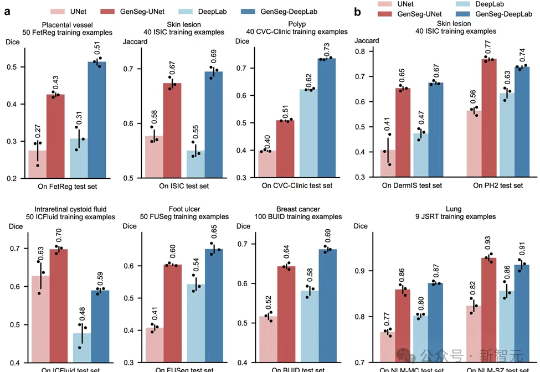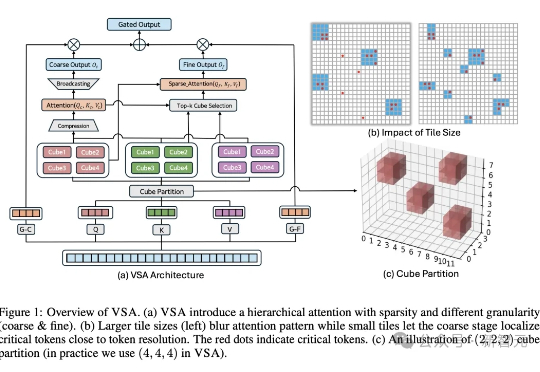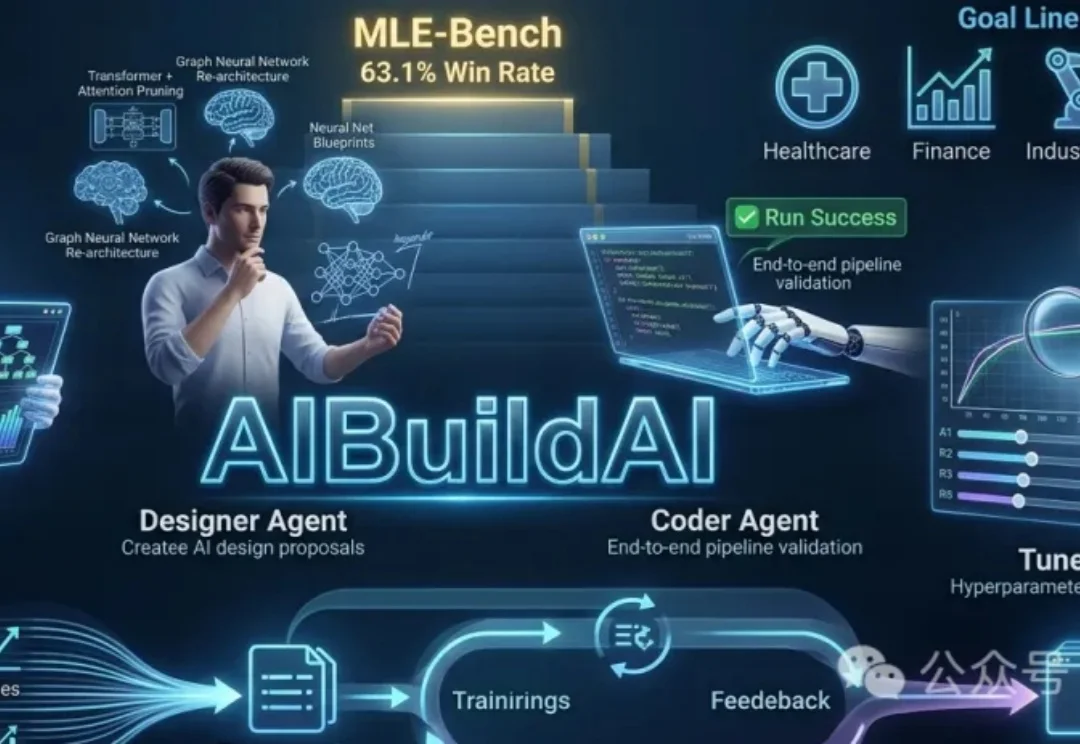
龙虾也能养龙虾!UCSD发布AIBuildAI智能体,MLE-Bench榜单第一
龙虾也能养龙虾!UCSD发布AIBuildAI智能体,MLE-Bench榜单第一UCSD团队推出AIBuildAI智能体,无需编程,仅用自然语言描述任务,即可自动设计、编码、训练、调参并优化AI模型,分工协作,端到端完成AI开发。在OpenAI MLE-Bench测试中,AIBuildAI以63.1%的获奖率位居第一,性能媲美人类专家,推动AI开发迈向全自动化新时代。
来自主题: AI技术研报
7674 点击 2026-03-24 10:00