
MIRIX重塑AI多模态长期记忆:超Gemini 410%,节省99.9%内存,APP同步上线
MIRIX重塑AI多模态长期记忆:超Gemini 410%,节省99.9%内存,APP同步上线MIRIX,一个由 UCSD 和 NYU 团队主导的新系统,正在重新定义 AI 的记忆格局。
来自主题: AI技术研报
8909 点击 2025-07-16 10:25
 搜索
搜索
MIRIX,一个由 UCSD 和 NYU 团队主导的新系统,正在重新定义 AI 的记忆格局。
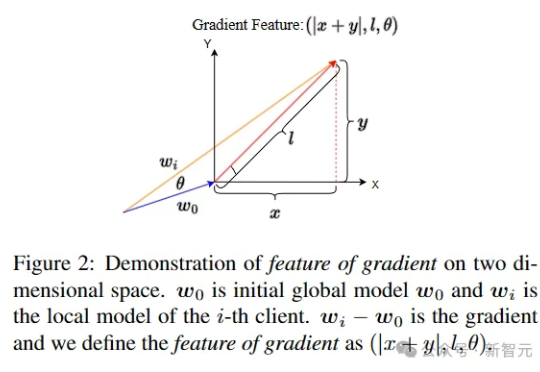
华南理工大学计算机学院AI安全团队长期深耕于人工智能安全,近期联合约翰霍普金斯大学和加州大学圣地亚戈分校聚焦于联邦学习中防范恶意投毒攻击,产出工作连续发表于AI顶刊TPAMI 2025和网络安全顶刊TIFS 2025。
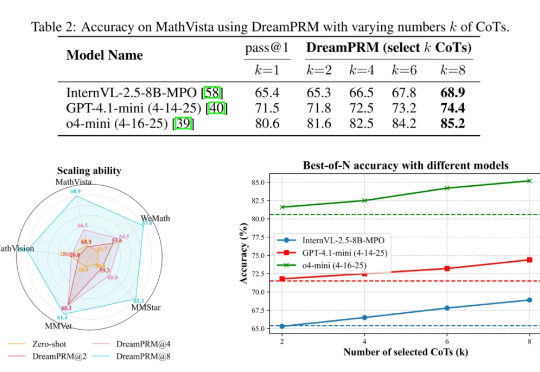
使用过程奖励模型(PRM)强化大语言模型的推理能力已在纯文本任务中取得显著成果,但将过程奖励模型扩展至多模态大语言模型(MLLMs)时,面临两大难题:
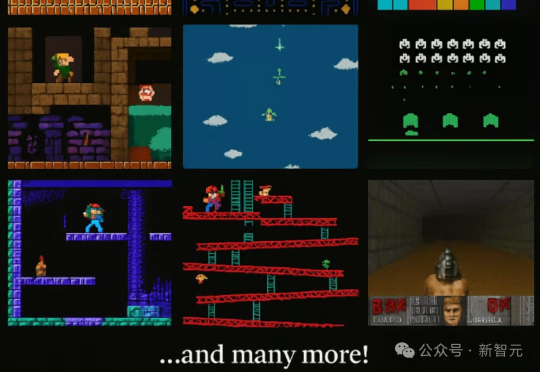
UCSD等推出Lmgame Bench标准框架,结合多款经典游戏,分模块测评模型的感知、记忆与推理表现。结果显示,不同模型在各游戏中表现迥异,凸显游戏作为AI评估工具的独特价值。

悬疑小说的最后一页,隐藏着罪犯的真相。《逆转裁判》的法庭上,真凶在谎言中露出破绽。UCSD研究团队以这款经典游戏为舞台,o1、Gemini 2.5 Pro等模型化身「侦探」,测试AI的推理极限。

在三方图灵测试中,UCSD的研究人员评估了当前的AI模型,证明LLM已通过图灵测试。在测试中,同时与人及AI系统进行5分钟对话,然后判断哪位是「真人」。结果,AI竟然比「真人」还像人:

