质量数据,能突破视频生成的分辨率天花板。
在UltraVideo中,通过调整分辨率、帧率和音频,它可以轻松适应任何超高清环境下的相关视频任务,例如探索低级UHD视频超分辨率、帧插值、编解码器,以及高级视频编辑、逐帧处理、音乐生成。
这项工作不仅填补了高分辨率视频生成研究中的重要空白,还通过新颖的数据集构建、先进的数据处理流程和精炼的模型架构推动了技术前沿,为未来UHD视频生成的突破奠定了基础。
团队计划在未来利用长时序子集深入探索长视频生成任务。团队表示,UltraVideo已全面开源,同时也开源了UltraWan-1K/4K LoRA权重。
论文:https://arxiv.org/abs/2506.13691
项目主页:https://xzc-zju.github.io/projects/UltraVideo/
数据集:https://huggingface.co/datasets/APRIL-AIGC/UltraVideo
模型:https://huggingface.co/APRIL-AIGC/UltraWan
Demo展示:https://www.youtube.com/watch?v=KPh62pfSHLQ
文章来自于“量子位”,作者“浙大APRIL实验室团队”。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
