π0.7发布,VLA押出了机器人的GPT-3时刻
π0.7发布,VLA押出了机器人的GPT-3时刻今天凌晨,Physical Intelligence发布了全新的VLA模型π0.7,狠狠敲了世界模型一记闷棍。π0.7第一次在机器人领域证明了Compositional Generalization(组合泛化),且VLA。
来自主题: AI资讯
8341 点击 2026-04-17 15:18
 搜索
搜索
今天凌晨,Physical Intelligence发布了全新的VLA模型π0.7,狠狠敲了世界模型一记闷棍。π0.7第一次在机器人领域证明了Compositional Generalization(组合泛化),且VLA。
最近,具身智能圈被 Generalist CEO 的一篇长文《Going Beyond World Models & VLAs》刷屏。文章抛出了一个看似振聋发聩的观点:目标远比工具标签更重要。与其陷入 “我们到底是在做 VLA(视觉 - 语言 - 动作模型)还是世界模型(World Model)” 的教条之争,不如回归本源:让机器高效、准确地作用于物理世界。
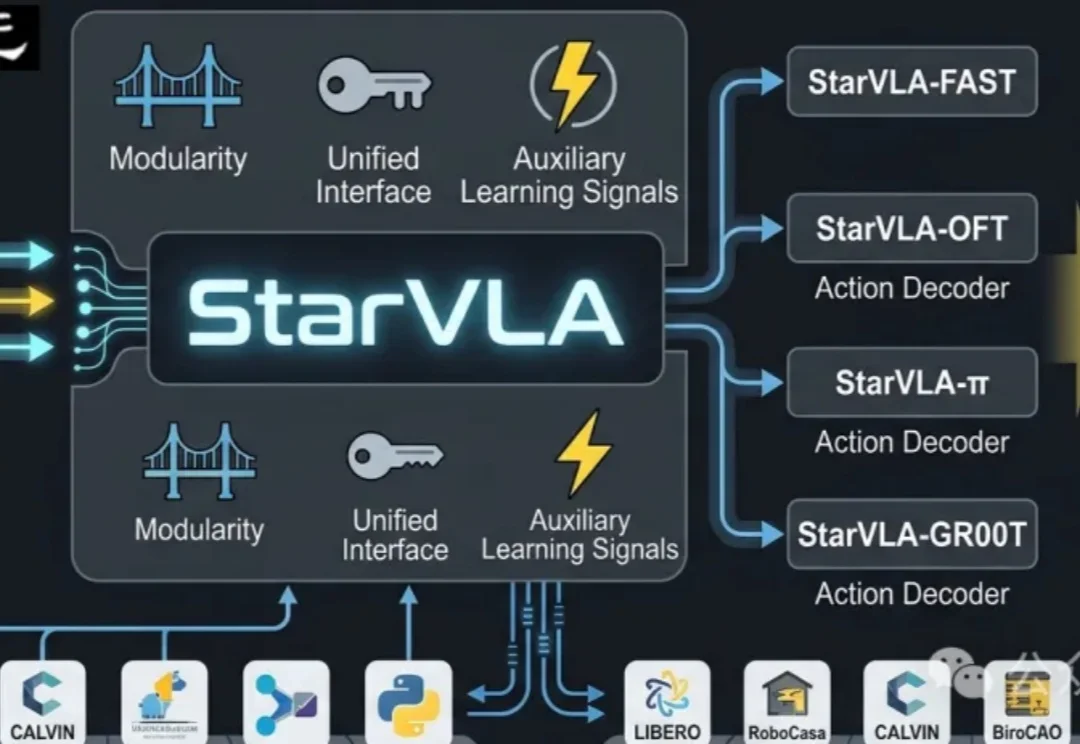
当前具身智能的VLA(Vision-Language-Action)赛道正陷入典型的「碎片化」泥潭:不同团队采用异构的动作解码范式、强耦合的数据管线、互不兼容的评测协议,导致方法难以横向对比,复现成本极高。

这个月,具身智能领域又卷出新高度:硅谷独角兽公司 Generalist AI 发布全新一代基础模型 GEN-1,将机器人包装手机、折纸箱这些活的平均成功率直接拉到了创纪录的 99%,折纸箱的速度更是飙到了以前的三倍(34s vs 12.1s)。

从 2024 年底的关于潜在空间的早期探索,再到 2025 年底和 2026 年初的相关研究爆发,潜空间范式正在彻底重塑大模型 (LLMs, VLMs, VLAs 等延伸模型) 的底层设计逻辑。

