不再只是「会走路的双臂平台」:OpenHLM解放人形机器人的全身移动操作能力
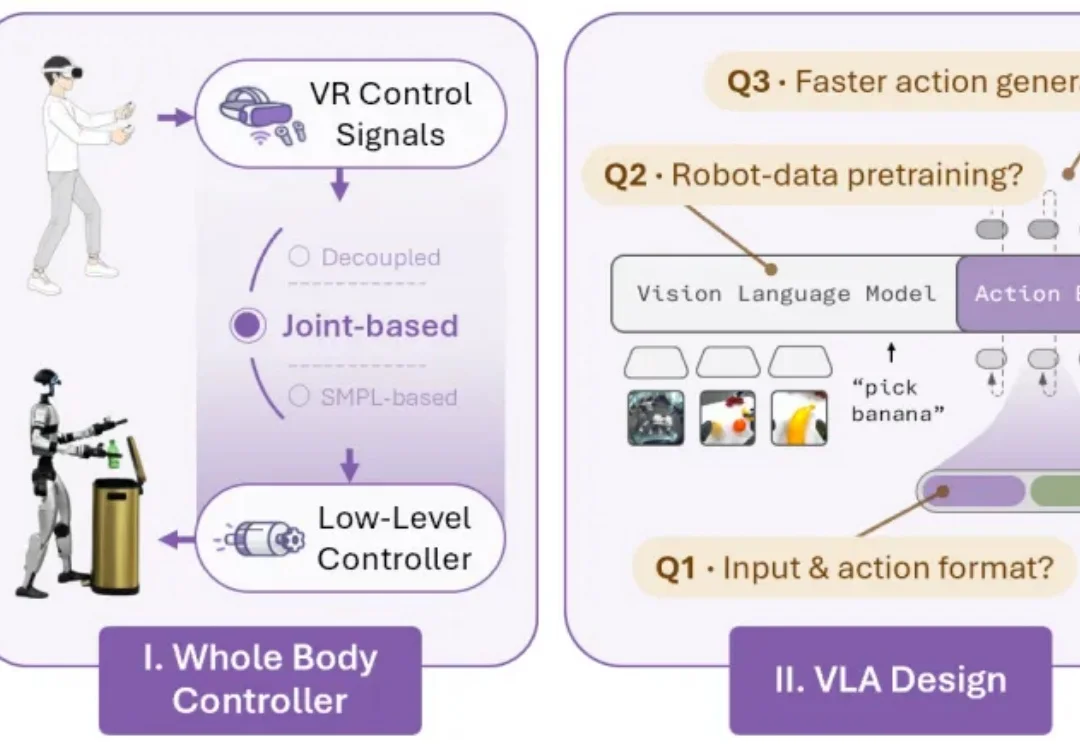
不再只是「会走路的双臂平台」:OpenHLM解放人形机器人的全身移动操作能力人类在日常生活中协调全身来完成移动操作任务:打开垃圾桶时会踩下踏板,从低处拿东西时需要下蹲,推车时需要同步协调手臂抓握和腿部移动。对试图复刻人类能力的人形机器人来说,身体不应只是「手臂 + 移动平台」,而应是一个能协调手、腰、腿、脚共同完成任务的运动整体。
来自主题: AI技术研报
5814 点击 2026-06-29 09:21