
首创TTFA指标!港大团队开源FASTER,让VLA模型真正实现「即刻响应」
首创TTFA指标!港大团队开源FASTER,让VLA模型真正实现「即刻响应」具身智能正以前所未有的速度发展,VLA 模型展现出越来越强的动作和泛化能力。然而,当我们真正把 VLA 模型部署到物理世界时,一个核心挑战浮出水面:实时性。
来自主题: AI技术研报
8309 点击 2026-05-15 09:55
 搜索
搜索
具身智能正以前所未有的速度发展,VLA 模型展现出越来越强的动作和泛化能力。然而,当我们真正把 VLA 模型部署到物理世界时,一个核心挑战浮出水面:实时性。

开普勒机器人前 CEO 胡德波已开启具身智能赛道的第二次创业,新公司名为「索塔无界」。这一次,他选择了一条和开普勒不同的路。索塔无界将在今年夏天展示完整大脑能力,包括世界模型、多模态 VLA 以及 Physica-Claw 机器人操作系统,并在实验室跑通早期商业场景全流程。
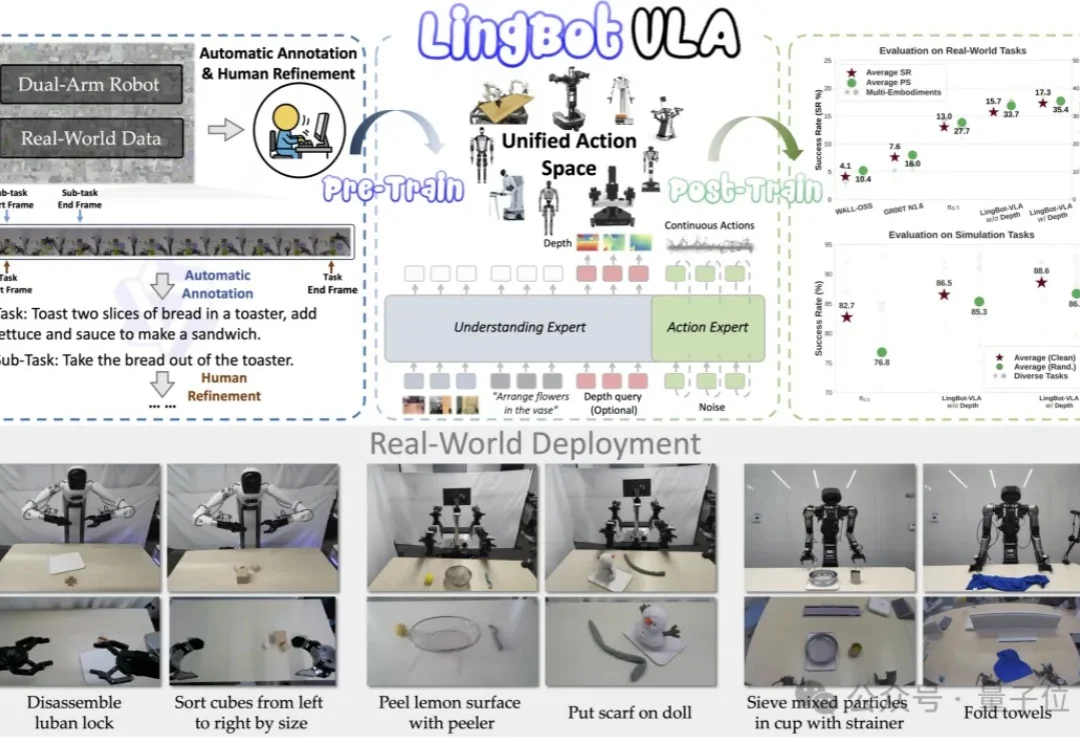
就在刚刚,蚂蚁集团旗下具身智能公司灵波科技传出新动作—— 全面开源其具身基座模型LingBot-VLA的真机后训练工具链。
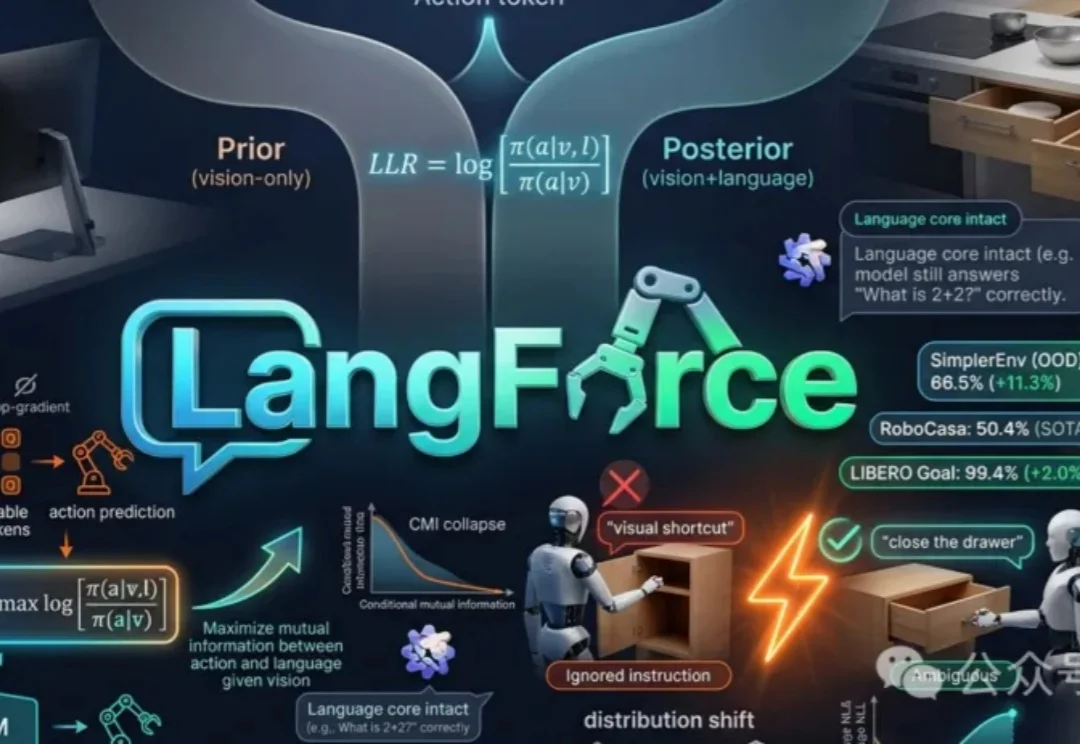
当前VLA模型常依赖视觉线索而非语言指令,导致在新场景下表现不佳。论文提出LangForce方法,通过引入对数似然比损失,强化模型对语言的依赖,提升其在分布外环境中的泛化能力,并保留语言核心功能。