具身数据层的全球竞赛正在迅速升温。NVIDIA Research在2026年发布EgoScale数据与训练框架,在Ego-centric人类操作视频上训练VLA模型,用 20,854小时带动作标注的第一人称人类视频,观察到数据规模和验证损失之间接近对数线性的scaling law。1X收集人类第一视角及家庭行为数据,通过 Sunday项目采集百万小时级家庭场景视频。
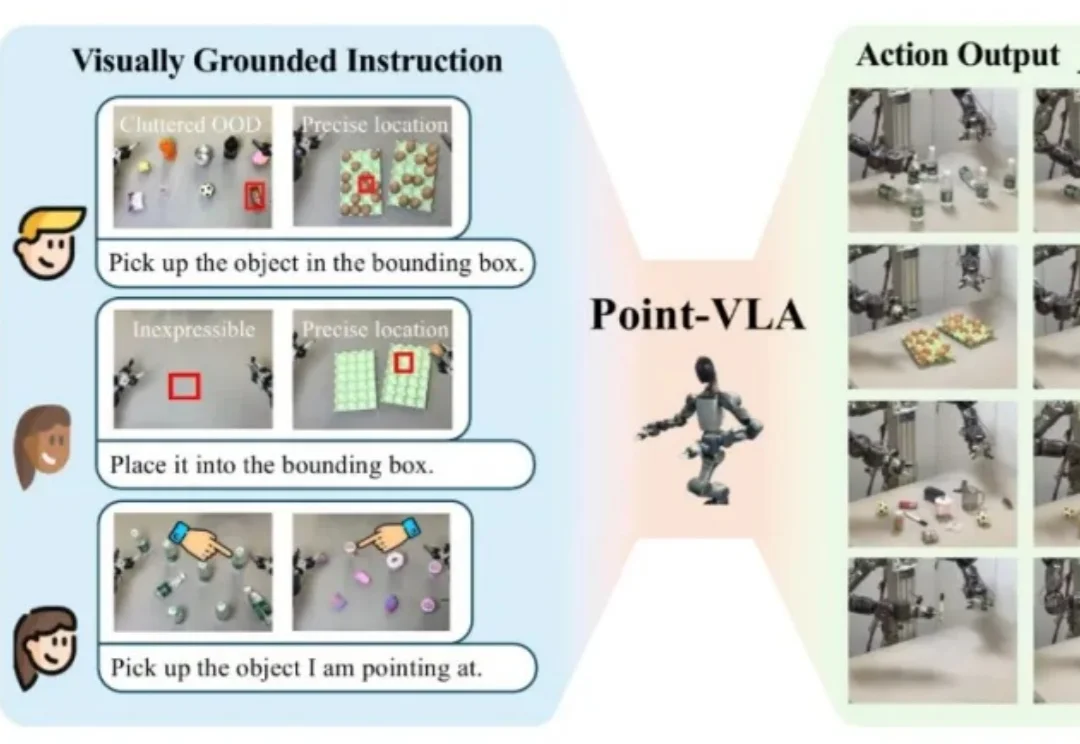
设想这样一个场景:你打电话让同事去办公室某个地方拿东西,仅凭语言描述位置是多么困难。在办公室里,从一堆已经喝过的矿泉水瓶中,让对面同学递过来你之前喝过的那个,只用语言几乎无法准确描述——「左边第二个」?「有点旧的那个」?这时候,人们更倾向于用手指一下,或者拿出图片来指代。
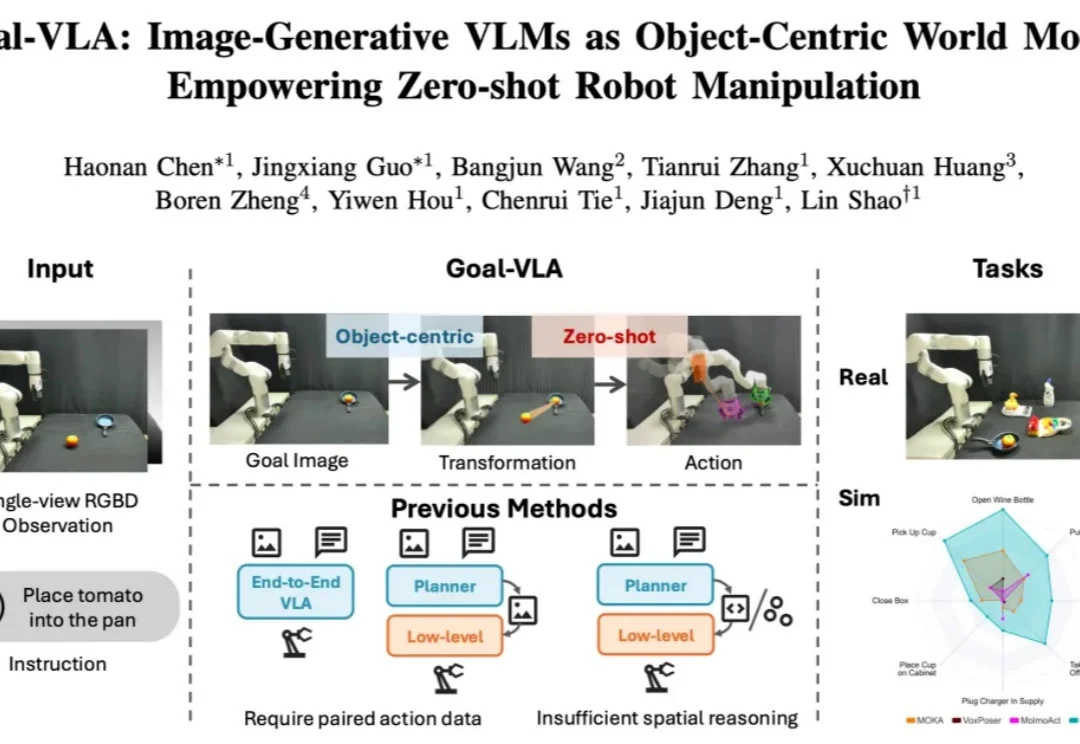