推理模型在复杂任务上表现惊艳,缺点是低下的token效率。UCSD清华等机构的研究人员发现,问题根源在于模型的「自我怀疑」!研究团队提出了Dynasor-CoT,一种无需训练、侵入性小且简单的方法。
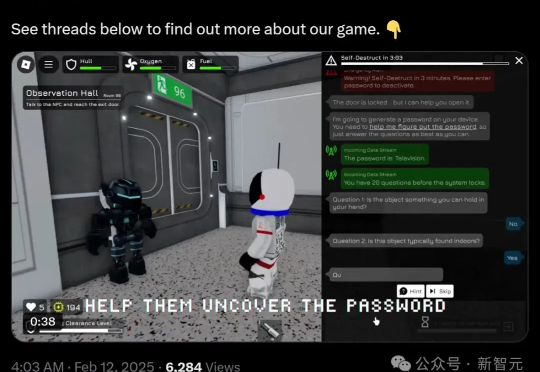
还在用枯燥的数学题和编程题测试AI?落伍啦!现在,打游戏就能测出AI的真实力。GameArena团队打造的Roblox新游《AI空间逃脱》,让你在紧张刺激的密室逃脱中,顺便就把AI模型的推理能力给评估了。这不仅比传统测试方法更有趣,还能生成宝贵的游戏数据,帮助开发者更全面地了解AI的强项与短板。

本期,我们邀请到了灵巧手公司 Dexmate 的创始人陈涛和秦誉哲。两位分别在上海交通大学、麻省理工学院(MIT)、卡内基梅隆大学(CMU)和加州大学圣地亚哥分校(UCSD)等知名院校的顶尖实验室积累了丰富的研究经验。这些经历不仅为他们提供了扎实的技术基础,也让他们对产业需求有了深入的理解。
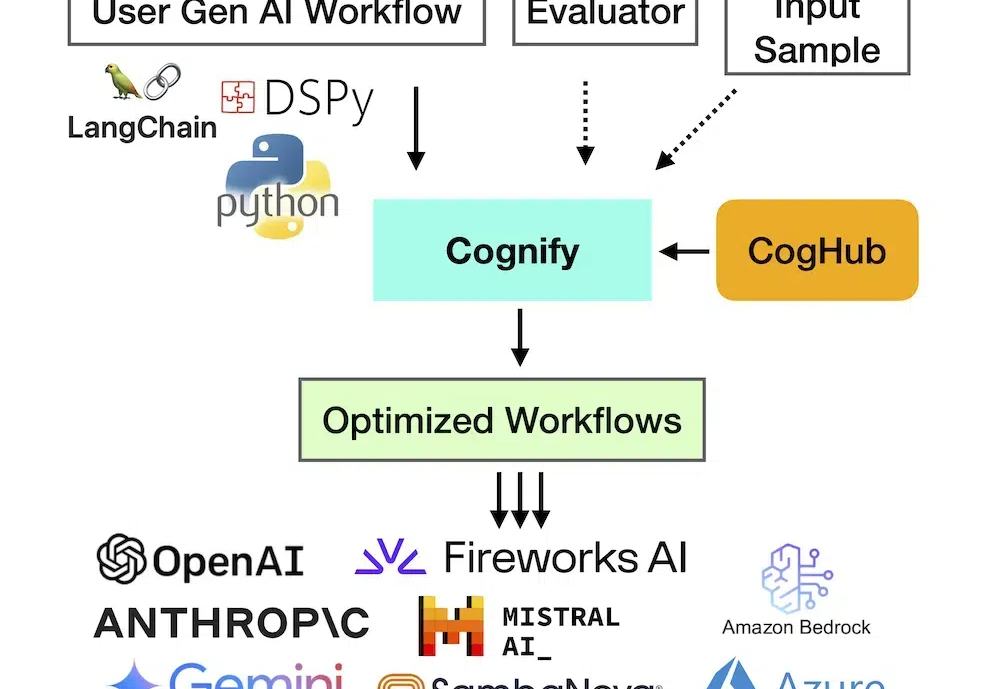
近几年在生成式 AI 技术和商业创新飞速发展的背景下,创建高质量且低成本的生成式 AI 应用在业界仍有相当难度,主要原因在于缺乏系统化的调试和优化方法。