近日,原力灵机开源的具身智能原生框架 Dexbotic 宣布正式支持以 RLinf 作为其分布式强化学习后端。对具身智能开发者而言,这不仅是一次普通的工程适配,更意味着 VLA 模型研发中长期存在的「SFT 与 RL 割裂」问题,正在被真正打通。

2026 年,「数据」正成为具身智能竞赛的新焦点,京东、百度等科技巨头纷纷入局。然而,喧嚣之中,一个根本问题悬而未决:什么样的数据,才是具身智能真正需要的?

智元机器人的办公室里,最近员工们一上班就能看到机器人熟练地切着水果:这么全面的能力是如何做到的?答案是直接在真实环境中搞大规模分布式强化学习训练。它们使用的是全新的具身智能训练范式:面向通用机器人策略的分布式多机强化学习(LWD)。这一套技术捅破了当前VLA的「天花板」。

今天,大洋彼岸,硅谷自动驾驶领域的秘密,终于有大佬站出来分享了。如果你对自动驾驶、人形机器人中炙手可热的 VLA、世界模型还有疑惑,全球“物理 AI” 领域头部的基础设施平台 Applied Intuition 两位创始人:CEOQasar Younis、CTO Peter Ludwig的分享可真的是太对口了。

就在这一背景下,银河通用联合清华北大英伟达等众多机构联合发布了跨本体「隐式世界-动作基础模型」LDA-1B,将目光投向了具身智能 Scaling Law 的这个终极命题:如何让模型有效利用互联网规模的异构数据。

就在刚刚,自变量机器人发布了全球首个世界统一模型架构的具身智能基础模型:WALL-B。基于世界统一模型,WALL-B解决了传统VLA架构在模块间数据搬运上的bug点——