在具身智能领域,机器人操作的泛化能力一直是一个核心挑战。当前,视觉 - 语言 - 动作(VLA)模型主要分为两大范式:端到端模型与分层模型。端到端 VLA 模型(如 RT-2 [1], OpenVLA [2])严重依赖海量的 “指令 - 视觉 - 动作” 成对数据,获取成本极高,导致其在面对新任务或新场景时零样本泛化能力受限。
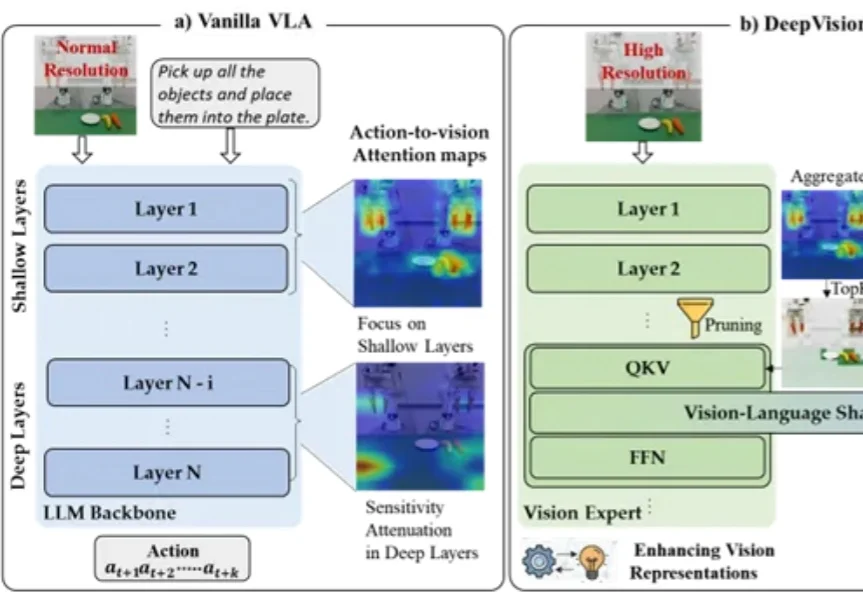
“把水果放进盘子里”——机器人看懂了指令,开始执行,却在最后关头抓偏了。
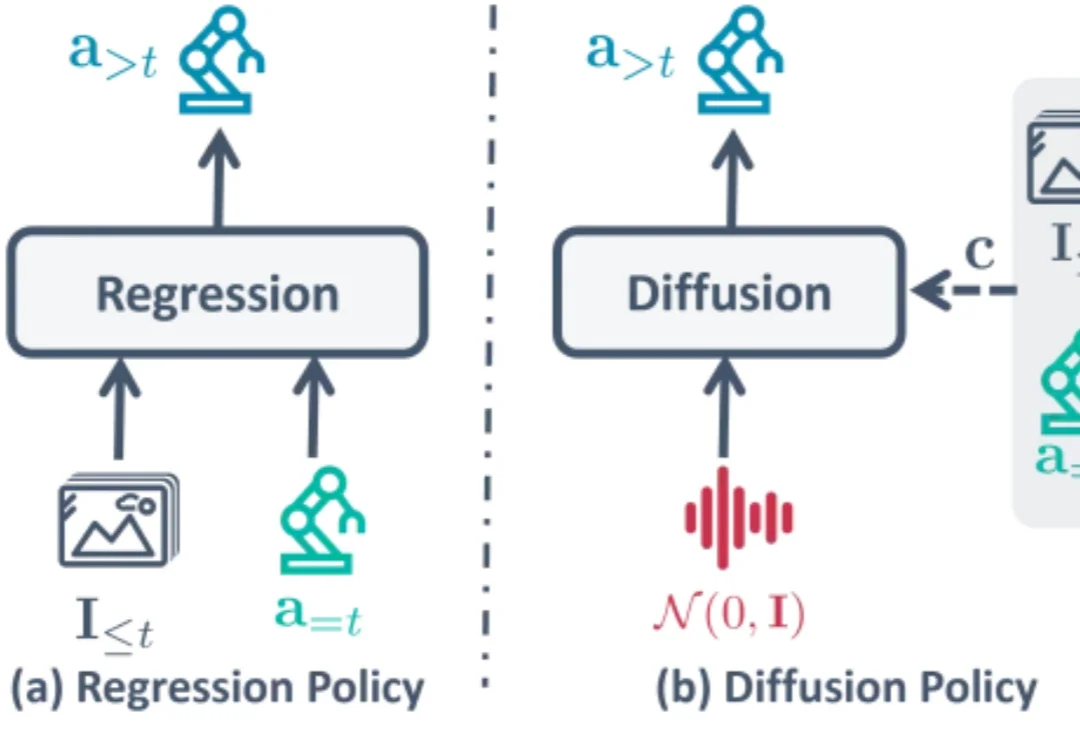
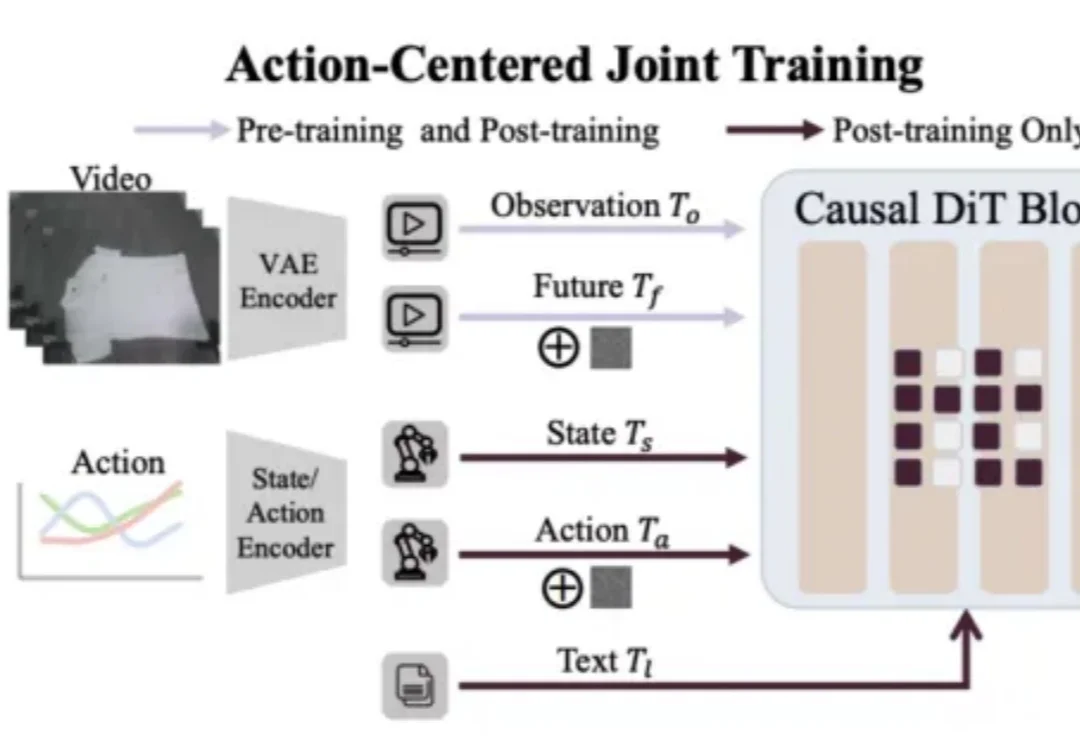
在机器人领域,扩散策略(Diffusion Policy)已经成为了标准模仿学习策略和 VLA 动作生成范式,但其「从随机噪声中迭代解噪」的机制带来了不容忽视的推理延迟。如果机器人不再从随机高斯噪声开始「盲猜」,是否可以基于「刚刚做了什么」来预测「下一步做什么」呢?